
【导读】第九届国际学习表征大会(ICLR 2021)是深度学习领域的国际顶级会议,ICLR 2021一共有2997论文有效提交,大会最终接收860篇论文,其中 Oral 53 篇、Spotlight 114 篇,大会将于5月4-8日于线上举办。ICLR 采用公开评审(Open Review )机制。所有提交的论文都会公开,并且接受所有同行的评审及提问,任何学者都可或匿名或实名地评价论文。而在初审公开之后,论文作者也能够对论文进行调整和修改以及进行Rebuttal。近期,小编发现基于图神经网络(Graph Neural Networks,GNN)相关的接受paper非常多,图神经网络这几年方法的研究,以及在CV、NLP、DM上应用也非常广,也是当前比较火的topic。
为此,这期小编为大家奉上ICLR 2021必读的五篇图神经网络相关论文——SuperGAN、Simple GNN、AdaGCN、PageRank GNN、MLP to GNN
ICLR 2021 Accepted Papers : https://openreview.net/group?id=ICLR.cc/2021/Conference
AAAI2021QA、AAAI2021CI、AAAI2021CL、ICLR2020CI、ICML2020CI
1. How to Find Your Friendly Neighborhood: Graph Attention Design with Self-Supervision
作者:Dongkwan Kim, Alice Oh
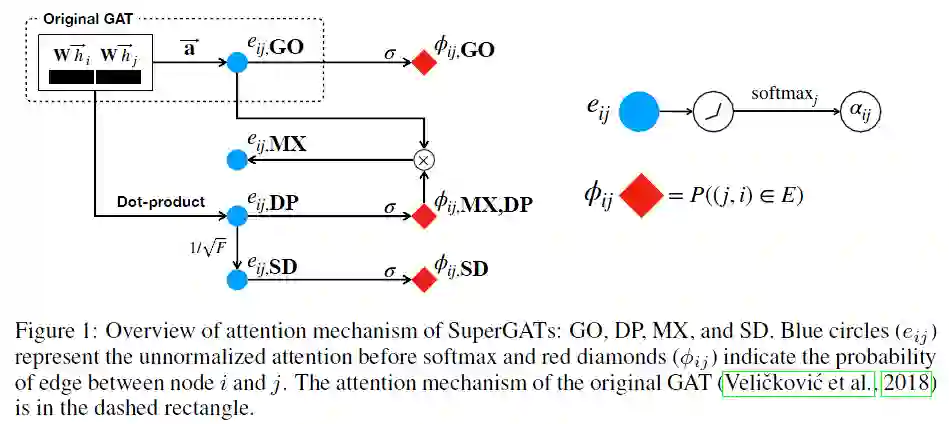
摘要:图神经网络中的注意力机制将较大的权重分配给重要的邻居节点,得到更好的表示。但是,图注意力机制学习到的内容不能理解,尤其是图存在噪声时。在本文中,我们提出了一种自监督的图注意力网络(SuperGAT),这是一种针对噪声图的改进图注意力模型。具体来说,我们用自监督的两种注意力形式来预测边,边的存在和缺失都包含有关节点之间关系重要性的信息。通过对边进行编码,SuperGAT在区分错误连接的邻居时会获得更多可表达的注意力。我们发现两个图的特性会影响注意力形式和自监督的有效性:同构和平均程度。因此,当知道两个图的特性时,我们的方法可为使用哪种注意力设计提供指导。我们对17个公开数据集进行的实验表明,我们的方法适用于其中的15个数据集,并且我们的方法设计的模型比基线模型性能更高。
网址:
https://openreview.net/forum?id=Wi5KUNlqWty
2. Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
作者:Qian Huang, Horace He, Abhay Singh, Ser-Nam Lim, Austin R. Benson
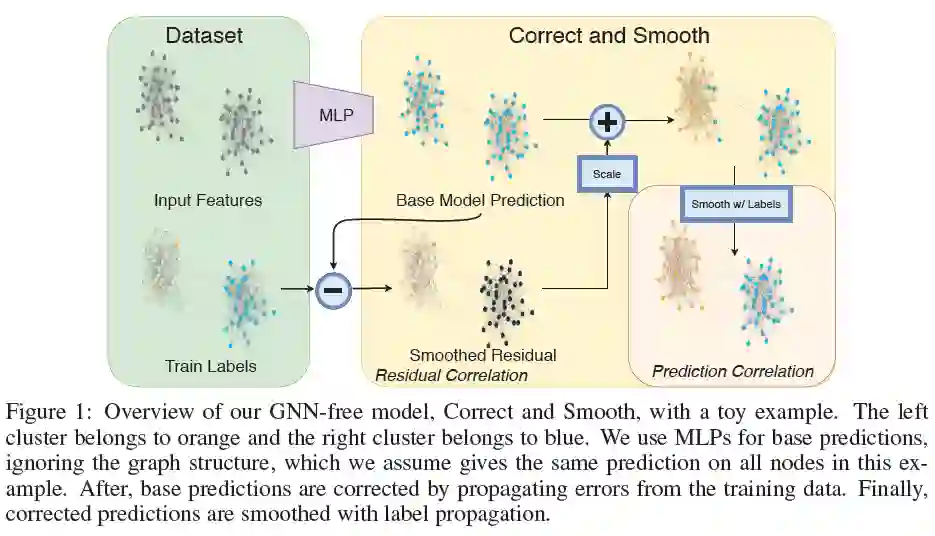
摘要:图神经网络(GNN)是图学习的主要技术。但是,对于GNN为什么取得成功以及对性能是否好的必要性了解还很少。对于许多标准的transductive节点分类基准,通过将忽略图结构的浅层模型与两个探索标签结构相关性的简单后处理步骤结合起来,我们可以超越或达到现存最新好GNN模型的性能:(i)“误差相关性”,它在训练数据中分散剩余的错误来纠正测试数据中的错误;(ii)“预测相关性”,它使对测试数据的预测变得平滑。我们称此总体过程为“纠正和平滑(C&S)”,后处理步骤是通过对早期基于图的半监督学习方法中标准标签传播技术进行简单修改而实现的。我们的方法在各种基准上都超过或接近了最好的GNN的性能,而参数却很少,运行时间也快了几个数量级。例如,我们以137倍的参数减少和超过100倍的训练时间超过了OGB-Products数据集上最好的GNN性能。我们方法的性能着重于如何将标签信息直接整合到学习算法中(就像传统技术一样),从而获得简单而可观的性能提升。我们还可以将我们的技术整合到大型GNN模型中,从而获得适度的提升。我们的OGB结果代码位于:
https://github.com/Chillee/CorrectAndSmooth
网址:
https://arxiv.org/abs/2010.13993
3. AdaGCN: Adaboosting Graph Convolutional Networks into Deep Models
作者:Ke Sun, Zhouchen Lin, Zhanxing Zhu
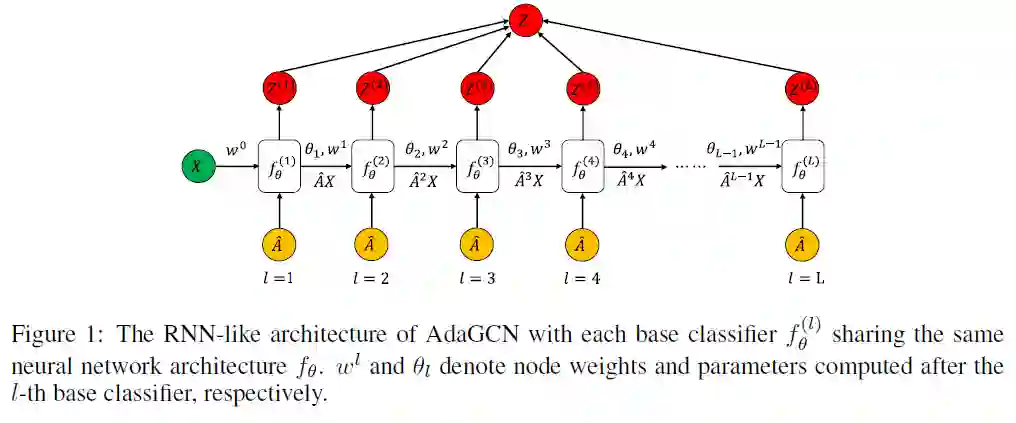
摘要:深度图模型的设计仍有待研究,关键部分是如何有效地探索和利用来自邻居不同阶点的知识。在本文中,我们通过将AdaBoost集成到网络计算中,提出了一种新颖的RNN类深度图神经网络架构。提出的图卷积网络AdaGCN(Adaboosting图卷积网络),具有从当前节点的高阶邻居中高效提取知识,然后以Adaboost方式将邻居的不同阶点中的知识集成到网络中的能力。与直接堆叠许多图卷积层的其他图神经网络不同,AdaGCN在所有``层''之间共享相同的基础神经网络架构,并且经过递归优化,类似于RNN。此外,我们还在理论上建立了AdaGCN与现有图卷积方法之间的联系,从而展示了我们的方法的好处。最后,大量的实验证明了跨不同标签比率的图始终如一的最新预测性能以及我们的方法AdaGCN的计算优势。
网址:
https://arxiv.org/abs/1908.05081
4. Adaptive Universal Generalized PageRank Graph Neural Network
作者:Eli Chien, Jianhao Peng, Pan Li, Olgica Milenkovic
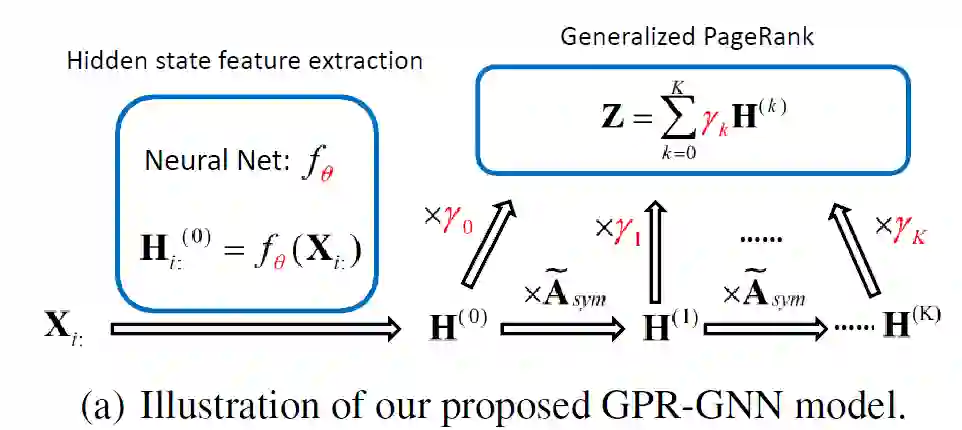
摘要:在许多重要的图数据处理应用程序中,获取的信息有节点特征和图拓扑结构。图神经网络(GNN)旨在利用这两种信息,但是是用一种通用的方式对其进行整合,并没有一个最佳权衡策略。通用性是指同构或异构图假设的独立性。我们通过引入一种新的广义PageRank(GPR)GNN架构来解决这些问题,该架构可以自适应地学习GPR权重,从而联合优化节点特征和拓扑信息提取,而不管节点标签同构或异构程度。学习的GPR权重自动调整为节点标签模式,与初始化类型无关,从而为通常难以处理的标签模式保证了出色的学习性能。此外,它们允许避免特征过度平滑,这一过程使特征信息无差别化,而无需网络很浅。我们在上下文随机块模型生成的新型合成基准数据集有上对GPR-GNN方法进行了理论分析。我们还在知名的基准同质和异类数据集上,将我们的GNN架构与几个最新的GNN的节点分类问题进行了性能比较。结果表明,与现有方法相比,GPR-GNN在合成数据和基准数据上均提供了显着的性能改进。
网址:
https://arxiv.org/abs/2006.07988
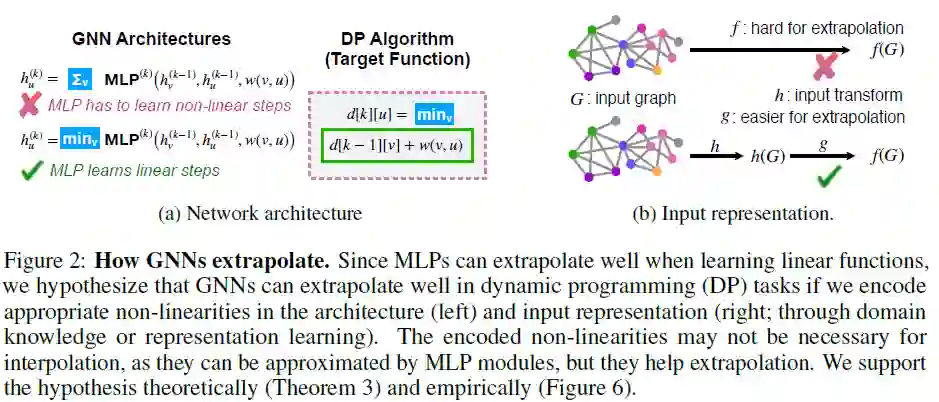
5. How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks
作者:Keyulu Xu, Mozhi Zhang, Jingling Li, Simon S. Du, Ken-ichi Kawarabayashi, Stefanie Jegelka
摘要:我们研究了通过梯度下降训练的神经网络如何外推,即它们在训练分布的支持范围之外学到了什么。以前的工作在用神经网络外推时报告了混合的经验结果:虽然多层感知器(MLP)在简单任务中无法很好地推理,但图神经网络(GNN)是带有MLP模块的结构化网络,在较复杂的任务中也有一定的成功。我们提供了理论上的解释,并确定了MLP和GNN良好推断的条件。我们首先显示受梯度下降训练的ReLU MLP沿原点的任何方向迅速收敛到线性函数,这表明ReLU MLP无法在大多数非线性任务中很好地推断。另一方面,当训练分布足够“多样化”时,ReLU MLP可以证明收敛到线性目标函数。这些观察结果得出一个假设:如果我们在体系结构和输入表示中编码适当的非线性,则GNN可以很好地推断出动态编程(DP)任务。我们为该假设提供理论和经验支持。我们的理论解释了先前的外推法成功并提出了其局限性:成功的外推法依赖于结合特定于任务的非线性,这通常需要领域知识或广泛的模型搜索。
网址:
