论文笔记|使用递归GNN学习视频实例分割(一)
最近看了一篇论文《Learning Video Instance Segmentation with Recurrent Graph Neural Networks》,来自Arxiv的preprint(暂时没找到论文的被收录的哪个会议)。因为毕设方向是使用图神经网络去解决图像/视频理解的非欧空间问题,于是最近开始阅读这个方向的内容。
现有的大多数视频实例分割方法是由多个模块组成,这些模块启发式地组合,以产生最终的输出。作者认为目前的一个挑战性的问题是:如何提出一个纯粹的基于学习的方法,而不只是对时序信息和视频实例分割所需的通用的轨迹处理(track management)去建模。
作者提出了一个新的学习方法,其中整个的视频实例分割是一个联合的模型。作者基于这个方法设计了一个可扩展的模型。在图神经网络的帮助下,会处理每一帧中所有可用的新信息。过去的信息也会被考虑并通过循环连接进行处理。
作者在论文中描述,他们的实验可以在超过25FPS的帧率下运行,优于目前的其他方法。
(论文翻译可能有不准确,小白继续学习中,求轻拍)

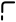
一、简介


视频实例分割是指从一组图像序列中同时检测、分割和跟踪对象实例的计算机视觉任务。与图像实例分割相比,其在时序这一因素上会有一些更多的挑战:由于存在其他特征类似的实例,在每一帧中继续保持正确的实例ID会变得困难;并且物体可能会受到遮挡、快速运动或外观变化等影响。此外,视频中还可能包括摄像机剧烈抖动和严重的背景干扰。
之前的工作从MOT、视频目标检测、视频实例分割等相关领域得到了启发,大多数方法都采用了MOT中流行的跟踪-检测方法。实例分割方法在每一帧中提供检测结果,每一个检测结果包括置信度、语义类(semantic class)和掩码。然后,任务被简化为从这些检测结果中形成轨迹(track)。给定一组已经初始化的轨迹,我们须确定每个检测结果是否属于现有的轨迹之一,是否为假阳性,或者是否应该初始化一个新的轨迹。现有的方法学习如何匹配检测对,然后依靠启发式的方法形成最终的输出,例如,初始化新的轨迹、预测置信度、删除轨迹和预测class memberships。
但是这种pipeline有两个明显的缺点:(一) 学习的模型不是很灵活,例如不能对所有检测结果进行全局推理,或者不能从时间维度上获取信息;(二) 模型的学习阶段不能对推理进行密切地(closely)建模,例如只利用成对的帧,或者忽略后续检测合并的阶段。这意味着该方法没有机会学习视频实例分割问题的所有信息。例如,该方法无法学习如何处理所利用的实例分割方法所犯的错误,例如对于一些轻量级的(个人觉得可能是样本太小导致训练不足)或者是具有挑战性(各种因素造成的处理难度高)的视频。
作者的贡献是:(i) 提出了一种新的训练方式,使我们能够以端到端的方式训练视频实例分割的模型。(ii) 我们提出了一个基于图神经网络和循环神经网络的适合且可行的模型。(iii)我们将实例外观以高斯分布建模,并引入了可学习的更新(update)公式。(iv) 我们在综合实验中对我们的方法进行了基准测试和有效性分析。我们的方法优于之前的近实时方法,在YouTube VIS数据集上的mAP相对地增加了9.0%。
二、相关工作
视频实例分割(VIS)问题最初是由Yang等人提出的,他们提出了几种简单且直接的方法来解决它。他们遵循跟踪-检测方法,首先应用实例分割方法在每一帧中提供检测结果,然后根据这些检测结果形成轨迹。他们对几种不同的匹配检测的方法进行了实验,例如视频目标分割方法的掩码传播(mask propagation);使用MOT方法,其中图像帧的边界框是经过卡尔曼滤波的,目标是通过学习到的重识别机制来重新检测的;以及对实例特征外观描述子的相似性学习。
三、方法
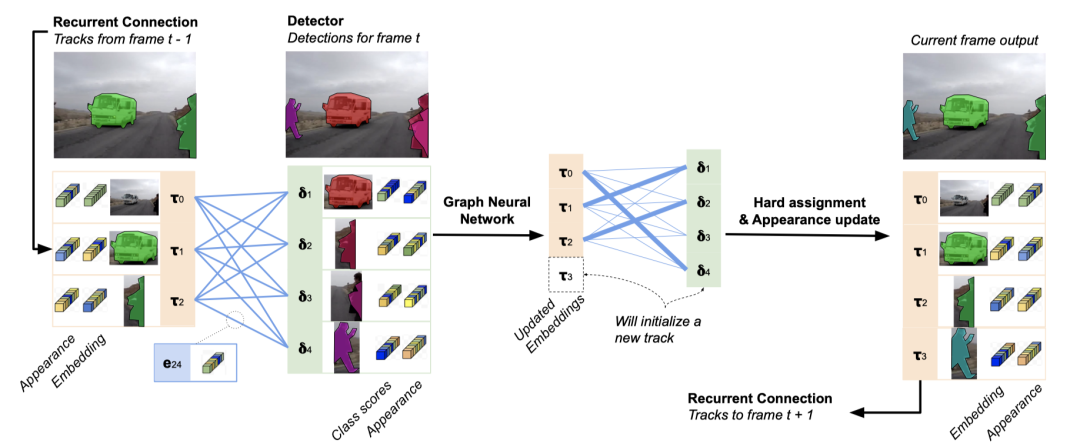
上图中描述了该方法。实例分割方法适用于每一帧,检测集与保存的轨迹的记忆(memory)一起,被构建成一个二向图。每个节点和每个边都用一个嵌入来表示。这些嵌入送由GNN处理,并直接用于预测指配(assignment)和轨迹的初始化。轨迹嵌入由类似LSTM的单元作进一步处理,并形成最终的轨迹嵌入。这些信息用于预测当前帧中的轨迹置信度和类成员资格(class membership),并通过循环连接将信息传播到下一个step。最后,从匹配的检测结果中为轨迹分配掩码和外观描述子。
1. 跟踪-检测方法
就像之前描述的那样,跟踪-检测方法的主要原理是:在每一帧中,作者让实例分割方法产生暂定的检测结果
现有的大多数方法都通过训练一个网络来提取外观描述子,将轨迹与检测结果关联起来。如果描述子对应于同一个目标,则被训练成相似的描述子,如果对应于不同的目标,则被训练成不相似的描述子。这种方法带来的问题是,对应于视觉和语义相似但实例不同的外观描述子,会被训练成不同的。在这种情况下,让外观描述符相似,而依靠比如空间信息,可能会更好。因此,网络在做出决定之前,应该评估所有可用信息。
进一步得到的信息可以从所考虑的轨迹检测对其他轨迹检测对中获得。孤立地确定一个轨迹检测对是否匹配可能是困难的,例如在杂乱的场景中或可见度很低的情况下。在这种情况下,实例分割方法可能会提供多个检测结果,这些检测结果在一定程度上都与同一个对象重复。另一种困难的场景是当有突然而剧烈的相机运动的情况,此时可能需要全局推理,以忽略空间相似性,或者区别对待。因此我们假设,网络同时推理所有的轨迹和检测结果是很重要的。
在决定一个检测结果是否应该被初始化一个新的轨道时,自然就可以这样做。检测结果与现有轨迹的匹配程度一定会影响到是否应该初始化新轨迹的决策。在现有的工作中,这个观察结果被实现为一个硬决策。也就是说,如果检测被分配到一个轨道上,它将不会初始化一个新的轨道,否则就会。作者避免了这种启发式,而是让网络同时推理将检测分配给轨道和初始化新的轨道。
让每个轨迹-检测结果对用一个
边缘嵌入
接下来详细介绍轨迹的分数评估步骤。
2. 轨迹评分
3. 循环链接
为了处理目标轨迹,随着时间的推移来传播信息是至关重要的。作者提出通过循环连接来实现这一操作,它带来了端到端训练的好处。
然而,天真地添加循环连接,会导致训练变得极度不稳定,进而导致视频实例分割的效果不理想。即使有细致的权重初始化和低的学习率,都会出现激活和梯度的尖峰(spikes)。这是训练RNN时遇到的一个众所周知的问题,通常可以使用长短期记忆(LSTM)或门控递归单元(GRU)模块来解决。这些模块使用的是乘法的(multiplicative)sigmoid激活的门控系统,已经被反复地证明可以很好地对序列数据进行建模。
普通的LSTM有如下形式:
LSTM中循环连接的输出,作为下一个时间步骤的输入,使其能够模拟时间信息。它的门控系统减轻了激活函数的的梯度爆炸/消失问题。
作者对LSTM做了一些修正,将其与图网络联系在了一起。为了循环地将图网络的输出(特别是更新后的轨迹嵌入)作为下一个step的图网络的输入。作者将LSTM中的线性网络替换为图网络,并仍旧采用门控机制。作者将上面7个公式的后6个建立了一个映射
4. 模型外观
为了准确地匹配跟踪结果和检测结果,作者为每个被跟踪的目标创建了特定实例的外观模型。为此,作者添加了一个由几个卷积层组成的外观网络,并将其应用于主干ResNet的特征图。外观网络的输出与检测结果提供的掩码汇集在一起,从而得到每个检测的外观描述子。轨迹从检测结果中收集外观,并随着时间的推移构建该轨迹的外观模型。在匹配过程中,轨迹和检测结果之间的外观相似性将作为重要的附加线索。外观网络的目的是学习丰富的表征,使我们能够区分视觉或语义上相似的实例。
一开始作者曾尝试将外观信息直接集成到GNN中,但是效果并没有明显的提高。作者认为是因为不同问题的差异很大造成的。视频实例分割问题的变数相当大:考虑的场景和目标有很大的差异,与之相比,可用的标记训练序列相当少。相比之下,MOT通常是针对单一类型的场景或单一类别的目标,特征匹配的学习要比视频实例分割可用的训练实例多很多。
为了避开这个问题,作者将外观分开处理,并在各特征的通道中强制执行对称性(symmetry)。每个轨迹将其外观建模为一个具有对角协方差的多维
高斯分布。当轨道被初始化时,可以将初始化检测的外观向量作为均值
(未完待续)


