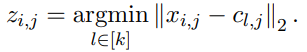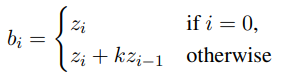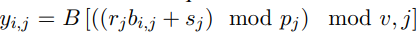©作者 | 陈萍、杜伟
来源 | 机器之心
在提交给 ACL 的一篇匿名论文中,研究者用潜在 n-gram 来增强 Transformer。
Transformer 模型已成为自然语言处理任务的基础模型之一,最近研究者开始把注意力转移到对这些模型的扩展上。然而,这些大型 Transformer 语言模型的训练和推理成本高昂,令人望而却步,因此我们需要更多变体来消除这些不利因素。
近日,一篇匿名提交给自然语言处理顶会 ACL 的论文《 N-grammer: Augmenting Transformers with latent n-grams 》中,研究者受到统计语言建模的启发,通过从文本序列的离散潜在表示构建 n-gram 来增强模型,进而对 Transformer 架构进行了一个简单而有效的修改,称为 N-grammer。
具体地,N-grammer 层通过在训练期间将潜在 n-gram 表示合并到模型中来提高语言模型的效率。由于 N-grammer 层仅在训练和推理期间涉及稀疏操作,研究者发现具有潜在 N-grammer 层的 Transformer 模型可以匹配更大的 Transformer,同时推理速度明显更快。在 C4 数据集上对语言建模的 N-grammer 进行评估表明,本文提出的方法优于 Transformer 和 Primer 等基准。
![]()
https://openreview.net/pdf?id=GxjCYmQAody
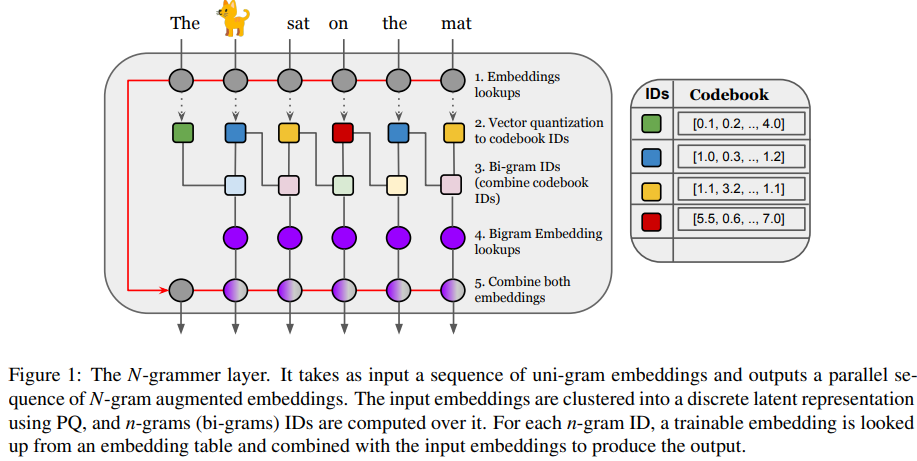
在网络高层次上,该研究引入了一个简单的层,该层基于潜在 n-gram 用更多的内存来增强 Transformer 架构。一般来说,N-grammer 层对于任意 N-gram 来说已经足够了,该研究仅限于使用 bi-gram,以后将会研究高阶 n-gram。这个简单的层由以下几个核心操作组成:
给定文本的 uni-gram 嵌入序列,通过 PQ (Product Quantization)推导出离散潜在表示序列;
推导潜在序列 bi-gram 表示;
通过哈希到 bi-gram 词汇表中查找可训练的 bi-gram 嵌入;
将 bi-gram 嵌入与输入 uni-gram 嵌入相结合。
此外,当提到一组离散项时,该研究使用符号 [m] 表示集合{0,1,···,m−1}。
![]()
第一步,N-grammer 层从给定的输入嵌入序列学习 Codebook,获得具有乘积量化(Product Quantization,PQ)(Jegou 等人,2011 年)的离散潜在表示的并行序列。输入嵌入是一个 uni-gram 嵌入序列 x ϵ R^( l×h×d ),其中 l 是序列长度,h 是头数量,d 是每个头嵌入维度。该研究在 R^ k×h×d 中学习了一个 Codebook c,通过相同的步骤,该研究选取距离输入嵌入最小的 code book ID,形成序列 x 的离散潜在表示 z ϵ[k]^l×h 的并行序列:
![]()
第二步是将离散潜在表示 z 转换为 bi-gram ID b ϵ [k^2 ]^( l×h )。它们通过组合来自前一个位置的 uni-gram 潜在 ID z,然后在当前位置形成潜在 bi-gram ID:
![]()
其中 k 是 codebook 大小,这直接将离散潜在序列从词汇空间[k] 映射到潜在 bi-gram 词汇空间 [k^2 ] 。
第三步是构建序列 bi-gram 潜在表示 b。考虑所有的 k^2 bi-gram,并通过对每个这样的 bi-gram 嵌入来增强模型。在实践中,对于 uni-gram 词汇为 32,000 的机器翻译模型压缩,在不牺牲质量的情况下,需要将 187 个 token 聚类为 k = 212 个 cluster。在这种情况下,需要考虑所有的 bi-gram,涉及构建一个包含 1600 万行的嵌入表。由于所构建的表仍然很大,该研究通过对每个头使用单独的哈希函数,将潜在 bi-gram ID 映射到大小为 v 的较小的 bi-gram 词汇表。
更准确地讲,该研究有一个潜在 bi-gram 嵌入表 B ϵ R^v×h×d_b,其中 v 为 bi- gram 词汇,d_b 为 bi-gram 嵌入维度。然后将文本序列 bi-gram 嵌入构建为:
![]()
最后一步是将 uni-gram 嵌入 x ϵ R^(l×h×d)与潜在 bi-gram 嵌入 y∈R^(l×h×db)相结合,形成文本序列新表示。bi-gram 嵌入和 uni-gram 嵌入都是独立的层归一化(LN),然后沿着嵌入维度连接两者以产生 w = [LN(x), LN(y)] ϵ R^l×h×(d+db) ,并将其作为输入传递给 Transformer 网络的其余部分。
该研究在 C4 数据集上将 N-grammer 模型与 Transformer 架构(Vaswani 等人,2017 年)以及最近提出的 Primer 架构(So 等人,2021 年)进行了比较。其中,该研究使用 Adam 优化器,所有模型的学习率为 10^-3,而对于 n-gram 嵌入表,学习率为 10^-2。
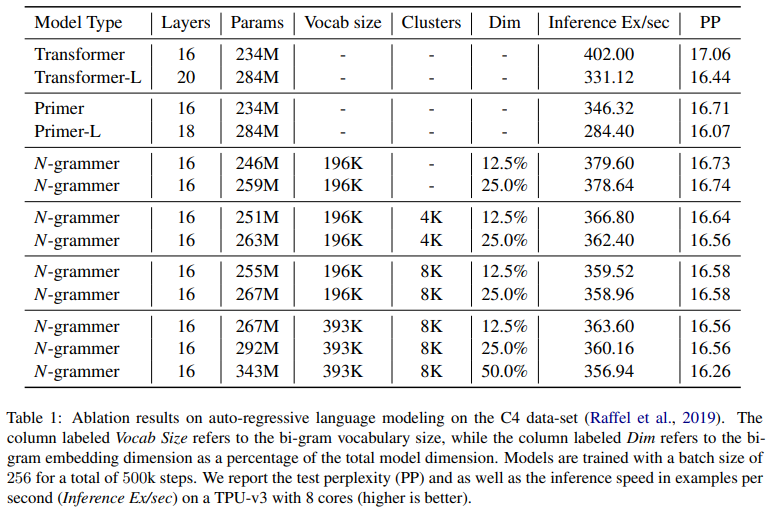
下表 1 比较了 N-grammer、Primer 和 Transformer 模型,其中基线 Transformer 模型有 16 层和 8 个头,模型维度为 1024。研究者在 TPU v3 上以 256 的批大小和 1024 的序列长度训练所有模型。研究者对 N-grammer 模型进行了消融研究,bi-gram 嵌入维度大小从 128 到 512 不等。由于添加 n-gram 嵌入增加了可训练参数的数量,该研究还在表 1 中训练了两个大基线(Transformer-L 和 Primer-L),它们的参数顺序与 N-grammer 模型相同。然而,与较大的 Transformer 模型不同,N-grammer 的训练和推理成本与嵌入层中的参数数量不成比例,因为它们依赖于稀疏操作。
该研究还测试了一个简单版本的 N-grammer,研究者直接从 uni-gram 词汇表(3.3 节中的)而不是从潜在表示中计算 n-gram(3.1 节的)。由表 1 可知,它对应于在 clusters 列中没有条目的 N- grammer。
![]()
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()