
题目: CodeBERT: A Pre-Trained Model for Programming and Natural Languages
摘 要:
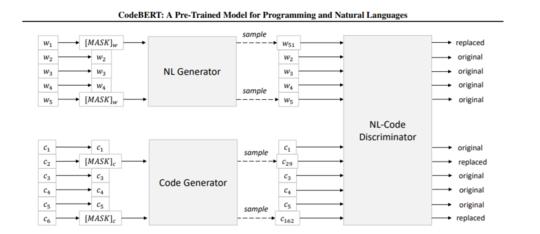
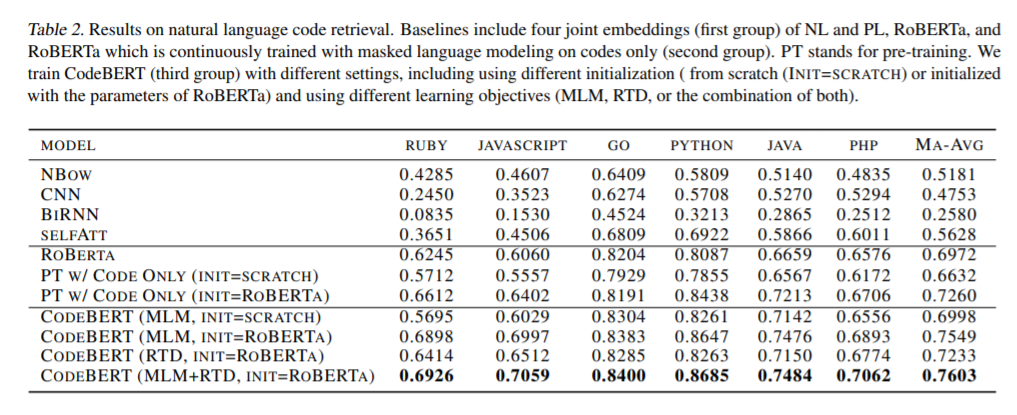
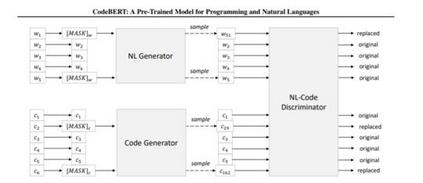
本文提出了一种用于编程语言(PL)和自然语言(NL)的预训练模型CodeBERT。CodeBERT学习了支持下游NL-PL应用程序(如自然语言代码研究、代码文档生成等)的通用表示形式。我们使用基于变压器的神经结构来开发CodeBERT,并使用混合目标函数来训练它,该混合目标函数合并了替换令牌检测的训练前任务,即检测从生成器中采样的可信替代。这使我们能够利用NL-PL对的双峰数据和单峰数据,前者为模型训练提供输入标记,而后者有助于更好地学习生成器。我们通过微调模型参数来评估CodeBERT在两个NL-PL应用程序上的性能。结果表明,CodeBERT在自然语言代码搜索和代码文档生成任务方面都实现了最先进的性能。此外,为了研究在CodeBERT中学习的知识的类型,我们构造了一个用于NL-PL探测的数据集,并在一个预先训练的模型的参数固定的零距离设置中进行评估。结果表明,CodeBERT在NL-PL探测方面的性能优于之前的预训练模型。
成为VIP会员查看完整内容
相关内容

专知会员服务
36+阅读 · 2020年5月20日
Arxiv
7+阅读 · 2018年1月23日



相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年1月23日