论文笔记|使用递归GNN学习视频实例分割(二)
四、实验部分


 )
)
五、总结一下
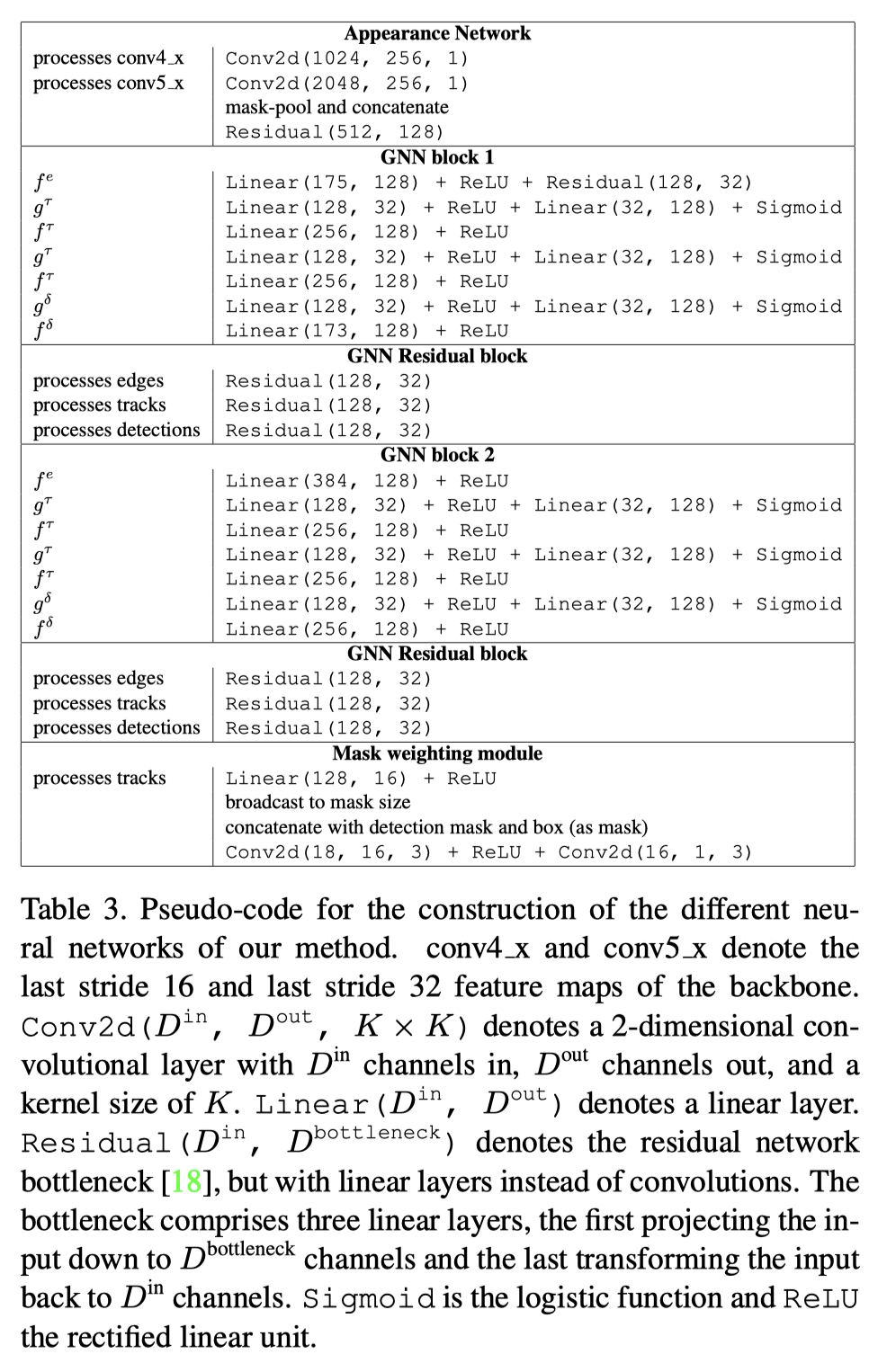
附录(节选一部分)
作者还在附录里提供了网络结构和伪代码,虽然论文代码还未开源,但是可以在这里稍微了解一下网络的工作原理。
-end-
登录查看更多
相关内容
Arxiv
15+阅读 · 2021年5月19日
Arxiv
26+阅读 · 2020年12月29日
Arxiv
44+阅读 · 2020年2月5日
Arxiv
19+阅读 · 2019年11月20日



相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2021年5月19日
Arxiv
26+阅读 · 2020年12月29日
Arxiv
44+阅读 · 2020年2月5日
Arxiv
19+阅读 · 2019年11月20日