机器之心 & ArXiv Weekly Radiostation
本周论文包括谷歌放出下一代 AI 架构 Pathways 论文;何恺明组最新论文等研究。
Training-free Transformer Architecture Search
PATHWAYS: ASYNCHRONOUS DISTRIBUTED DATAFLOW FOR ML
Autoregressive Image Generation using Residual Quantization
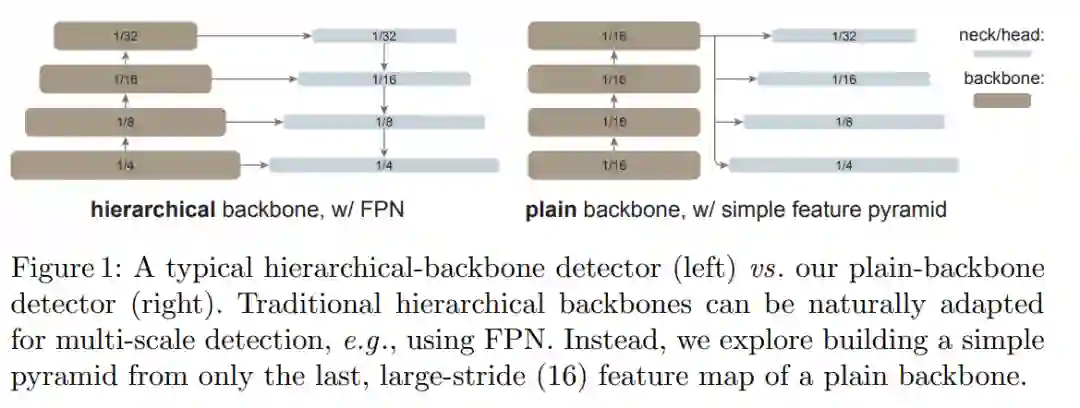
Exploring Plain Vision Transformer Backbones for Object Detection
FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
LANGUAGE MODELING VIA STOCHASTIC PROCESSES
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Training-free Transformer Architecture Search
摘要:
在近期的一篇论文《Training-free Transformer Architecture Search》中,来自腾讯优图实验室、厦门大学、鹏城实验室等结构的研究者回顾近些年 NAS 领域的进展,并注意到:为了提高搜索效率,研究社区提出了若干零成本代理(zero-cost proxy)的评估指标(如 GraSP、TE-score 和 NASWOT)。这些方法让我们能够在无需训练的条件下就能评估出不同 CNN 结构的排序关系,从而极大程度上节省计算成本。
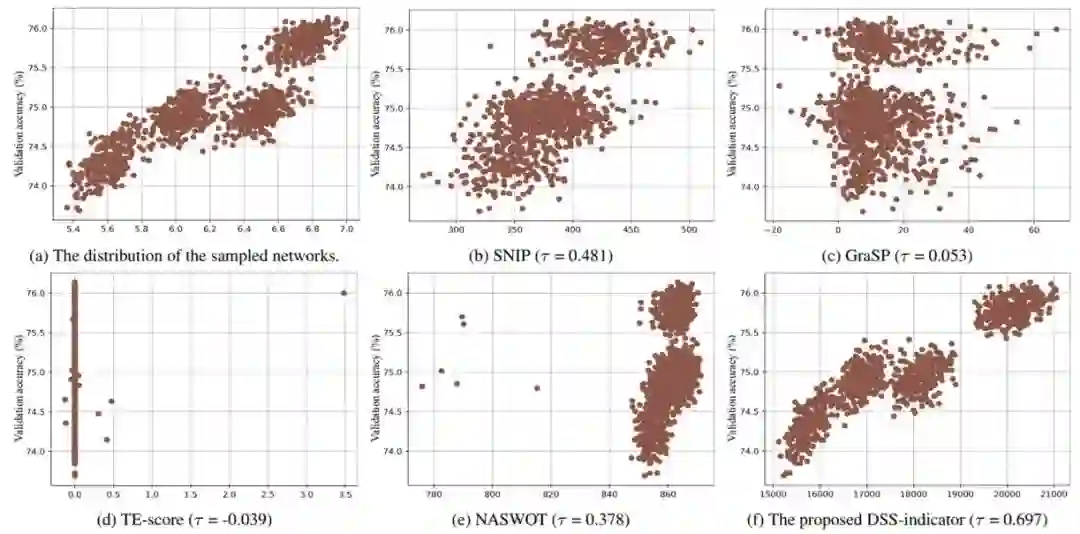
从技术上来说,一个典型的 CNN 模型主要由卷积模块组成,而一个 ViT 模型主要由多头注意力模块(MSA)和多层感知机模块(MLP)组成。这种网络结构上的差异会让现有的、在 CNN 搜索空间上验证有效的零成本代理无法保证其在 ViT 搜索空间上模型评估效果(见下图 1)。
因此,研究一种更适合 ViT 结构评估、有利于 TAS 训练效率的零成本代理指标是有必要且值得探索的。这一问题也将促使研究者进一步研究和更好地理解 ViT 结构,从而设计一种有效的、无需训练的 TAS 搜索算法。
图 1. (a)研究者采样的 1000 个 ViT 模型的参数量和效果分布。(b-e)在 CNN 搜索空间效果好的 zero-cost proxy 方法并不适用于 ViT 搜索空间。(f)他们的 DSS-indicator 更适合用来评估不同的 ViT 模型。
研究者设计了一个有效且高效的零代价代理评估指标 DSS-indicator(下图 2),并基于此设计了一个包含模块化策略的无训练 Transformer 结构搜索算法(Transformer Architecture Search,TF-TAS)。
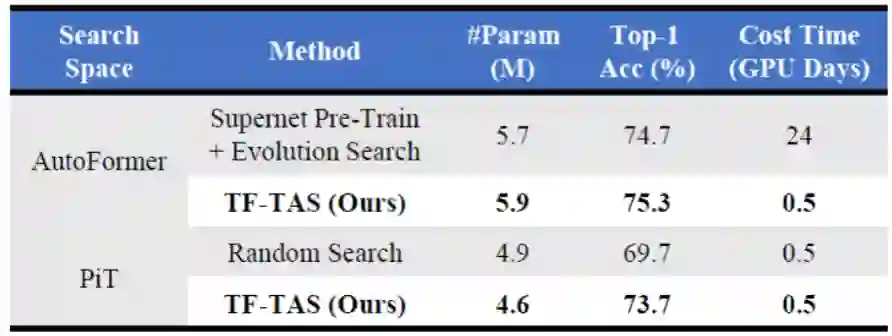
具体来说,DSS-indicator 通过计算 MSA 的突触多样性和 MLP 的突触显著性来得到 ViT 结构的评价分数。这是学术界首次提出基于 MSA 的突触多样性和 MLP 的突触显著性来作为评价 ViT 结构的代理评估指标。而且需要注意的是,TF-TAS 与搜索空间设计和权值共享策略是正交的。因此,可以灵活地将 TF-TAS 与其他 ViT 搜索空间或 TAS 方法相结合,进一步提高搜索效率。与人工设计的 ViT 和自动搜索的 ViT 相比,研究者设计的 TF-TAS 实现了具有竞争力的效果,将搜索过程从 24 GPU 天数缩短到不到 0.5 GPU 天数,大约快 48 倍。
推荐:
CVPR 2022 Oral ,腾讯优图 & 厦门大学提出无需训练的 ViT 结构搜索算法。
论文 2:PATHWAYS: ASYNCHRONOUS DISTRIBUTED DATAFLOW FOR ML
摘要:
Jeff Dean 等人去年提出了一种名叫「Pathways」的通用 AI 架构。他介绍说,Pathways 旨在用一个架构同时处理多项任务,并且拥有快速学习新任务、更好地理解世界的能力。
在发布想法大半年之后,Jeff Dean 终于公布了 Pathways 的论文,其中包含很多技术细节。
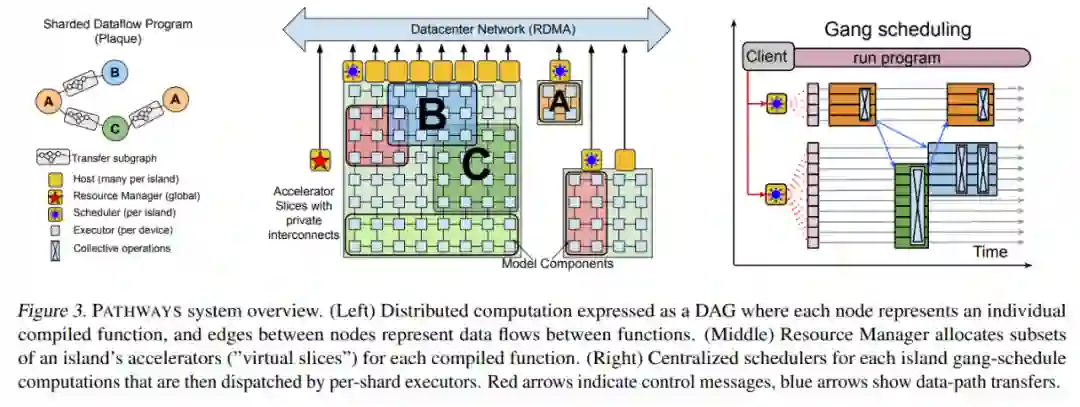
论文写道,PATHWAYS 使用了异步算子的一个分片数据流图(sharded dataflow graph),这些算子消耗并产生 futures,并在数千个加速器上高效地对异构并行计算进行 gang-schedule,同时在它们专用的 interconnect 上协调数据传输。PATHWAYS 使用了一种新的异步分布式数据流设计,它允许控制平面并行执行,尽管数据平面中存在依赖关系。这种设计允许 PATHWAYS 采用单控制器模型,从而更容易表达复杂的新并行模式。
实验结果表明,当在 2048 个 TPU 上运行 SPMD(single program multiple data)计算时,PATHWAYS 的性能(加速器利用率接近 100%)可以媲美 SOTA 系统,同时吞吐量可媲美跨越 16 个 stage 或者被分割成两个通过数据中心网络连接的加速器岛的 Transformer 模型的 SPMD 案例。
PATHWAYS 构建在先前的系统的基础上,包括用于表征和执行 TPU 计算的 XLA (TensorFlow, 2019)、用于表征和执行分布式 CPU 计算的 TensorFlow 图和执行器 (Abadi et al., 2016),以及包括 JAX (Bradbury et al., 2016) 在内的 Python 编程框架 (Bradbury et al., 2018) 和 TensorFlow API。利用这些构建块,PATHWAYS 在兼顾协调性的同时,仅用最少的代码更改就能运行现有的 ML 模型。
推荐:
谷歌下一代 AI 架构 Pathways 论文解读。
论文 3:Autoregressive Image Generation using Residual Quantization
摘要:
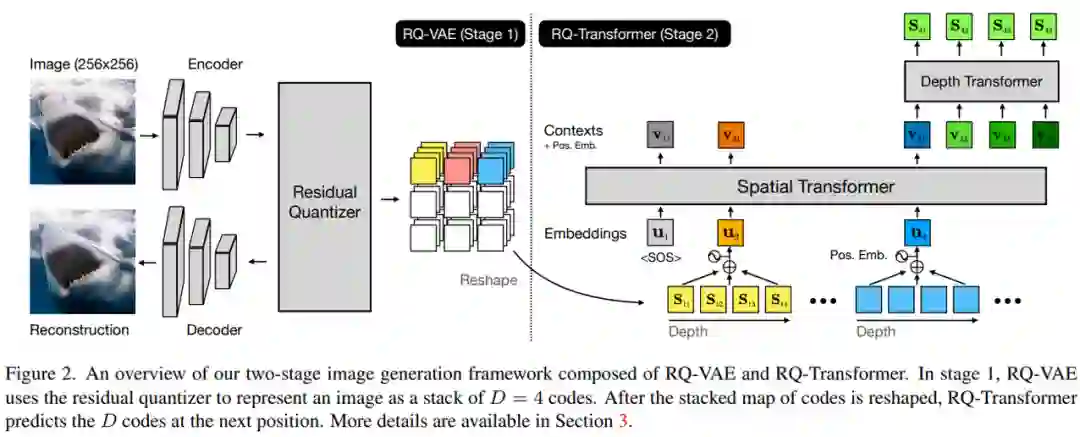
来自 Kakao Brain 、韩国浦项科技大学的研究者提出了一种残差量化 VAE (RQ-VAE) 方法,它使用残差量化 (RQ) 来精确逼近特征图并降低其空间分辨率。RQ 没有增加编码簿大小,而是使用固定大小的编码簿以从粗到细的方式递归量化特征图。在 RQ 的 D 次迭代之后,特征图表示为 D 个离散编码的堆叠图。由于 RQ 可以组成与编码簿大小一样多的向量,因此 RQ-VAE 可以精确地逼近特征图,同时保留编码图像的信息,而无需庞大的编码簿。由于精确的近似,RQ-VAE 可以比以前的研究 [14,37,45] 进一步降低量化特征图的空间分辨率。例如, RQ-VAE 可以使用 8×8 分辨率的特征图对 256×256 图像进行 AR 建模。该论文已被 CVPR'22 接收。
此外,该研究还提出了 RQ-Transformer 来预测 RQ-VAE 提取的编码。对于 RQ-Transformer 的输入,该研究首先将 RQ-VAE 中的量化特征映射转换为特征向量序列;然后,RQ-Transformer 预测下一个 D 编码,以估计下一个位置的特征向量。由于 RQ-VAE 降低了特征图的分辨率,RQ-Transformer 可以显着降低计算成本并轻松学习输入的远程交互。该研究还为 RQ-Transformer 提出了两种训练技术,软标签(soft labeling)和用于 RQ-VAE 编码的随机采样。通过解决 AR 模型训练中的曝光偏差(exposure bias)进一步提高了 RQ-Transformer 的性能。
值得一提的是,该研究近日发布了在 30M 文本图像对上训练的 3.9B 参数的 RQ-Transformer 。据了解,这是公共可用模型中最大的文本到图像 (T2I) 模型。不过这一结果没有出现在该论文中。具体内容可参考 GitHub。
代码地址:https://github.com/kakaobrain/rq-vae-transformer
研究者提出了用于图像 AR 建模的 RQ-VAE 和 RQ-Transformer 两阶段框架,如下图 2 所示。RQ-VAE 使用编码簿将图像表示为 D 个离散码的堆叠图。然后,使用 RQ-Transformer 自回归预测下一个空间位置的下一个 D 码。他们还解释了使用 RQ-Transformer 解决 AR 模型训练中的曝光偏差问题。
推荐:
39 亿参数模型公开可用,采样速度 7 倍提升,残差量化生成图片入选 CVPR'22。
论文 4:Exploring Plain Vision Transformer Backbones for Object Detection
摘要:
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT 主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet 的研究一样。这一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移等变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔(如图 1 所示)。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力(没有 shifting)。他们使用少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练。
这种简单的设计收获了令人惊讶的结果。研究者发现,在使用普通 ViT 主干的情况下,FPN 的设计并不是必要的,它的好处可以通过由大步幅 (16)、单一尺度图构建的简单金字塔来有效地获得。他们还发现,只要信息能在少量的层中很好地跨窗口传播,窗口注意力就够用了。
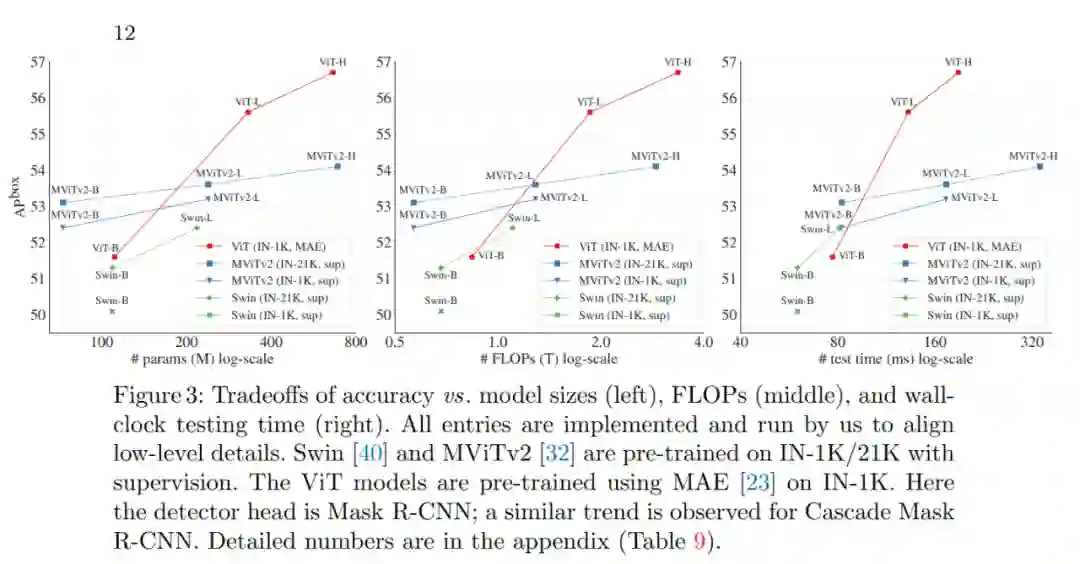
更令人惊讶的是,在某些情况下,研究者开发的名为「ViTDet」的普通主干检测器可以媲美领先的分层主干检测器(如 Swin、MViT)。通过掩蔽自编码器(MAE)预训练,他们的普通主干检测器可以优于在 ImageNet-1K/21K 上进行有监督预训练的分层检测器(如下图 3 所示)。
推荐:
何恺明组新论文:只用 ViT 做主干也可以做好目标检测。
论文 5:FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
摘要:
评价准则的差异极大阻碍了已有小样本学习方法基于统一的标准公平比较,也无法客观评价该领域的真实进展。近期,来自清华大学、DeepMind 等团队研究者在论文《FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding》中指出:现有小样本学习方法并不稳定有效,且目前已有工作不存在单一的小样本学习方法能够在大多数 NLU 任务上取得优势性能。小样本自然语言理解领域发展依然面临着严峻的挑战!该工作被 ACL2022 主会接收。
(1) 该研究提出了一个新的小样本自然语言理解评价框架 FewNLU,并且从三个关键方面 (即测试集小样本学习性能、测试集和验证集相关性、以及稳定性) 量化评估该评价准则的优势。
(2) 研究者对该领域相关工作进行重新评估,结果表明:已有工作未准确估计现有小样本学习方法的绝对性能和相对差距;目前尚不存在单一在大多数 NLU 任务取得优势性能的方法;不同方法的增益是优势互补的,最佳组合模型的性能接近于全监督 NLU 系统等关键结论。
(3) 此外本文提出 FewNLU,并构建了 Leaderboard,希望帮助促进小样本自然语言理解领域未来研究工作的发展。
本文为小样本自然语言理解提出一种更稳健且有效的评价框架,如算法 1 所示。
该评价框架中有两个关键设计选择,分别是如何构建数据拆分以及确定关键搜索超参数。
推荐:
ACL2022 | 清华大学、DeepMind 等指出现有小样本学习方法并不稳定有效,提出评价框架。
论文 6:LANGUAGE MODELING VIA STOCHASTIC PROCESSES
摘要:
在近期的一项研究中,斯坦福大学的研究者探索了一种替代方案,该替代方案明确假设了具有 goal-conditioned 生成的简单、固定动态模型。研究者提出了时间控制(Time Control),作为学习已知 goal-conditioned 动态的潜在空间的方法。他们假设非目标导向生成的 meandering 文本在潜在空间内可以表征为布朗运动,这种运动使得相邻句子的嵌入变得更为相似,相距较远的句子相异。借助固定的开始和结束节点,目标导向的行为能够合并进该模型。在这种情况下,布朗运动变为了布朗桥,由此产生的潜在轨迹遵循简单的封闭式动态。
在时间控制中,研究者推导了一个新的对比目标,用于学习一个具有布朗桥动态的潜空间。然后,利用这个潜在空间来生成保持局部连贯性并提高全局连贯性的文本。为了完成文本生成,时间控制首先通过固定在起始点和终止点的布朗桥过程规划一个潜在的轨迹。然后它有条件地使用这个潜在规划生成句子。在本文中,研究者根据时间控制的潜在轨迹,通过微调 GPT2 来解码潜在规划、生成文本。来自时间控制的轨迹作为文档中的抽象语义位置,指导生成精细调整的语言模型。
推导了时间控制语言模型,该语言模型用一种新的对比目标学习的布朗桥动态显式地模拟潜在结构。
在一系列文本域中,与针对具体任务的方法相比,时间控制能够生成更多或同样连贯的任务文本,包括文本填充和强制生成长文本。
验证了结论,潜在表征通过评估与人类实验的语篇一致性来竞争性地捕捉文本动态。
同时调整了方法,以理解对比目标的重要性,强化了布朗桥动态,并明确建立潜在动态模型。
推荐:
斯坦福 NLP 论文,入选 ICLR 2022 。
论文 7:DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery
摘要:
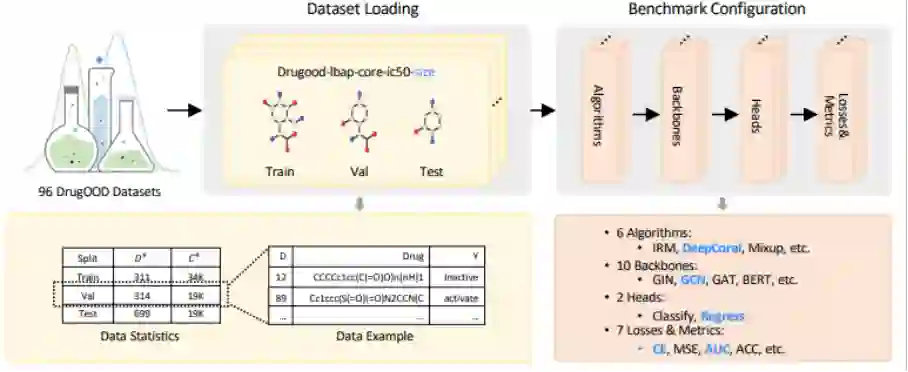
近日,腾讯 AI Lab「云深」平台发布业内首个药物 AI 大型分布外研究框架 DrugOOD,包括数据集整理器(curator)和基准测试(benchmark),以推动药化场景中的分布偏移(distribution shift) 问题研究,助力药物研发行业发展。
「云深」平台的 DrugOOD 提供了方便用户定制的数据整理流程,用户只需修改配置(config)文件中的相关参数,即可重新生成新的数据集。这些数据集可充分利用库存网站 ChEMBL 上多样且持续更新的海量数据。
针对有噪声的分布外学习场景(OOD Learning with Noise),DrugOOD 集成了 5 种域标定方法和 3 种噪声标定水平。5 种域标定方法(scaffold、assay、molecule size、protein、protein family)能够反映药物 AI 中真实的分布偏移场景;3 种噪声标定水平(core、refined、general)根据测量置信度,度量标准,截断噪声等来制定,能够锚定数据中不同的噪声水平。
根据上述自动化数据整理器,该研究生成了总计 96 个样例数据集,构建了包括 Ligand Based Affinity Prediction、Structure Based Affinity Prediction 等在不同设置(偏移因素,预测目标,噪声水平)下的评测任务,用于测试不同方法的鲁棒性能。通过基准测试发现,在 DrugOOD 上现存多种 OOD 算法的分部内 - 分布外(ID-OOD) 分类性能(AUC score)差异达到了 20% 以上,验证了此数据集中域标定和噪声标定方法的真实性和挑战性。
基于 DrugOOD 数据集,腾讯 AI Lab「云深」平台同时发布了全面的评测标准(Benchmark),比较当前各类 OOD 问题研究方法的性能,这些研究包括不同的泛化方法(ERM,IRM,DeepCoral 等),以及不同网络架构(GIN,GCN,BERT 等)。
该算法开发与测试平台已经开源:https://github.com/tencent-ailab/DrugOOD
推荐:
业内首个,腾讯 AI Lab「云深」平台开源药物 AI 大型分布外研究框架 DrugOOD。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Training Compute-Optimal Large Language Models. (from Simon Osindero, Karen Simonyan, Oriol Vinyals, Laurent Sifre)
2. LinkBERT: Pretraining Language Models with Document Links. (from Jure Leskovec)
3. Linking Emergent and Natural Languages via Corpus Transfer. (from Joshua B. Tenenbaum)
4. Non-autoregressive Translation with Dependency-Aware Decoder. (from Yang Gao)
5. Short-Term Word-Learning in a Dynamically Changing Environment. (from Alexander Waibel)
6. Data Selection Curriculum for Neural Machine Translation. (from Philipp Koehn)
7. A Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation. (from Michael Collins, Mirella Lapata)
8. Generative Spoken Dialogue Language Modeling. (from Abdelrahman Mohamed, Emmanuel Dupoux)
9. What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation. (from Yang Liu, Dilek Hakkani-Tur)
10. BRIO: Bringing Order to Abstractive Summarization. (from Dragomir Radev)
1. TubeDETR: Spatio-Temporal Video Grounding with Transformers. (from Josef Sivic, Ivan Laptev, Cordelia Schmid)
2. Exploring Plain Vision Transformer Backbones for Object Detection. (from Ross Girshick, Kaiming He)
3. Learning Program Representations for Food Images and Cooking Recipes. (from Antonio Torralba)
4. SPAct: Self-supervised Privacy Preservation for Action Recognition. (from Mubarak Shah)
5. Few-Shot Object Detection with Fully Cross-Transformer. (from Shih-Fu Chang)
6. FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations. (from Joshua B. Tenenbaum)
7. Omni-DETR: Omni-Supervised Object Detection with Transformers. (from Nuno Vasconcelos, Bernt Schiele, Stefano Soatto)
8. Constrained Few-shot Class-incremental Learning. (from Luca Benini)
9. Large-Scale Pre-training for Person Re-identification with Noisy Labels. (from Lei Zhang)
10. On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation. (from Pascal Fua)
1. Shift-Robust Node Classification via Graph Adversarial Clustering. (from Jiawei Han)
2. Improving Contrastive Learning with Model Augmentation. (from Jia Li, Philip S. Yu)
3. TransGAN: a Transductive Adversarial Model for Novelty Detection. (from John Shawe-Taylor)
4. Near-optimality for infinite-horizon restless bandits with many arms. (from Xiangyu Zhang)
5. AdaGrid: Adaptive Grid Search for Link Prediction Training Objective. (from Jure Leskovec)
6. DiffSkill: Skill Abstraction from Differentiable Physics for Deformable Object Manipulations with Tools. (from Joshua B. Tenenbaum)
7. A Simple Yet Effective Pretraining Strategy for Graph Few-shot Learning. (from Huan Liu)
8. Self-Contrastive Learning based Semi-Supervised Radio Modulation Classification. (from Tarek Abdelzaher)
9. A Manifold View of Adversarial Risk. (from Dimitris Metaxas)
10. Traffic4cast at NeurIPS 2021 - Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes. (from Yiming Yang, Sepp Hochreiter)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com