机器之心 & ArXiv Weekly Radiostation
本周论文包括华东师范大学等机构提出的全新图像分类方法 ViR以及 25 位研究者联合撰文尝试采用最原始的步骤逆向 Transformer。
ViR: the Vision Reservoir
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Activation Modulation and Recalibration Scheme for Weakly Supervised Semantic Segmentation
Exploring the Equivalence of Siamese Self-Supervised Learning via A Unified Gradient Framework
A Mathematical Framework for Transformer Circuits
Towards Transferable Adversarial Attacks on Vision Transformers
Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:ViR: the Vision Reservoir
摘要:
近一年来,视觉 Transformer(ViT) 在图像任务上大放光芒,比如在图像分类、实例分割、目标检测分析和跟踪等任务上显示出了卓越的性能,展现出取代卷积神经网络的潜力。但仍有证据表明,在大规模数据集上应用多个 Transformer 层进行预训练时,ViT 往往存在两个方面的问题:一是计算量大,内存负担大;二是在小规模数据集上从零开始训练时存在过拟合问题。
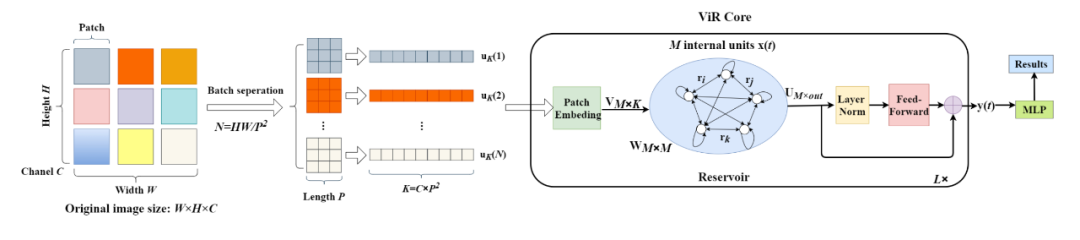
为了解决这些问题,来自华东师范大学等机构的研究者们提出了一种新的图像分类方法,即 Vision Reservoir (ViR) 。通过将每个图像分割成一系列具有固定长度的 token,ViR 构建一个具有几乎完全连接拓扑的纯库,以替换 ViT 中的 Transformer 模块。为了提高网络性能,研究者还提出了两种深度 ViR 模型。
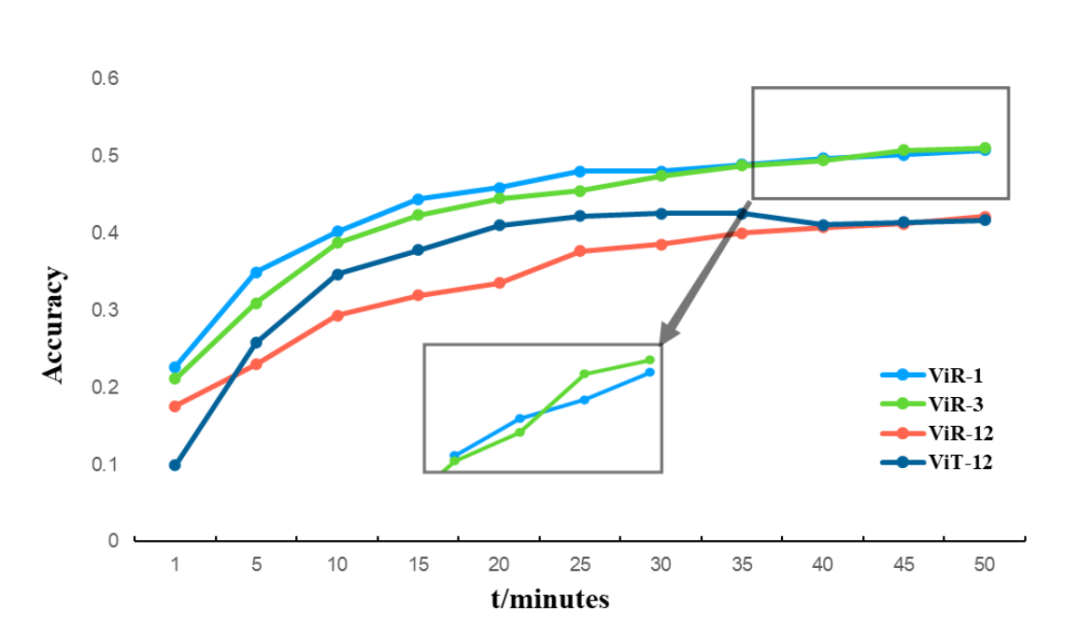
![]()
在 CIFAR100 数据集上执行 ViR 和 ViT 的时间消耗比较。
![]()
推荐:
参数量下降 85%,性能全面超越 ViT,华人团队提出全新图像分类方法 ViR
论文 2:MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
摘要:
在剪枝技术被成功应用于神经网络的压缩和加速之后,稀疏训练在近年来受到了越来越多研究者的关注,即如何从零开始直接训练一个高质量的稀疏神经网络。稀疏训练旨在有效降低神经网络训练过程中的计算和存储开销,从而加速训练过程,为在资源有限的边缘设备上的神经网络训练提供了更多可能性。
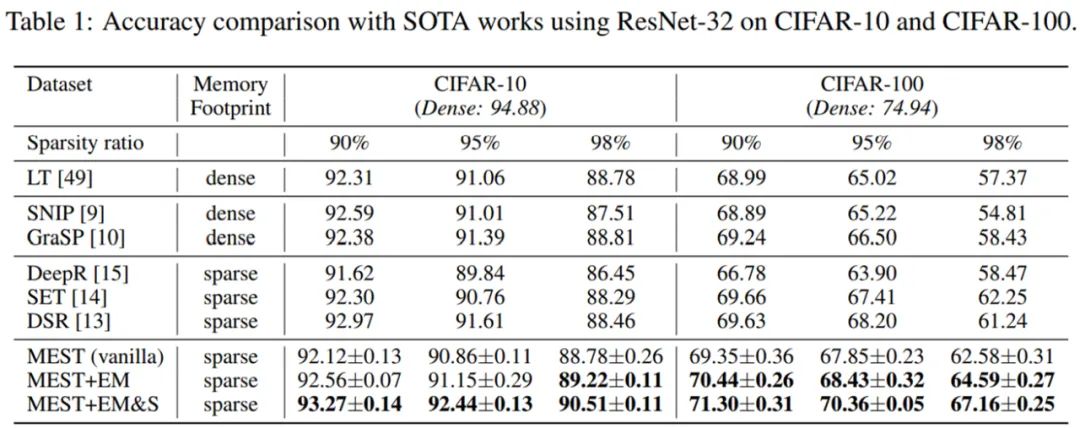
多数现有稀疏训练方法着力于设计更好的稀疏训练算法来追求更高的网络稀疏度同时保持高准确率。然而,稀疏训练的 “真正精神”,即稀疏训练能否带来实际的训练加速以及计算和存储资源的节省,却往往被忽视了。为此,由美国东北大学王言治教授、林雪教授研究组与威廉玛丽学院任彬教授研究组共同提出了 MEST 稀疏训练框架,有望实现在边缘设备上的准确、快速以及内存经济的稀疏训练。
![]()
![]()
推荐:
目前,该文章 [1] 已被 NeurIPS 2021 会议收录为 spotlight 论文。
论文 3:Activation Modulation and Recalibration Scheme for Weakly Supervised Semantic Segmentation
摘要:
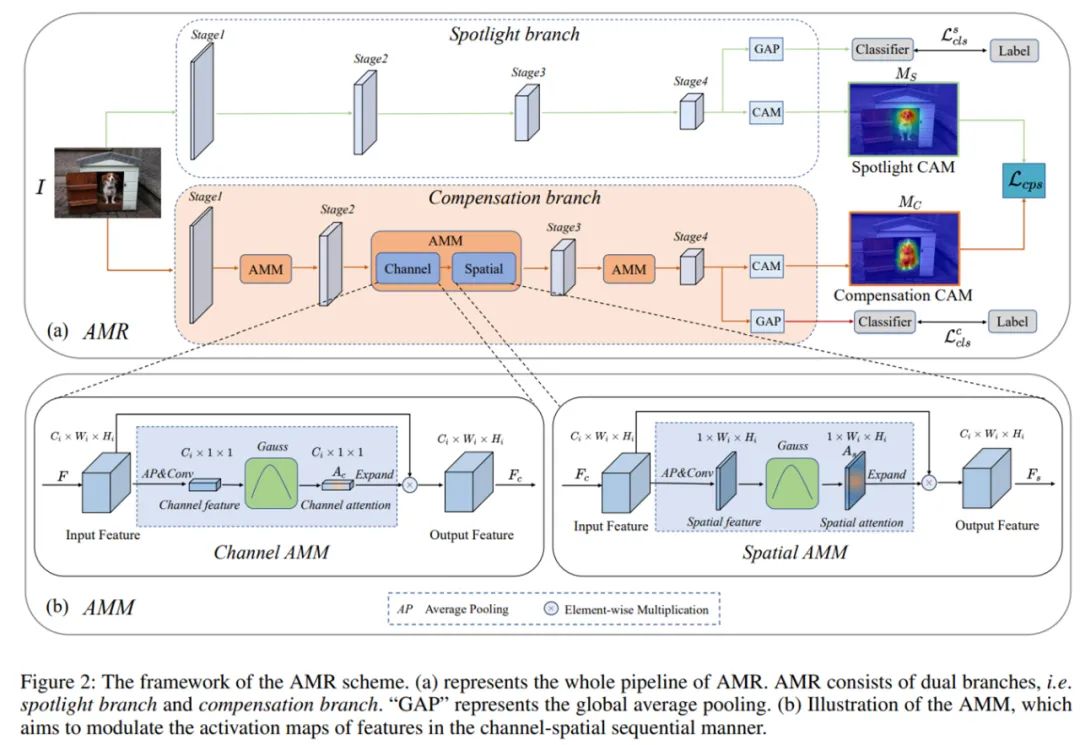
图像级弱监督语义分割(WSSS)是一项基本但极具挑战性的计算机视觉任务,该任务有助于促进场景理解和自动驾驶领域的发展。现有的技术大多采用基于分类的类激活图(CAM)作为初始的伪标签,这些伪标签往往集中在有判别性的图像区域,缺乏针对于分割任务的定制化特征。
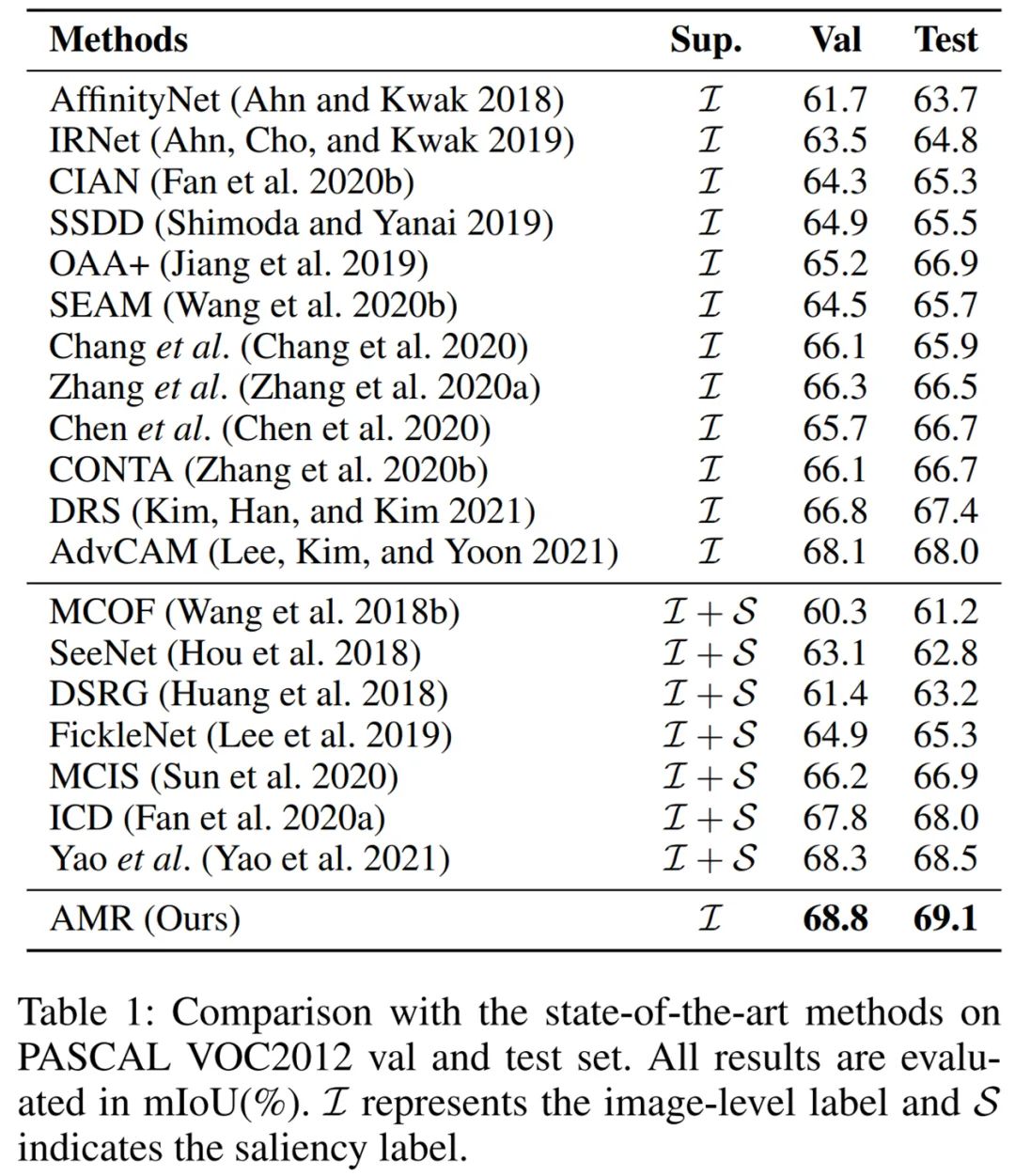
为了解决上述问题,字节跳动 - 智能创作团队提出了一种即插即用的激活值调制和重校准(Activation Modulation and Recalibration 简称 AMR)模块来生成面向分割任务的 CAM,大量的实验表明,AMR 不仅在 PASCAL VOC 2012 数据集上获得最先进的性能。实验表明,AMR 是即插即用的,可以作为其他先进方法的子模块来提高性能。论文已入选机器学习顶级论文 AAAI2022,相关代码即将开源。
![]()
![]()
推荐:
在图像级弱监督语义分割这项 CV 难题上,字节跳动做到了性能显著提升。
论文 4:Exploring the Equivalence of Siamese Self-Supervised Learning via A Unified Gradient Framework
摘要:
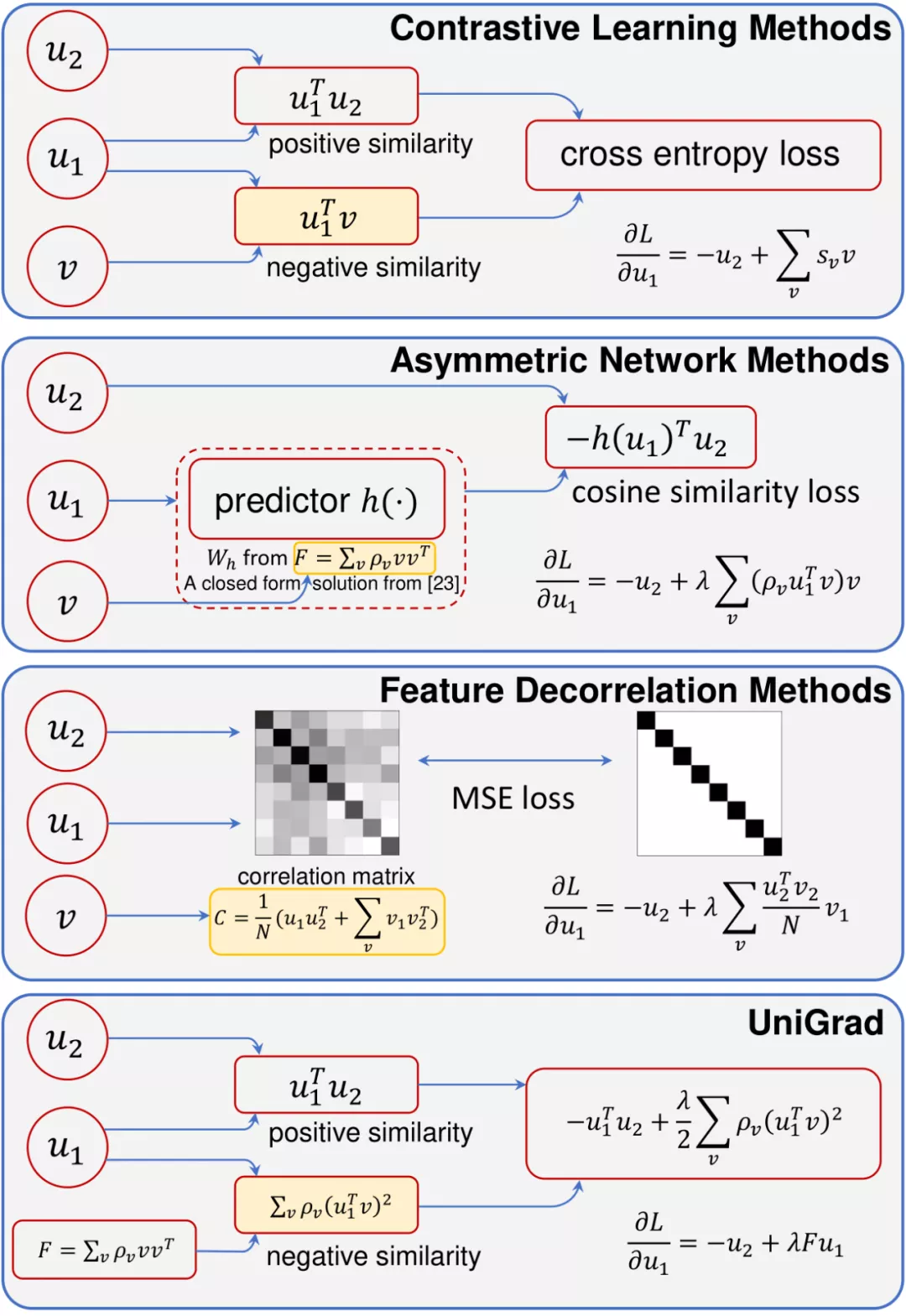
当下,自监督学习在无需人工标注的情况下展示出强大的视觉特征提取能力,在多个下游视觉任务上都取得了超过监督学习的性能,这种学习范式也因此被人们广泛关注。在这股热潮中,各式各样的自监督学习方法不断涌现,虽然它们大多都采取了孪生网络的架构,但是解决问题的角度却差异巨大,这些方法大致可以分为三类:以 MoCo、SimCLR 为代表的对比学习方法,以 BYOL、SimSiam 为代表的非对称网络方法,和以 Barlow Twins、VICReg 为代表的特征解耦方法。这些方法在对待如何学习特征表示这个问题上思路迥异,同时由于实际实现时采用了不同的网络结构和训练设置,研究者们也无法公平地对比它们的性能。
因此,人们自然会产生一些问题:这些方法之间是否存在一些联系?它们背后的工作机理又有什么关系?更进一步的,具体是什么因素会导致不同方法之间的性能差异?
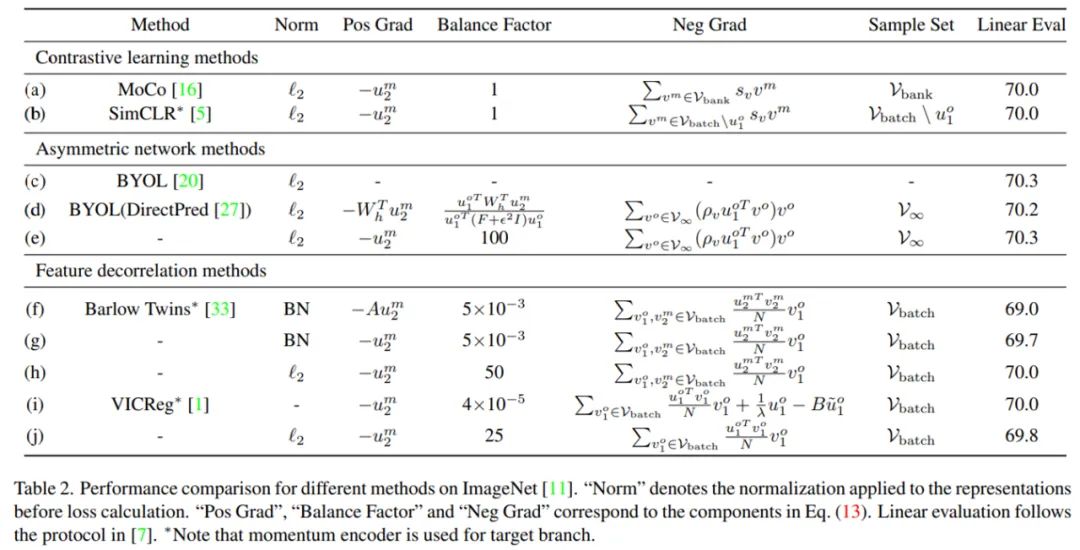
为此,来自清华大学、商汤科技等机构的研究者们提出一个统一的框架来解释这些方法。相较于直接去比较它们的损失函数,他们从梯度分析的角度出发,发现这些方法都具有非常相似的梯度结构,这个梯度由三部分组成:正梯度、负梯度和一个平衡系数。其中,正负梯度的作用和对比学习中的正负样本非常相似,这表明之前提到的三类方法的工作机理其实大同小异。更进一步,由于梯度的具体形式存在差异,研究者通过详细的对比实验分析了它们带来的影响。结果表明,梯度的具体形式对性能的影响非常小,而关键因素在于 momentum encoder 的使用。
![]()
![]()
推荐:
一个框架统一 Siamese 自监督学习,清华、商汤提出简洁、有效梯度形式,实现 SOTA。
论文 5:A Mathematical Framework for Transformer Circuits
摘要:
本文中,由 25 位研究者参与撰写的论文,尝试采用最原始的步骤逆向 transformer。考虑到语言模型的复杂性高和规模大等特点,该研究发现,从最简单的模型开始逆向 transformer 最有效果。该研究旨在发现简单算法模式、主题或是框架,然后应用于更复杂、更大的模型。具体来说,他们的研究范围仅包括只有注意力块的两层或更少层的 transformer 模型。这与 GPT-3 这样的 transformer 模型形成鲜明的对比,GPT-3 层数多达 96 层。
![]()
零层 attention-only transformers 模型。
![]()
单层 attention-only transformers 由一个 token 嵌入组成,后接一个注意力层(单独应用注意力头),最后是解除嵌入。
推荐:
经逆向工程,Transformer「翻译」成数学框架 | 25 位学者撰文
论文 6:Towards Transferable Adversarial Attacks on Vision Transformers
摘要:
与卷积神经网络(CNN)相比,Vision transformers(ViTs)在一系列计算机视觉任务中表现出惊人的性能。然而,ViTs 容易受到来自对抗样本的攻击。在人的视角中,对抗样本与干净样本几乎没有区别,但其包含可以导致错误预测的对抗噪声。此外,对抗样本的迁移性允许在可完全访问的模型(白盒模型)上生成对抗样本来攻击结构等信息未知的模型(黑盒模型)。
目前,对抗样本的迁移性在 CNNs 中得到了较为详尽的研究。这些工作利用数据增强或更优的梯度计算来防止对抗样本过拟合白盒模型,以此提高针对黑盒模型的攻击成功率。但关于 ViTs 中对抗样本迁移性的研究较少,且由于 CNNs 和 ViTs 间结构存在较大差异,在 CNNs 中表现良好的方法很难迁移到 ViTs 中来。
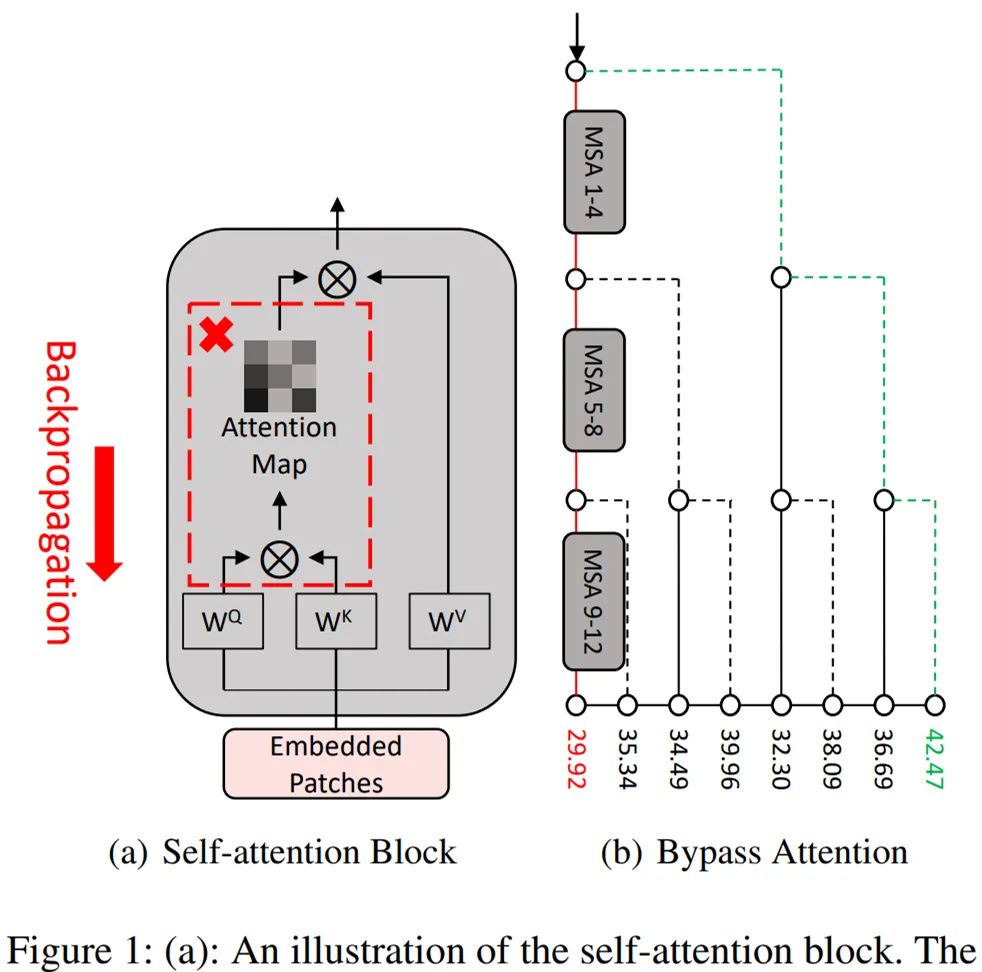
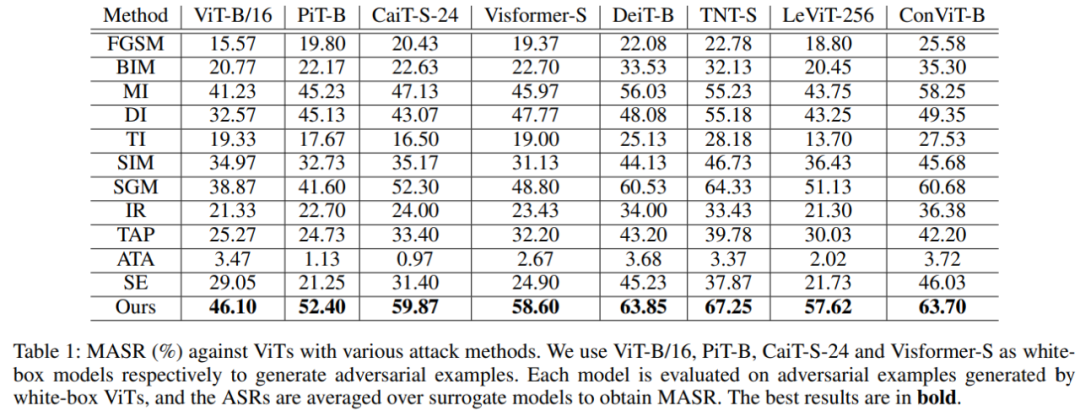
针对 ViTs 结构中的图像块(patch)输入和多头自注意力(Multi-headed Self-Attention,MSA)模块,来自复旦大学以人为本人工智能研究中心和马里兰大学的研究人员提出了双重攻击框架,包含无注意力(Pay No Attention,PNA)攻击和 PatchOut 攻击,来提高不同 ViT 模型之间甚至 ViT 与 CNN 之间对抗样本的迁移性。研究论文已被 AAAI 2022 接收。
![]()
![]()
不同攻击方法在 ViTs 上的攻击成功率结果对比。
推荐:
无注意力 + PatchOut,复旦大学提出面向视觉 transformer 的迁移攻击方法。
论文 7:Multi-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
摘要:
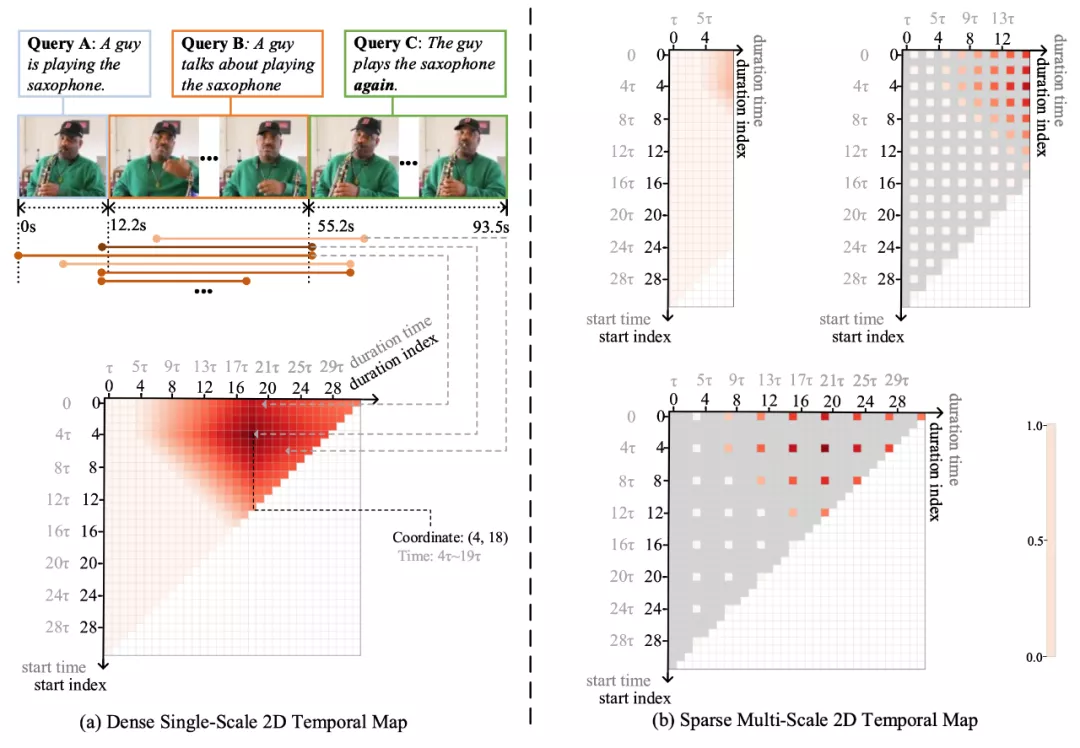
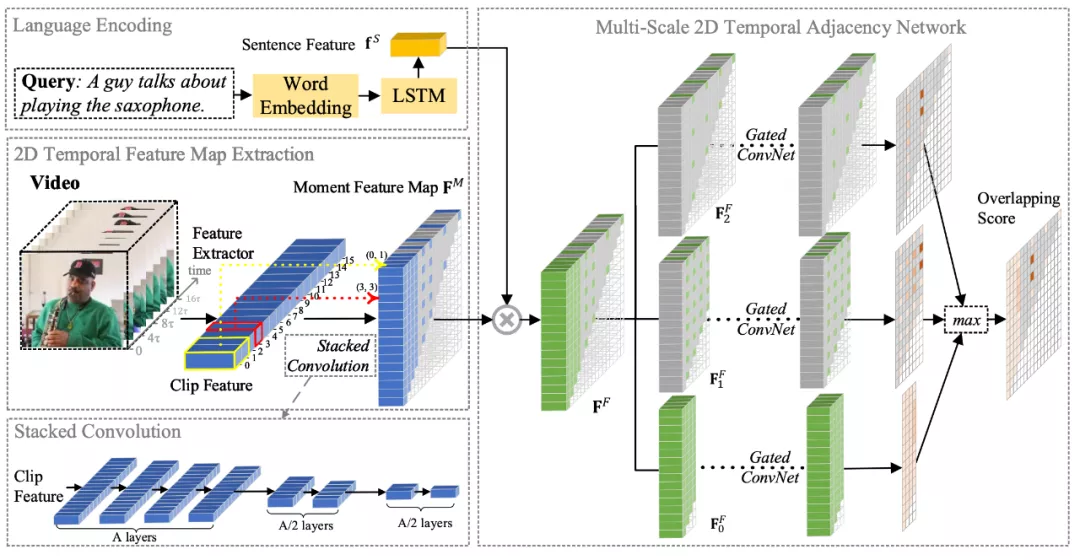
当时间的维度从一维走向二维,时序上的建模方式也需要相应的改变。本文提出了多尺度二维时间图的概念和多尺度二维时域邻近网络(MS-2D-TAN)用于解决视频时间定位的问题。本文拓展自 AAAI 2020 [1],并将单尺度的二维时间建模拓展成了一个多尺度的版本。新模型考虑了多种不同时间尺度下视频片段之间的关系,速度更快同时精度也更高。本文在基于文本的视频时间定位任务中验证了其有效性。相关内容将发表在 TPAMI 上。
![]()
![]()
推荐:
时间走向二维,基于文本的视频时间定位新方法兼顾速度与精度。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. LINDA: Unsupervised Learning to Interpolate in Natural Language Processing. (from Kyunghyun Cho)
2. Frequency-Aware Contrastive Learning for Neural Machine Translation. (from Tong Zhang)
3. CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark. (from Kun Zhou, Minlie Huang, Xiaodong He, Yang Liu)
4. Measuring Attribution in Natural Language Generation Models. (from Michael Collins)
5. Simple, Interpretable and Stable Method for Detecting Words with Usage Change across Corpora. (from Yoav Goldberg)
6. Counterfactual Memorization in Neural Language Models. (from Chiyuan Zhang)
7. Towards Personalized Answer Generation in E-Commerce via Multi-Perspective Preference Modeling. (from Bolin Ding)
8. HeteroQA: Learning towards Question-and-Answering through Multiple Information Sources via Heterogeneous Graph Modeling. (from Dongyan Zhao)
9. Parameter Differentiation based Multilingual Neural Machine Translation. (from Qian Wang)
10. Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization. (from Adriana Kovashka)
1. HSPACE: Synthetic Parametric Humans Animated in Complex Environments. (from William T. Freeman, Rahul Sukthankar)
2. Gendered Differences in Face Recognition Accuracy Explained by Hairstyles, Makeup, and Facial Morphology. (from Kevin W. Bowyer)
3. TAGPerson: A Target-Aware Generation Pipeline for Person Re-identification. (from Kai Chen)
4. Recursive Least-Squares Estimator-Aided Online Learning for Visual Tracking. (from Weiming Hu)
5. Cross-Domain Empirical Risk Minimization for Unbiased Long-tailed Classification. (from Xian-Sheng Hua)
6. Associative Adversarial Learning Based on Selective Attack. (from David Doermann)
7. Extended Self-Critical Pipeline for Transforming Videos to Text (TRECVID-VTT Task 2021) -- Team: MMCUniAugsburg. (from Rainer Lienhart)
8. Synchronized Audio-Visual Frames with Fractional Positional Encoding for Transformers in Video-to-Text Translation. (from Rainer Lienhart)
9. Invertible Network for Unpaired Low-light Image Enhancement. (from Wangmeng Zuo)
10. GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference. (from Ling Shao)
本周 10 篇 ML 精选论文是:
1. Wasserstein Flow Meets Replicator Dynamics: A Mean-Field Analysis of Representation Learning in Actor-Critic. (from Michael I. Jordan)
2. Can Reinforcement Learning Find Stackelberg-Nash Equilibria in General-Sum Markov Games with Myopic Followers?. (from Michael I. Jordan)
3. Graph Few-shot Class-incremental Learning. (from Huan Liu)
4. Sparsest Univariate Learning Models Under Lipschitz Constraint. (from Michael Unser)
5. Adaptivity and Non-stationarity: Problem-dependent Dynamic Regret for Online Convex Optimization. (from Zhi-Hua Zhou)
6. Differentially-Private Clustering of Easy Instances. (from Yishay Mansour)
7. Disentanglement and Generalization Under Correlation Shifts. (from Richard Zemel)
8. Efficient Performance Bounds for Primal-Dual Reinforcement Learning from Demonstrations. (from John Lygeros)
9. Learning Optimization Proxies for Large-Scale Security-Constrained Economic Dispatch. (from Pascal Van Hentenryck)
10. Exponential Family Model-Based Reinforcement Learning via Score Matching. (from Nathan Srebro)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com