Mask R-CNN 论文笔记
ICCV 2017 论文
论文链接 https://arxiv.org/abs/1703.06870
1.摘要
本文提出了一种简单、灵活和通用的目标实例分割框架 Mask R-CNN。该框架在 Faster R-CNN 上进行扩展,在边界框预测的分支上添加一个用于预测目标掩码的分支。使网络能够检测图像中目标的同时,还能为每个实例生成一个分割掩码。Mask R-CNN 通用性强,容易应用到其它领域,比如作者通过增加人体关键点检测分支,使网络能够检测出人体关键点的类别并定位其位置。Mask R-CNN 在 COCO Challenge 中的实例分割,目标识别,人体关键点检测三个任务上都得到了最佳结果。
2.实例分割介绍
Mask R-CNN 用于实例分割(Instance Segmentation),那么什么是实例分割呢?下图1-3分别展示了目标识别,语义分割(Semantic Segmentation)和实例分割。其中,目标识别是识别出图片中已知的物体,并用方框定位其位置,常用的方法有 Fast/Faster R-CNN 及其变体;语义分割是分类每一个像素到已知的类别,不用区分物体实例,常用全卷积网络(Fully Convolutional Net,FCN)实现;实例分割不仅要区分每个像素所属的类别,还要确定它是该类别中的哪个实例,如同“类”与“对象”的关系。本文中,作者将实例分割看成目标识别+语义分割的问题 。



3.Mask R-CNN 介绍
Mask R-CNN = Faster R-CNN with FCN on RoIs,其网络结构如图4所示。灰色部分为 Faster R-CNN 的的网络结构,作者将 Faster R-CNN 中的 RoI Pooling 层替换为提出的 RoIAlign 层。同时, 在目标框识别分支处,添加 Mask 预测分支,使用 FCN 预测 RoI 当中像素所属分类。

3.1 RoIAlign
RoI Pooling 的问题,没有实现像素对齐(如图5所示):
候选框映射到 feature map 的过程,坐标进行了取整,出现误差
RoI Pooling 层计算 bin 的大小时,进行了取整
两次取整的过程,虽然对目标检测影响不大,不利于预测像素级别的 mask。

因此作者提出,在这两次计算过程中,保留结果的小数,在 Pooling 时,使用双线性插值计算结果,如图6所示。每一点像素值由相邻四个点计算得出。

对于一个目标像素,假设其浮点坐标为 (i+u, j+v),其中 i、j 为浮点坐标的整数部分,u、v 为浮点坐标的小数部分。则该点像素值 f(i+u, j+v) 可由原图像中坐标为 (i, j)、(i+1, j)、(i, j+1)、(i+1, j+1) 位置上点的像素值确定,公式如下:
f(i+u,j+v) = (1-u)(1-v)f(i,j) + (1-u)vf(i,j+1) + u(1-v)f(i+1,j) + uvf(i+1,j+1)
3.2 网络结构
作者将网络分成三部分,第一个是主干网络用来进行特征提取,第二个是头部网络用来分类和边界框回归,第三个就是 mask 预测,如图7,左图使用残差网络提取特征,右图使用特征金字塔网络提取特征。

3.3 网络训练
分为两个阶段
第一阶段,训练 RPN,过程与 Faster R-CNN 相同,损失函数为:
L = 二分类损失 + bounding-box smooth L1 损失
第二阶段,训练 Mask R-CNN,损失函数为:
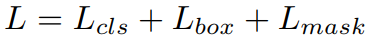
前两项分别为分类损失和 bounding-box 回归损失,定义与 Fast R-CNN 中相同。第三项为预测 mask 分支的损失。
每个 RoI 特征经过 FCN,输出 Km^2 维的结果,表示 K 个(类别个数)m*m 分辨率的二进制掩码。对每个像素使用 sigmoid 激活函数输出掩码,L_mask 定义为平均二进制交叉熵,只有网络预测的第 k 类产生 L_mask,其他类别的 mask 对损失无贡献。
3.4 测试阶段
测试阶段 mask 预测与训练阶段不同,没有使用 RPN 输出的 RoI 直接预测 mask,而是先通过 Faster R-CNN 得到 bounding-box,再对 box 区域预测 mask,提高 mask 准确度。
4.对照试验
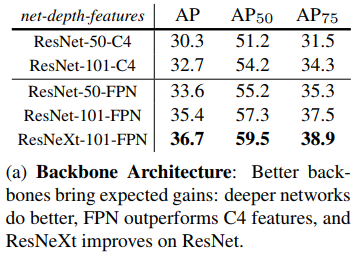
4.1 主干网络结构
更深的网络效果更好
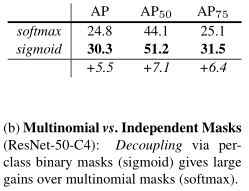
4.2 Mask Loss
激活函数使用 Sigmoid,损失函数使用二进制交叉熵。相对于传统的 FCN 网络使用 Softmax 激活函数,通过对比实验,Sigmoid 效果更好。
原因是在识别阶段已经预测了物体的类别,对于 mask 预测,不必再预测其他类别了,只需按二分类考虑,更容易训练。
4.3 Class-Specific vs. Class-Agnostic Masks
Mask R-CNN 输出中,每个 class 都有一个预测的 mask(Class-Specific)。如果不考虑类别,无论什么类,只输出一个 mask(Class-Agnostic),对结果有什么影响。实验发现:
| 类型 | AP |
|---|---|
| Class-Specific | 30.3 |
| Class-Agnostic | 25 |
可以看出,结果区别不大。
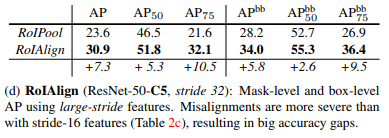
4.4 RoIAlign
RoIAlign 提高了 mask 和 边界框预测的准确度
5.使用 Mask R-CNN 进行人体姿势估计
为了证明网络的通用性和灵活性,作者对网络稍加改动,在物体识别层添加人体关键点检测分支,实现了人体关键点预测,如图8。

本文参考资料
http://kaiminghe.com/iccv17tutorial/maskrcnn_iccv2017_tutorial_kaiminghe.pdf


