BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题

©PaperWeekly 原创 · 作者| 苏剑林
单位|追一科技
研究方向|NLP、神经网络

“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的 baseline,基于ape210k 数据集 [1] 训练,直接用 Seq2Seq 模型生成可执行的数学表达式,最终 Large 版本的模型能达到 73%+ 的准确率,高于 ape210k 论文所报告的结果。

数据处理
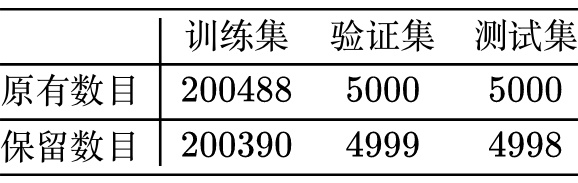
这里我们先观察一下 ape210k 数据集的情况:
{
"id": "254761",
"segmented_text": "小 王 要 将 150 千 克 含 药 量 20% 的 农 药 稀 释 成 含 药 量 5% 的 药 水 . 需 要 加 水 多 少 千 克 ?",
"original_text": "小王要将150千克含药量20%的农药稀释成含药量5%的药水.需要加水多少千克?",
"ans": "450",
"equation": "x=150*20%/5%-150"
}
{
"id": "325488",
"segmented_text": "一 个 圆 形 花 坛 的 半 径 是 4 米 , 现 在 要 扩 建 花 坛 , 将 半 径 增 加 1 米 , 这 时 花 坛 的 占 地 面 积 增 加 了 多 少 米 * * 2 .",
"original_text": "一个圆形花坛的半径是4米,现在要扩建花坛,将半径增加1米,这时花坛的占地面积增加了多少米**2.",
"ans": "28.26",
"equation": "x=(3.14*(4+1)**2)-(3.14*4**2)"
}不过,我们需要做一些前处理,因为 ape210k 给出的 equation 并不是都可以直接 eval 的,像上面的例子 150*20%/5%-150 对 python 来说就是一个非法表达式。笔者所做的处理如下:
-
对于a%这样的百分数,统一替换为(a/100); -
对于a(b/c)这样的带分数,统一替换为(a+b/c); -
对于(a/b)这样的真分数,在题目中去掉括号变为a/b; -
对于比例的冒号:,统一替换为/。

模型简介
模型其实是最没什么好讲的,就是以 original_text 为输入、equation 为输出,以“BERT+UniLM”为基础架构,训练一个 Seq2Seq 模型。如果对模型还有什么疑惑的地方,请阅读从语言模型到Seq2Seq:Transformer如戏,全靠Mask。
网盘链接:
https://pan.baidu.com/s/1Xp_ttsxwLMFDiTPqmRABhg
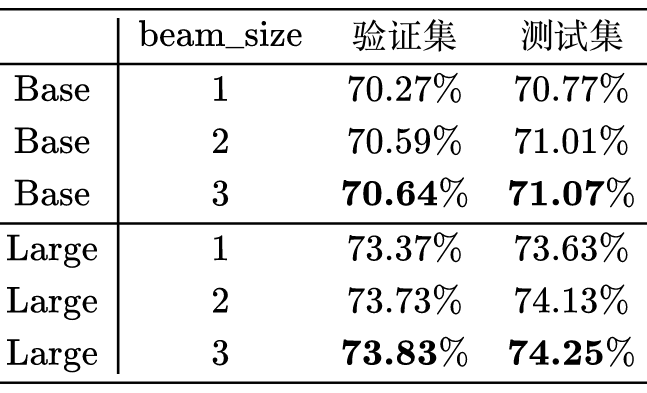
Large 模型的结果已经比 ape210k 的论文 Ape210K: A Large-Scale and Template-Rich Dataset of Math Word Problems [4] 所报告的 70.20% 要明显高了,因此说明我们这里的模型是一个不算太差的 baseline。

标准输出
如果纯粹从建模的角度来看,其实我们的任务已经完成了,即模型只需要输出式子就行了,评测的时候则只需要判断式子 eval 后的结果跟参考答案是否一致就好。
但是从实际实用的角度,我们还需要对输出做进一步的标准化,即根据不同的题目决定输出的是小数、整数、分数还是百分数等,这就需要我们:1)决定什么时候该输出什么格式;2)根据指定格式对结果进行转换。
第一步比较简单,一般来说根据题目或方程的一些关键字就可以判断了。比如表达式里边如果有小数的,那么输出结果一般也是小数;如果题目是问“多少辆”、“多少个”、“多少人”之类的,那么输出的都是整数;如果直接问“几分之几”或“百分之几”的,那么相应地就是分数或百分数了。
比较困难是应该是取整类题目,比如“每盒蛋糕 7.90 元,50 元最多可以买多少盒蛋糕?”要求我们对 50/7.90 进行下取整,但有时候则是上取整。不过让笔者很意外的是,ape210k 里边并没有取整类题目,所以也就不存在这个问题。如果遇到有取整的数据集,如果规则判断起来比较困难,那么最直接的方法就是把取整符号也加入到 equation 中让模型去预测。
第二步看起来有点复杂,主要是分数的场景,一般读者可能不知道如何让式子保留分数运算结果,如果直接 eval('(1+2)/4'),那么得到的是 0.75(Python3),但有时我们希望得到的是分数结果 3/4。
事实上,保持分数的运算属于 CAS 的范畴(Computer Algebra System,计算机代数系统),说白了就是符号运算而不是数值运算,而 Python 中刚好也有这样的工具,那就是 SymPy [5] ,利用 SymPy 就能达到我们的目的了。具体请看下面的例子:
from sympy import Integer
import re
r = (Integer(1) + Integer(2)) / Integer(4)
print(r) # 输出是 3/4 而不是 0.75
equation = '(1+2)/4'
print(eval(equation)) # 输出是 0.75
new_equation = re.sub('(\d+)', 'Integer(\\1)', equation)
print(new_equation) # 输出是 (Integer(1)+Integer(2))/Integer(4)
print(eval(new_equation)) # 输出是 3/4

文章小结
本文介绍了用 Seq2Seq 模型做数学应用题的一个 baseline,主要思路就是通过“BERT+UniLM”直接将问题转换为可 eval 的表达式,然后分享了一些结果标准化的经验。通过 BERT Large 模型的 UniLM,我们达到了73%+的准确率,超过了原论文开源的结果。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






