机器之心 & ArXiv Weekly Radiostation
本周论文包括 DeepMind 提出的 Gopher:2800 亿参数,接近人类阅读理解能力;强化学习大牛 Sergey Levine:将 RL 作为可扩展自监督学习的基础等研究。
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Improving language models by retrieving from trillions of tokens
Probing topological spin liquids on a programmable quantum simulator
Understanding the World Through Action
Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
PolyViT: Co-training Vision Transformers on Images, Videos and Audio
Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Scaling Language Models: Methods, Analysis & Insights from Training Gopher
作者:Jack W. Rae, Sebastian Borgeaud, Trevor Cai 等
论文地址:https://storage.googleapis.com/deepmind-media/research/language-research/Training%20Gopher.pdf
摘要:
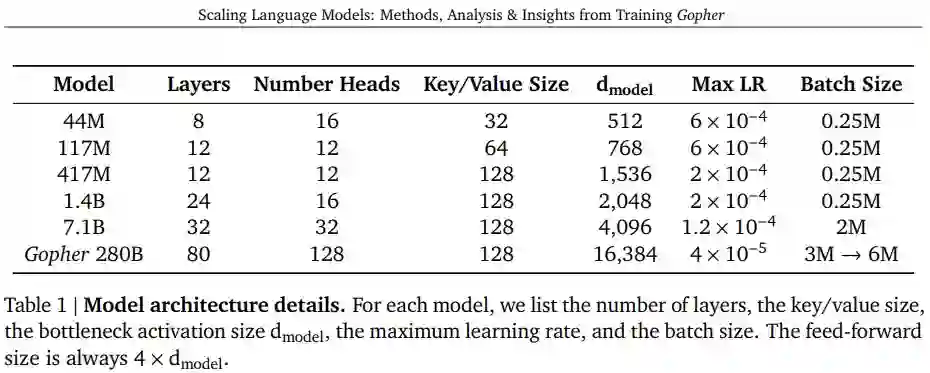
DeepMind 用一篇 118 页的论文介绍了全新的语言模型 Gopher 及其 Gopher 家族。在探索语言模型和开发新模型的过程中,DeepMind 探索了 6 个不同大小的 Transformer 语言模型,参数量从 4400 万到 2800 亿不等,架构细节如表 1 所示。其中参数量最大的模型被命名为 Gopher,具有 2800 亿参数,他们并将整个模型集称为 Gopher 家族。这些模型在 152 项不同的任务上进行了评估,在大多数情况下实现了 SOTA 性能。此外,DeepMind 还提供了对训练数据集和模型行为的整体分析,涵盖了模型规模与偏差等。最后,DeepMind 讨论了语言模型在 AI 安全和减轻下游危害方面的应用。
![]()
DeepMind 采用自回归 Transformer 架构为基础,并进行了两处修改:将 LayerNorm 替换为 RMSNorm ;使用相对位置编码而不是绝对位置编码。此外 DeepMind 使用拥有 32000 个词汇量的 SentencePiece 对文本进行 token 化,并使用字节级 backoff 来支持开放词汇模型。
DeepMind 使用 Adam 优化器,所有模型的训练共有 3000 亿个 token,采用 2048token 上下文窗口方法。在训练的前 1500 step 中,学习率从 10^−7 增加到最大,之后采用 cosine schedule 再将学习率衰减到 1/10。随着模型尺寸的增加,研究者会相应的降低最大学习率并增加每 batch 中的 token 数量,如表 1 所示。DeepMind 结合了 bfloat16 数字格式来减少内存并增加训练吞吐量。小于 7.1B 的模型使用混合精度 float32 参数和 bfloat16 激活进行训练,而 7.1B 和 280B 使用 bfloat16 激活和参数。
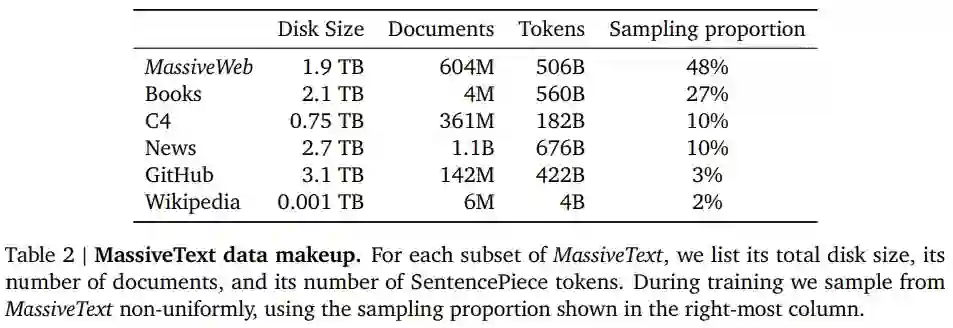
DeepMind 在 MassiveText 上训练 Gopher 模型家族,MassiveText 包括网页、书籍、新闻和代码等文本,包含约 23.5 亿个文档, 10.5 TB 的文本量。表 2 详细列出了该数据集。
![]()
推荐:
Gopher:2800 亿参数,接近人类阅读理解能力。
论文 2:Improving language models by retrieving from trillions of tokens
作者:Sebastian Borgeaud, Arthur Mensch , Jordan Hoffmann 等
论文地址:https://storage.googleapis.com/deepmind-media/research/language-research/Improving%20language%20models%20by%20retrieving.pdf
摘要:
DeepMind 在 Gopher 的基础上,提出了一种改进的语言模型架构。该架构降低了训练的资源成本,并使模型输出更容易追踪到训练语料库中的来源。
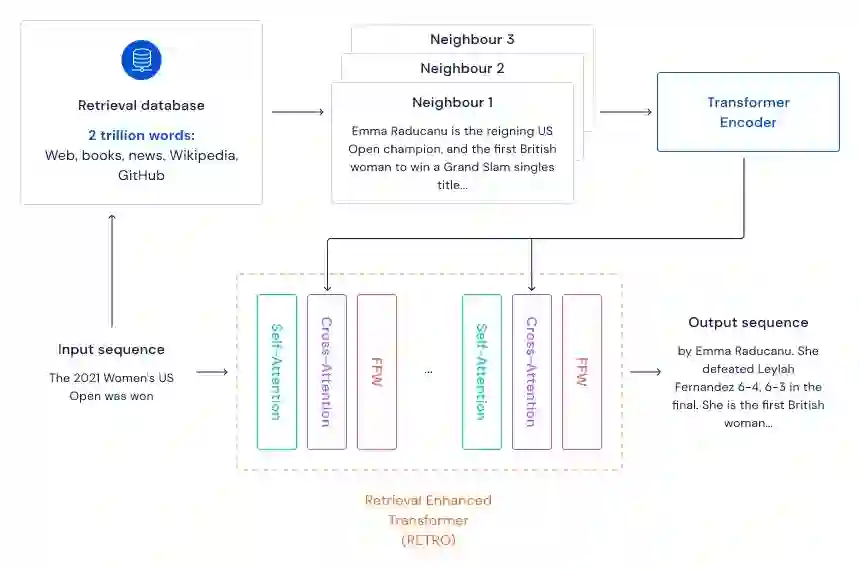
具体而言,该研究提出了一种检索增强的自回归语言模型 Retrieval-Enhanced Transformer (RETRO) ,使用互联网规模的检索机制进行预训练。受大脑在学习时依赖专用记忆机制的启发,RETRO 能够有效地查询文本段落以改进其预测。通过将生成的文本与 RETRO 生成所依赖的段落进行比较,可以解释模型做出某些预测的原因以及它们的来源。此外,研究者还发现该模型能够获得与常规 Transformer 相当的性能,参数少一个数量级,并在多个语言建模基准上获得 SOTA 性能。
![]()
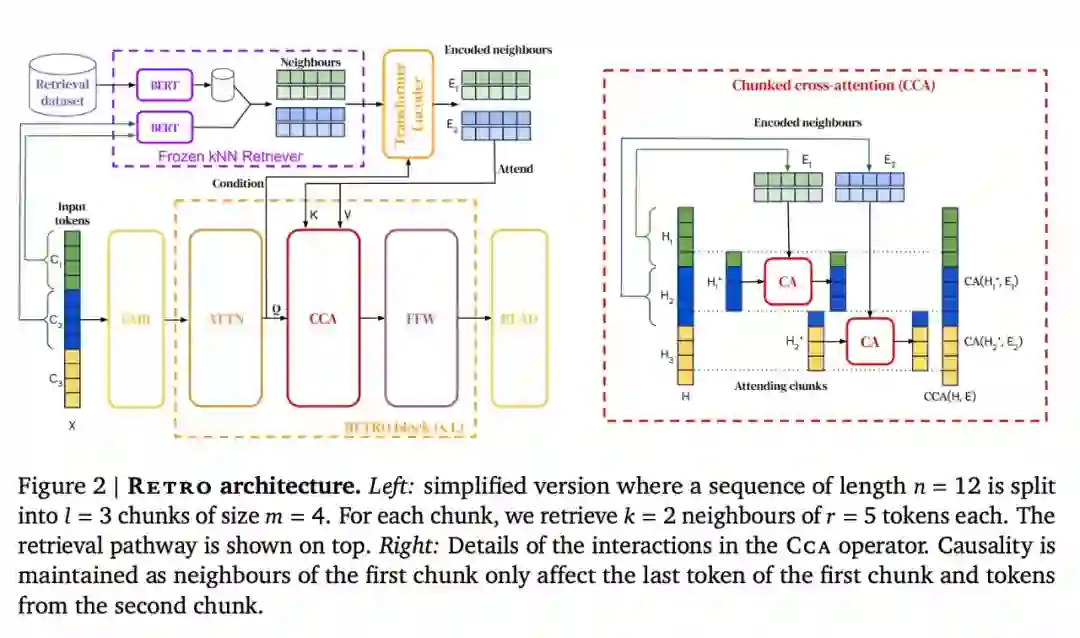
该研究设计的检索增强架构能够从具有数万亿个 token 的数据库中检索。为此,该方法对连续 token 块(chunk)进行检索,而非单个 token,这样借助线性因子减少了存储和计算需求。该方法首先构建了一个键值对(key-value)数据库,其中值存储原始文本 token 块,键是 frozen Bert 嵌入(Devlin et al., 2019)。通过使用 frozen 模型来避免在训练期间定期重新计算整个数据库的嵌入。然后将每个训练序列分成多个块,这些块通过从数据库中检索到的 K 最近邻进行扩充。编码器 - 解码器架构将检索块集成到模型的预测中,RETRO 的架构如下图所示。
![]()
推荐:
RETRO:带有互联网规模检索的高效训练。
论文 3:Probing topological spin liquids on a programmable quantum simulator
摘要:
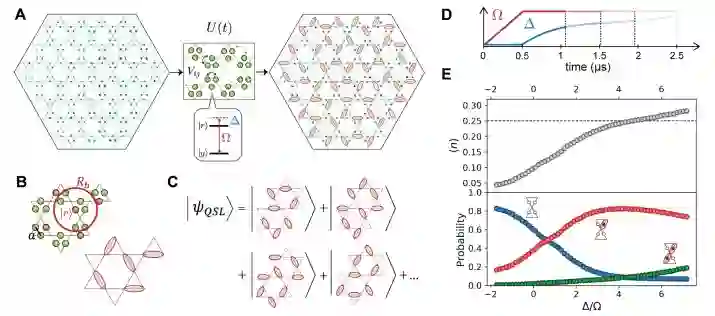
近日,剑桥研究小组公布了他们迄今为止最重要的发现,该小组包括来自哈佛大学 Lukin 领导的团队、Greiner 领导的实验室、MIT Vladan Vuletić领导的研究小组组成。他们使用量子模拟器检测到一种难以捉摸的物质状态:量子自旋液体,它存在于概述物质组织方式的百年范式之外。目前该研究登上《Science》。
量子自旋液体是具有拓扑顺序的奇异物质相,在过去的几十年里一直是物理学的主要焦点。这种相具有长程量子纠缠特性,有可能被用来实现稳健的量子计算。该研究使用具有 219 个原子的可编程量子模拟器来探测量子自旋液体。在此研究中,原子阵列被放置在 Kagome 晶格的链上,并且在里德堡 blockade 下的演变创造了没有局部秩序的受挫量子态。该研究为拓扑物质的可控实验探索和保护量子信息处理提供了可能。
该研究证实了一个有近 50 年历史、预测了这种奇异状态的理论,这也标志着朝着构建真正有用的通用量子计算机的梦想迈进了一步。
这项研究使用了一种基于中性原子的新型量子计算方法。尽管该方法落后于超导电路等更流行的量子计算技术,但中性原子具有的特殊性质长期以来一直吸引着量子工程师。
凝聚态物理学家使用自然界中发现的晶体及其在实验室中生长的物质来研究这些相。中性原子研究人员可以灵活地「编程」他们的物质,通过操纵里德堡态将原子精确地定位到任何形状的晶格中并设计原子相互作用。
![]()
推荐:
时隔近 50 年,剑桥团队首次检测到量子自旋液体,研究登上《Science》。
论文 4:Understanding the World Through Action
摘要:
强化学习大牛、UC 伯克利电气工程与计算机科学助理教授 Sergey Levine 认为利用强化学习可以衍生出一个通用的、有原则的、功能强大的框架来利用未标记数据,使用通用的无监督或自监督强化学习目标,配合离线强化学习方法,可以利用大型数据集。此外,该研究还讨论了这样的过程如何与潜在的下游任务更紧密地结合起来,以及它如何基于近年来开发的现有技术实现的。
该研究认为利用强化学习可以衍生出一个通用的、有原则的、功能强大的框架来利用未标记数据,使用通用的无监督或自监督强化学习目标,配合离线强化学习方法,可以利用大型数据集。此外,该研究还讨论了这样的过程如何与潜在的下游任务更紧密地结合起来,以及它如何基于近年来开发的现有技术实现的。
通过行动进行学习:研究者必须开发强化学习算法,以有效利用以前收集的数据集,其中离线强化学习算法提供了在多样性数据集上训练 RL 系统的途径,其方式与监督学习大致相同,然后进行一定量的主动在线微调以获得最佳性能 。
![]()
离线强化学习:离线 RL 也 可以应用自监督或无监督 RL 方法,并且此类方法能够作为将大型多样化数据集纳入自监督 RL 中的最强大的工具之一。这对于使其成为真正可行且通用的大规模表示学习工具至关重要。但是,离线 RL 提出了很多挑战,其中最重要的是需要它回答反事实问题:给定显示出结果的数据,我们是否可以预测在采取不同的行动时会发生什么?这非常具有挑战性。尽管如此,对离线 RL 的理解在过去几年取得了重大进展。除了了解分布转移如何影响离线 RL 之外,离线 RL 算法的性能也得到了显著提升。领域内开发出的一些新算法能够提供稳健性保证、离线预训练后的在线微调,以及解决了离线 RL 设置中的一系列其他问题。
![]()
使用离线 RL 训练的自监督真实世界机器人操作系统 Actionable Models,执行各种目标达成任务。该系统也可以作为通用预训练,以加速通过传统奖励在下游任务上的获取。
推荐:
强化学习大牛 Sergey Levine:将 RL 作为可扩展自监督学习的基础。
论文 5:Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
摘要:
在一篇 NeurIPS 2021 论文中,来自哈佛大学、麻省理工学院的研究人员提出了一种新方法,使从图像中表征 3D 场景比已有模型约快 15000 倍。
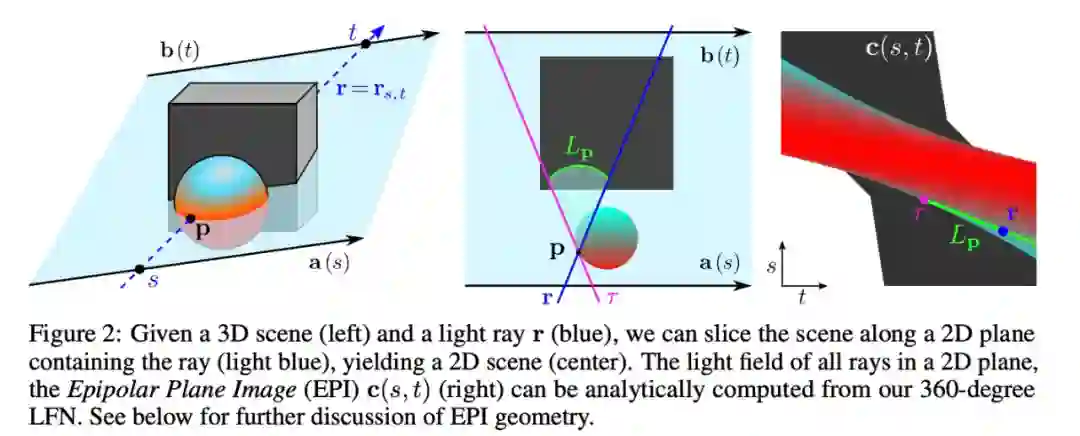
研究提出的 LFN 方法能够学习表征 3D 场景的光场,然后将光场中的每条相机光线直接映射到该光线观察到的颜色。LFN 利用光场的独特属性,只需一次评估即可渲染光线,因此 LFN 无需沿着光线的长度来运行计算。
LFN 使用其「Plücker 坐标」对每条相机光线进行分类,该坐标能够基于方向和距离原点的距离表征 3D 空间中的一条线。系统会在光线照射像素的点处,计算每条相机光线的 Plücker 坐标。
通过使用 Plücker 坐标映射每条光线,LFN 还能够计算由于视差效应而产生的场景几何形状。视差是指从两条不同的视线观看时物体的表观位置差异。例如,如果您移动头部,距离较远的物体似乎比较近的物体移动得少。基于视差,LFN 可以判断场景中物体的深度,并使用此信息对场景的几何形状及其外观进行编码。
光场有一个内在的几何形状,这正是该模型试图学习的。尽管汽车和椅子的光场似乎是不同的,以至于模型无法了解它们之间的某些共性。但事实证明,如果添加更多种类的物体,只要有一些同质性,模型就会越来越了解一般物体的光场的外观,因此你可以对更多类进行泛化。
一旦模型学习了光场的结构,它就可以仅将一张图像作为输入来渲染 3D 场景。
![]()
研究人员通过重建几个简单场景的 360 度光场来测试他们的模型。他们发现 LFN 能够以每秒 500 多帧的速度渲染场景,比其他方法快了大约 3 个数量级。此外,LFN 渲染的 3D 对象通常比其他模型生成的对象更清晰。
LFN 的内存密集程度也较低,仅需要大约 1.6 兆字节的存储空间,而基线方法则需要 146 兆字节的存储空间。
推荐:
MIT、哈佛新研究,借助光场实现 3D 场景超高速渲染。
论文 6:PolyViT: Co-training Vision Transformers on Images, Videos and Audio
摘要:
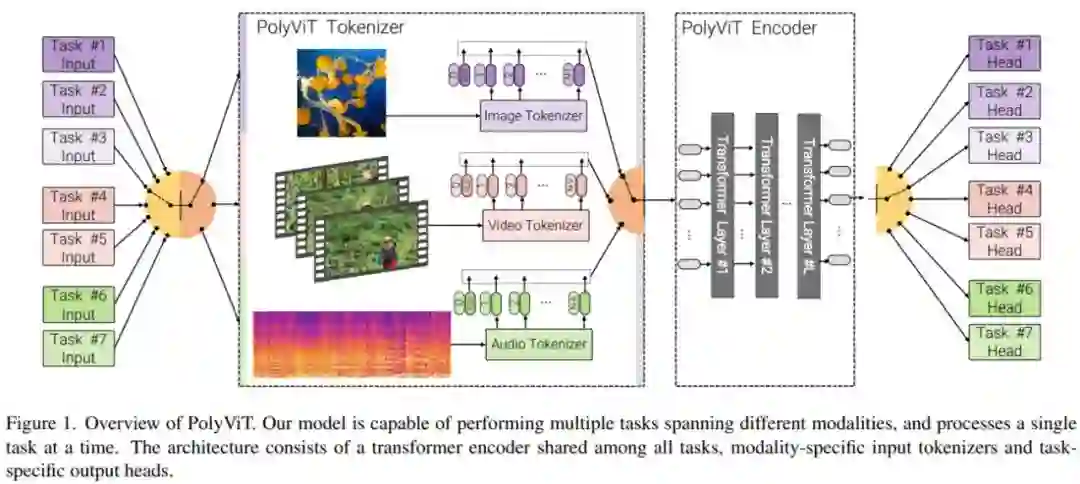
近日,谷歌研究院、剑桥大学和阿兰 · 图灵研究所的几位研究者在其论文《 PolyViT: Co-training Vision Transformers on Images, Videos and Audio 》提出了一种简单高效的训练单个统一模型的方法,他们将该模型命名为 PolyViT,它实现了有竞争力或 SOTA 的图像、视频和音频分类结果。
在设计上,研究者不仅为不同的模态使用一个通用架构,还在不同的任务和模态中共享模型参数,从而实现了潜在协同作用。从技术上来讲,他们的方法受到了「transformer 是能够在任何可以 tokenized 的模态上运行的通用架构」这一事实的启发;从直觉上来讲,是由于人类感知在本质上是多模态的,并由单个大脑执行。
![]()
研究者主要使用的方法是协同训练(co-training),即同时在多个分类任务(可能跨多个模态)上训练单个模型。
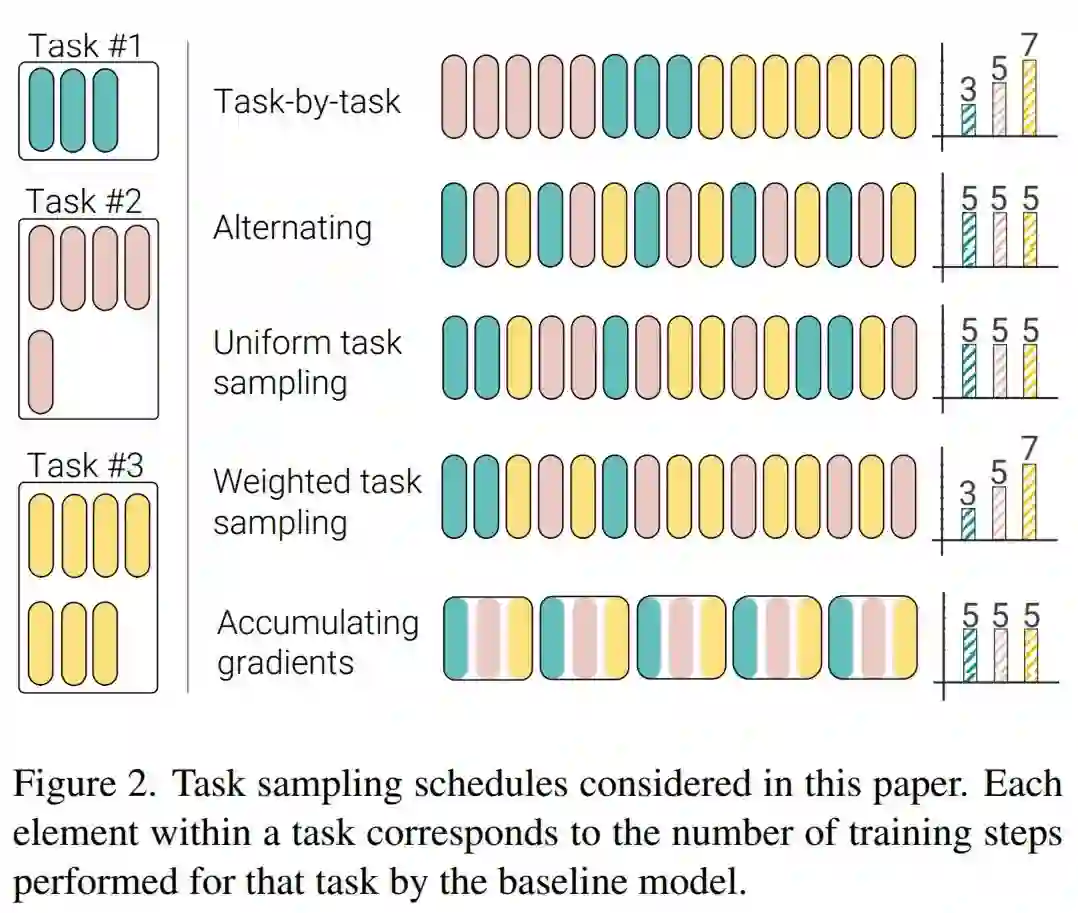
在协同训练过程中,对于每个 SGD 步,研究者采样一个任务(或数据集),然后采样来自这个任务中的 minibatch,评估梯度并随后执行参数更新。需要着重考虑的是采样任务的顺序以及是否在不同的 minibatch 和任务上累积梯度。研究者在下图 2 中描述了几个任务采样计划,包括如下:
任务 3:统一任务采样(Uniform task sampling)
任务 4:加权任务采样(Weighted task sampling)
任务 5:累积梯度(Accumulating gradients)
![]()
推荐:
单一 ViT 模型执行多模态多任务,谷歌用协同训练策略实现多个 SOTA。
论文 7:Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks
摘要:
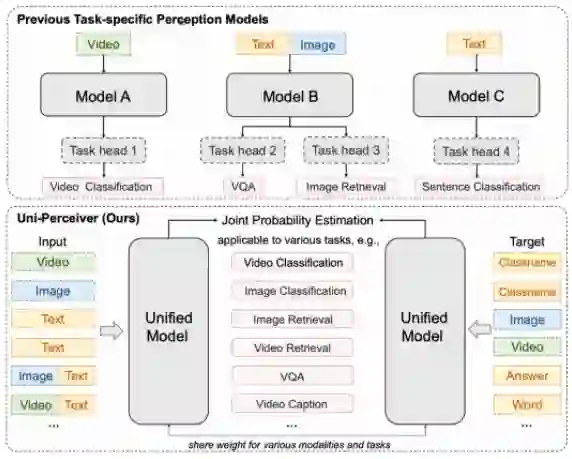
来自商汤、西安交通大学等机构的研究者们提出了 Uni-Perceiver 。图 1 对比了 Uni-Perceiver 和现有的为特定任务设计和训练的模型。Uni-Perceiver 以统一的模型处理各种模态和任务,在各种单模态任务以及多模态任务上进行了预训练。在下游任务上,由于对不同任务使用了统一的建模,模型显示了没有见过的新任务的 zero-shot 推理能力,不经任何额外训练也能达到合理的性能。此外,通过使用 1% 的下游任务数据进行 prompt tuning,模型性能可以提升到接近 SOTA 的水平。使用 100% 的目标数据对预训练模型进行微调时,Uni-Perceiver 在几乎所有任务上都达到了与 SOTA 方法相当或更好的结果。
![]()
图 1 现有的特定于任务的感知模型和 Uni-Perceiver 的比较
这篇论文专注于文本、图像和视频模态,但 Uni-Perceiver 也可拓展到更多模态上。
![]()
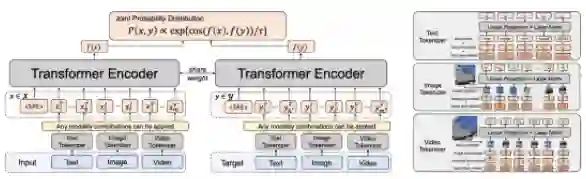
为了学习多模态的通用 representation,Uni-Perceiver 使用一系列单模态或跨模态任务进行了预训练。值得一提的是,在图像和视频分类任务中,作者将类别名称视作文本内容,这为连接起图像、视频和文本多个模态的 representation 提供了一定的监督。
推荐:
商汤等提出 Uni-Perceiver,迈向通用预训练感知模型。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Learning to Select the Next Reasonable Mention for Entity Linking. (from Jian Sun)
2. Multi-speaker Emotional Text-to-speech Synthesizer. (from Soo-Young Lee)
3. Improving language models by retrieving from trillions of tokens. (from Oriol Vinyals, Simon Osindero, Karen Simonyan, Laurent Sifre)
4. Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks. (from Bing Liu)
5. CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks. (from Bing Liu)
6. Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning. (from Bing Liu)
7. A pragmatic account of the weak evidence effect. (from Thomas L. Griffiths)
8. Refined Commonsense Knowledge from Large-Scale Web Contents. (from Gerhard Weikum)
9. NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation. (from Eduard Hovy)
10. Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand. (from Noah A. Smith)
本周 10 篇 CV 精选论文是:
1. Audio-Visual Synchronisation in the wild. (from Andrea Vedaldi, Andrew Zisserman)
2. Learning to Detect Every Thing in an Open World. (from Trevor Darrell, Kate Saenko)
3. Self-Supervised Keypoint Discovery in Behavioral Videos. (from Pietro Perona)
4. Segment and Complete: Defending Object Detectors against Adversarial Patch Attacks with Robust Patch Detection. (from Rama Chellappa)
5. Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior. (from Leonidas J. Guibas)
6. InvGAN: Invertable GANs. (from Michael J. Black, Larry S. Davis)
7. PTR: A Benchmark for Part-based Conceptual, Relational, and Physical Reasoning. (from Joshua B. Tenenbaum, Antonio Torralba)
8. GAN-Supervised Dense Visual Alignment. (from Jun-Yan Zhu, Antonio Torralba, Eli Shechtman)
9. Implicit Feature Refinement for Instance Segmentation. (from Xiangyu Zhang)
10. Geometry-Guided Progressive NeRF for Generalizable and Efficient Neural Human Rendering. (from Shuicheng Yan)
本周 10 篇 ML 精选论文是:
1. Adaptive Methods for Aggregated Domain Generalization. (from Alex Pentland)
2. From Good to Best: Two-Stage Training for Cross-lingual Machine Reading Comprehension. (from Jian Pei)
3. Mutual Adversarial Training: Learning together is better than going alone. (from Rama Chellappa)
4. Noether Networks: Meta-Learning Useful Conserved Quantities. (from Joshua Tenenbaum)
5. Extending the WILDS Benchmark for Unsupervised Adaptation. (from Jure Leskovec, Kate Saenko, Sergey Levine)
6. DR3: Value-Based Deep Reinforcement Learning Requires Explicit Regularization. (from Aaron Courville, Sergey Levine)
7. Neural Pseudo-Label Optimism for the Bank Loan Problem. (from Alexander C. Berg)
8. Spectral Complexity-scaled Generalization Bound of Complex-valued Neural Networks. (from Dacheng Tao)
9. New Tight Relaxations of Rank Minimization for Multi-Task Learning. (from Feiping Nie, Xuelong Li)
10. Domain Generalization via Progressive Layer-wise and Channel-wise Dropout. (from Yang Gao)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com