论文 | 深度学习实现目标跟踪

论文:Track-RNN:Joint Detection and Tracking Using Recurrent Neural Networks
后台回复“Track-RNN” 就可以获取 原文 pdf~
和静态图片中的目标检测相比,目标跟踪相似但又不同。目标检测是在图片给出的候选区域中,我们针对某个区域是否包含既定目标进行打分。然后我们选择最高打分的那个区域。和目标检测不同的是,目标跟踪不仅要检测出目标,还要在接下来的视频时间中,判断是否有既定目标。单目标跟踪是,在初始阶段对目标进行初始化,然后追踪特定的目标。多目标检测是,目标数量在跟踪过程中变化,我们要跟踪每一个目标。多目标检测更具备挑战性,因为这要求能够在目标被遮挡重新出现后进行再次跟踪。
在目标跟踪领域,大多数的工作集中在使用人工调制的参数。随着训练数据的增加,使用深度学习的方法来实现目标跟踪正在逐步发展。
2.1 技术方案总结
我们将目标跟踪定义为一个马尔可夫决策问题。视频中的目标会经历四个状态,初始化,被跟踪,丢失,重新跟踪。这篇文章主要集中在单目标跟踪问题。
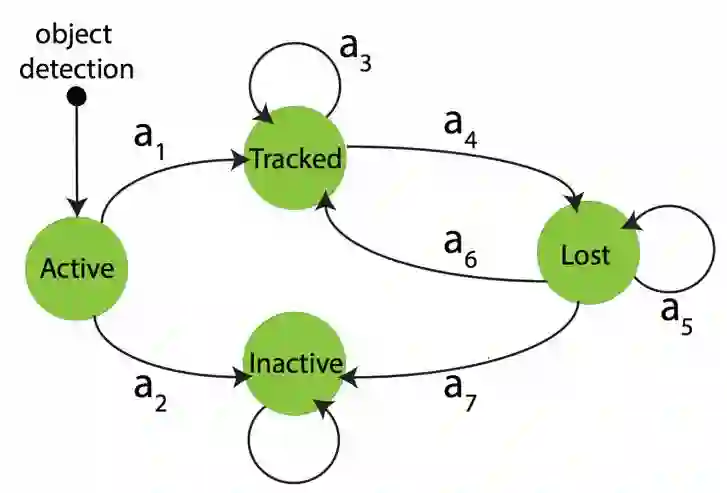
图1 跟踪目标的四个状态
我们的 track-rnn主要包含两个部分,检测部分和跟踪部分。这两个部分在底层共享卷积网络。
检测部分主要使用了Fast-RCNN模型来进行跟踪轨迹并进行初始化。当目标被检测到,新的目标轨迹会被增加到轨迹列表中。
跟踪部分包括预期动作生成和外形比较网络两个部分。在给出selectvie searh结果和历史轨迹的基础上,预期动作生成指出当前帧中的可能的候选区域。外形对比网络输出跟踪得分,然后我们选出每一帧中最高得分的候选区域作为目标的跟踪轨迹。
2.2 动作生成模型
动作生成模型,使用之前的目标区域(包括中心点坐标以及长和宽),然后生成下一帧图像中被跟踪目标可能出现的区域。
2.3 外形比较网络
外形比较网络使用候选区域和当前帧图像作为输入,然后计算出候选区域和目标的真实区域的重叠率作为当前候选区域的分数。
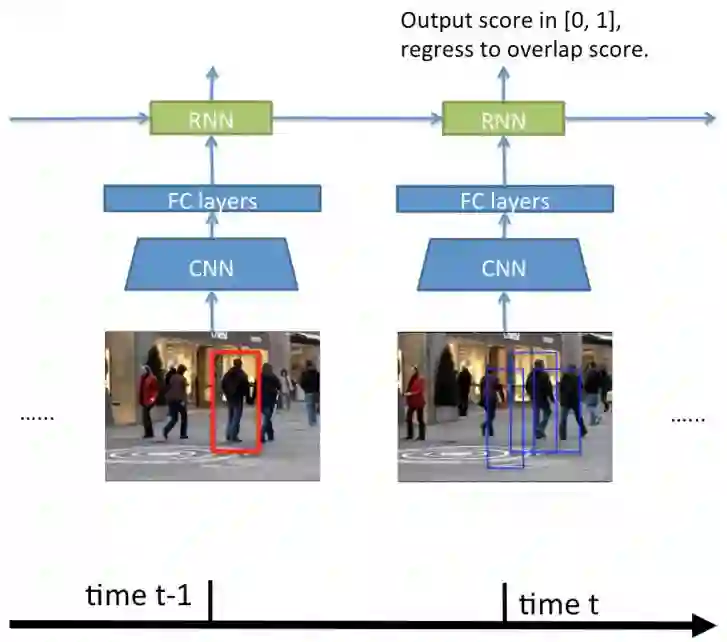
图2 外形比较网络
在底层,我们使用基于AlexNet的RCNN从每张图片的候选区域中提取出图像特征。把RCNN生成的图像特征投喂到顶层的RNN中。
在顶层,我们设计了RNN,用来利用之前时间序列中的空间信息以及从当前时间点提取出来的图像特征。每一个时间t,RNN计算出每个候选区域的IOU(重叠率)以及当前隐层的状态。每个候选区域将会生成单独的新的隐层状态,我们选择最高得分的IOU来更新隐层。
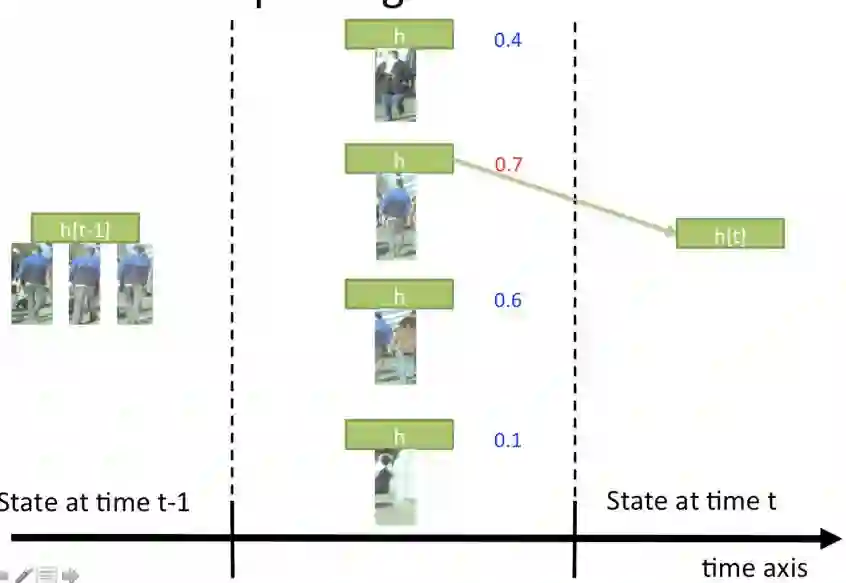
图3 隐层更新图(目标没有被遮挡)
如果得分高于0.5,我们将更新隐层。如果没有得分高于0.5,我们将视为被跟踪目标丢失,而且不会更新隐层状态。
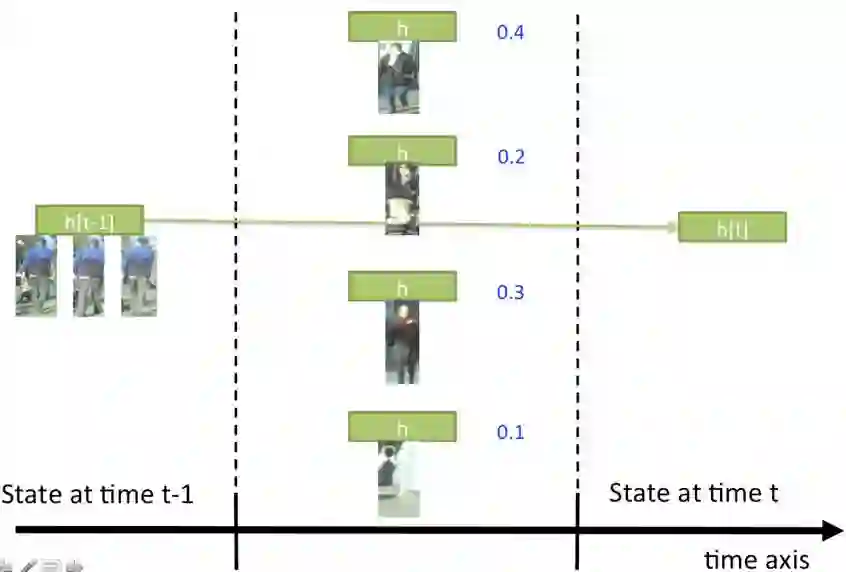
图4 隐层更新图(目标被遮挡)
2.4 跟踪单目标
在跟踪单目标的过程中, 我们首先在当前帧中生成最有可能候选区域,然后从selective search 的结果池中选出256的样本。对于每一个候选区域,我们计算出IOU的分支,然后选择当前帧中最高得分的候选区域。
2.5 训练过程
我们在MOT的数据上训练我们的模型。在训练阶段,我们首先把每段轨迹切割成一小段。然后在每帧图片中的选出512个候选区域。然后计算候选区域和真正的目标区域的IOU分数。然后,我们把这些批次投喂到我们的神经网络中,为IOU分数的回归做训练。
我们发现,测试性能很大程度的得益于在训练中使用了长瞬时信息。我们使用了存储在本地的Conv5的特征,这能够使每批次训练的数目变多。我们通过20个步骤的批量训练,这使得在训练过程中能够更好的长时间跟踪目标。
3.1 目标检测结果
在Fast-RCNNCaffe版本的基础上我们实现了Fast RCNN模型的TensorFLow版本。我们使用MOT测试数据的一半作为训练数据,另一本作为测试数据。如表所示,我们的检测系统的性能比默认的检测系统性能高出12到52个百分点。
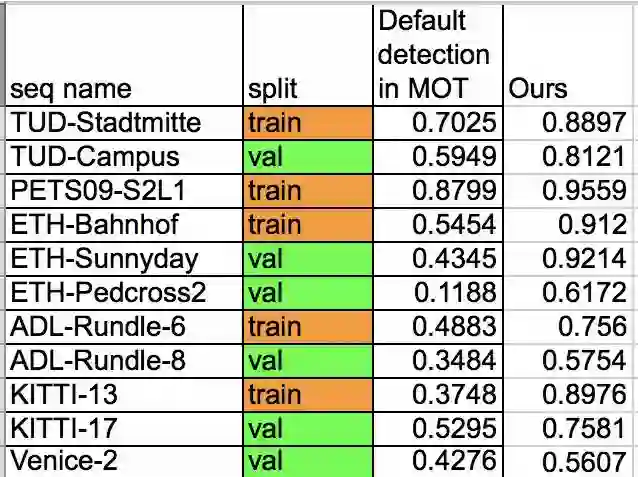
图5 目标检测得分
4.2 目标跟踪结果
我们的目标跟踪结果如下图所示,颜色代表跟踪得分,红色代表高分值,蓝色代表低分值,白色代表中等分值。从下图我们可以看看出,当被跟踪目标没有被遮挡时,我们的跟踪系统成功地跟踪到了目标,并给出了高分值。当目标消失后,没有一个区域被给予高分值。当目标重新出现后,跟踪系统重新识别了目标,并给予高分值。

图6 目标跟踪结果图
版权声明:转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。


登录查看更多
相关内容

标跟踪是指:给出目标在跟踪视频第一帧中的初始状态(如位置,尺寸),自动估计目标物体在后续帧中的状态。
目标跟踪分为单目标跟踪和多目标跟踪。
人眼可以比较轻松的在一段时间内跟住某个特定目标。但是对机器而言,这一任务并不简单,尤其是跟踪过程中会出现目标发生剧烈形变、被其他目标遮挡或出现相似物体干扰等等各种复杂的情况。过去几十年以来,目标跟踪的研究取得了长足的发展,尤其是各种机器学习算法被引入以来,目标跟踪算法呈现百花齐放的态势。2013年以来,深度学习方法开始在目标跟踪领域展露头脚,并逐渐在性能上超越传统方法,取得巨大的突破。
Arxiv
4+阅读 · 2018年5月8日
Arxiv
9+阅读 · 2018年1月25日





相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年5月8日
Arxiv
9+阅读 · 2018年1月25日