机器学习中的编码器-解码器结构哲学
导言
机器学习中体现着各种工程和科学上的哲学思想,大的有集成学习,没有免费午餐,奥卡姆剃刀;小的有最大化类间差异、最小化类内差异。对于很多问题,存在着一类通行的解决思路,其中的一个典型代表就是“编码器-解码器”结构。这一看似简单的结构,背后蕴含的工程思想却非常值得我们学习和品味。
在这篇文章中,我们将各种算法中采用的这一思想贯通起来介绍,以更好的形成脉络。限于篇幅,无法做非常详细的介绍,本文所讲的算法在《机器学习与应用》,雷明著,清华大学出版社一书中大都有详细的讲解。其中PCA位于“第7章-数据降维”,自动编码器位于“第14章-深度学习概论”,全卷积网络位于“第15章-卷积神经网络”,序列到序列学习位于“第16章-循环神经网络”。编码器CNN-解码器RNN位于“第16章-循环神经网络”,编码器RNN-解码器CNN位于“第17章-生成对抗网络”。变分自动编码器在后续的版本中可能会加入,此书在持续优化中,对于读者提出的第一版存在的问题,下一版会做大幅度的改进,敬请关注!
编码器-解码器结构在我们的日常生活中并不陌生。电话就是最典型的例子,它将声音信号编制成电信号,经过传输之后,在另外一端再将电信号恢复成声音信号。这样,对方就能在千里之外听到你的声音。在这里,电信号是声音信号的另外一种表示,这是物理上的变换,解码和编码通过硬件实现。
在机器学习中,很多问题可以抽象出类似的模型:
机器翻译。将一种语言的句子转化成另外一种语言的句子。
自动摘要。为一段文字提取出摘要。
为图像生成文字解说。将图像数据转化成文字数据。
-
根据一段文字描述生成图像。这是上面问题的反过程,将文字转化成图像。
其它的例子我们就不一一列举。在这些问题中,我们需要将输入数据转化成另外一种输出数据,二者之间有概率关系。例如,对于机器翻译来说,二者有相同的语义。
直接用一个函数完成这个转化 y=f(x)可能会存在困难。例如对机器翻译来说输入和输出的长度是不固定的,二者还可能不相等。因此我们需要曲线救国,先将输入数据x转化成一种中间数据z,再从z映射出y。这就是编码器、解码器结构。就像我们无法将声音直接传送到很远的地方去一样,借助于电信号这样的中间表示,我们可以更好的完成任务。接下来将列举出机器学习中一些典型的编码器-解码器结构算法。
从PCA说起
主成分分析是一种经典的无监督数据降维算法。它将一个高维的向量x映射成一个低维的向量y,前提条件是y很好的保留了x的主要信息。在做数据降维时,我们执行如下变换
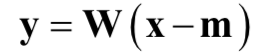
计算过程很简单,先减掉均值向量,然后左乘投影矩阵即可。其中m是样本集的均值向量,W是投影矩阵,通过样本集计算得到,具体的原理可以参考PCA的教程。这一投影过程的作用类似于编码器,将高维向量x编码成低维向量y。
有些时候,我们需要从降维后的向量y重构出原始的向量x,这可以通过数据重构算法实现,计算公式很简单
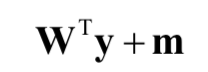
这刚好和投影算法相反,是先左乘投影矩阵W的转置, 然后加上均值向量。在这里,重构算法可以看作是解码器,从降维后的向量解码出原始的信号。
自动编码器
自动编码器(Auto-Encoder,简称AE)是一种特殊的神经网络,用于特征提取和数据降维络。最简单的自动编码器由一个输入层,一个隐含层,一个输出层组成。隐含层的映射充当编码器,输出层的映射充当解码器。
训练时编码器对输入向量进行映射,得到编码后的向量;解码器对编码向量进行映射,得到重构后的向量,它是对输入向量的近似。编码器和解码器同时训练,训练的目标是最小化重构误差,即让重构向量与原始输入向量之间的误差最小化,这与PCA非常类似。因此样本x的标签值就是样本自身。
训练完成之后,在预测时只使用编码器而不再需要解码器,编码器的输出结果被进一步使用,用于分类,回个等任务。
下图是自动编码器的一个例子。输入数据是6维向量,因此输入层有6个神经元;隐含层有3个神经元,对应编码后的向量;输出层有6个神经元,对应重构后的向量。
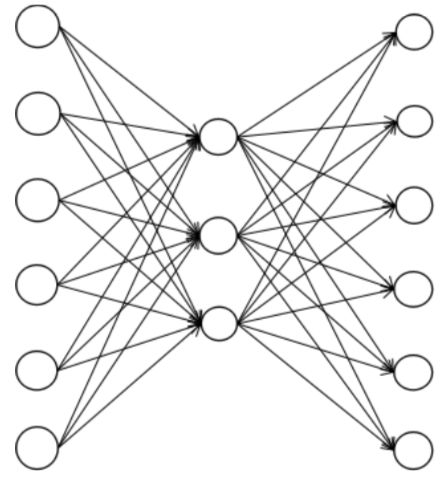
训练时先经过编码器得到编码后的向量,再通过解码器得到解码后的向量,用解码后的向量和原始输入向量计算重构误差。如果编码器的映射函数为h,解码器的映射函数为g,训练时优化的目标函数为:
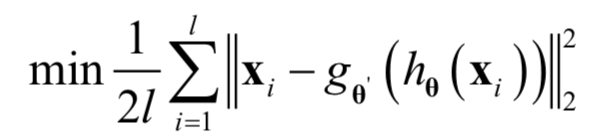
这里采用了欧氏距离损失。其中l为训练样本数,θ和θ’是分别是编码器和解码器要确定的参数。
变分自动编码器
变分自动编码器(Variational Auto-Encoder,简称VAE)[1]是一种深度生成模型,用于生成图像,声音之类的数据,类似于生成对抗网络(GAN)。虽然也叫自动编码器,但和标准的自动编码器有很大的不同,二者用于完全不同的目的。
现在考虑数据生成问题,如写字,最简单的是写出MNIST数据集这样的手写数字

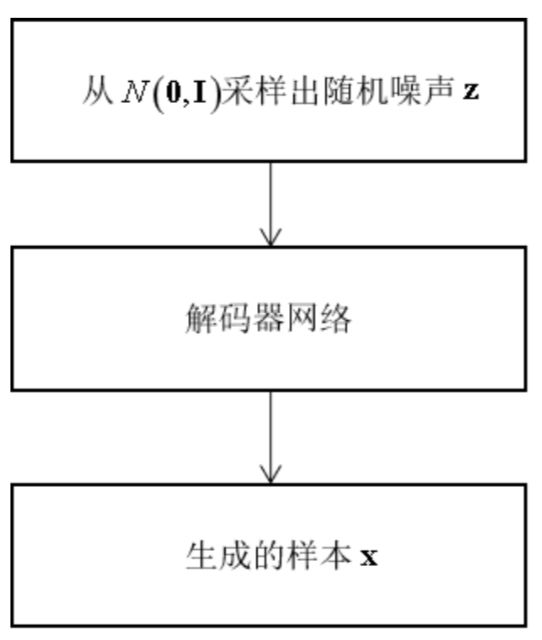
如果我先收集一些训练样本,然后让算法原样输出它们,当然也可以完成写字,但这样生成的样本完全就没用多样性了。因此一般的解决思路是先生成一些随机数,然后对其进行变换,生成我们想要的复杂的样本数据。这一过程如下图所示
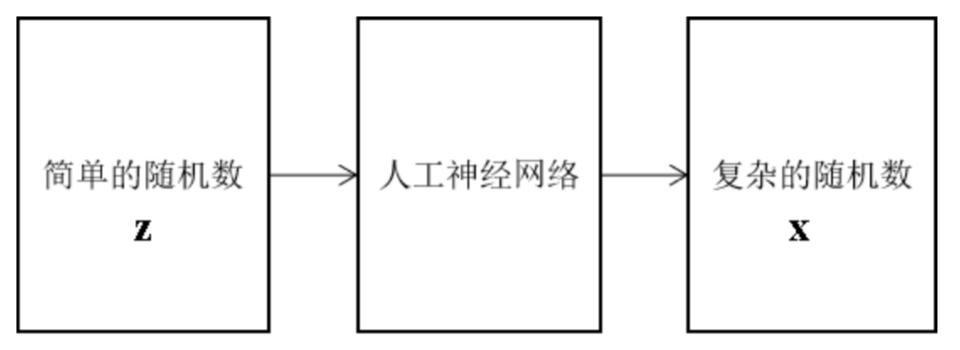
问题是,这个简单的随机数,该怎么生成呢,应该服从何种概率分布?它们可以代表笔画特征,字体宽度,清晰角度,字体类型等信息,但如果这样人工设计,一是费时费力,二是具有局限性。因此我们会想到:能不能从文字图像中先学习中这些特征,然后对这些特征进行随机扰动,生成新的样本?变分自动编码器就采用了这种思路。其结构如下图所示
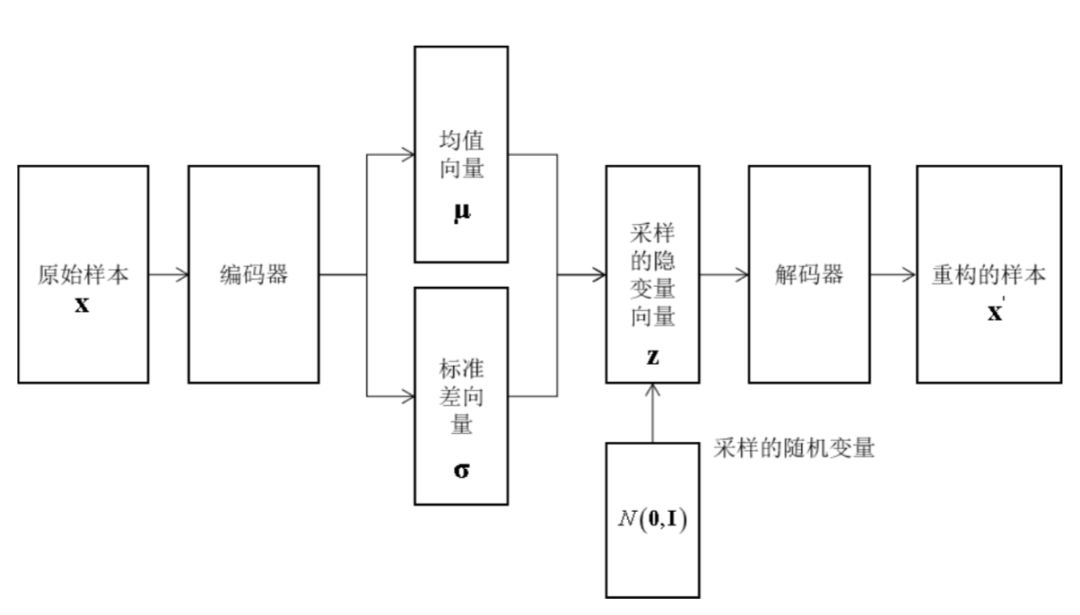
这里的隐变量可以看做是从图像中学习得到的特征。同样的,编码器和解码器同时训练,训练时的目标是下面方程的右端
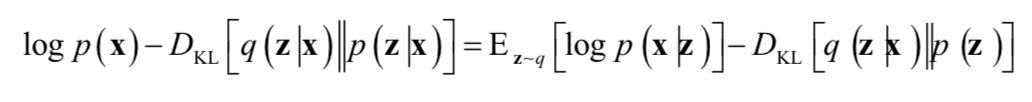
由于原理较为复杂,在这里我们不做深入的讲解。训练完成之后,预测阶段可以直接生成样本。具体做法是,从正态分布z~N(0,I)产生一个随机数,然后送入解码器中,得到预测结果,即为生成的样本。此时已经不再需要编码器,另外需要强调的是,也不需要对随机数进行均值和方差变换。
密集预测-全卷积网络
图像分割的目标是确定图像中每个像素属于什么物体,即对所有像素进行分类,是一个逐像素预测的密集预测问题。卷积网络在进行多次卷积和池化后会缩小图像的尺寸,最后的输出结果无法对应到原始图像中的每一个像素,卷积层后面接的全连接层将图像映射成固定长度的向量,这也与分割任务不符。针对这两个问题设计出了全卷积网络(FCN)[2][3],它全掉了卷积神经网络中的全连接层,全部用卷积代替,为了从前面的卷积特征图像得到与原始输入图像尺寸相等的输出图像,采用了反卷积运算。
这种模型从卷积特征图像预测出输入图像每个像素的类别。网络能够接受任意尺寸的输入图像,并产生相同尺寸的输出图像,输入图像和输出图像的像素一一对应。这种网络支持端到端、像素到像素的训练。
FCN的前半部分是卷积层和池化层,充当编码器,从输入图像中提取特征。网络的后半部分是反卷积层,充当解码器,从特征中解码出结果图像。典型的网络结构如下图所示

文献[3]提出的SegNet语义分割网络更为复杂。网络的前半部分是编码器,由多个卷积层和池化层组成。网络的后半部分为解码器,由多个上采样层和卷积层构成。解码器的最后一层是softmax层,用于对像素进行分类。
编码器网络的作用是产生有语义信息的特征图像;解码器网络的作用是将编码器网络输出的低分辨率特征图像映射回输入图像的尺寸,以进行逐像素的分类。整个网络的结构如下图所示
序列到序列学习
有些问题输入序列的长度和输出序列不一定相等,而且我们事先并不知道输出序列的长度。以机器翻译为例,将一种语言的句子翻译成另外一种语言之后,句子的长度即包括的单词数量一般是不相等的。
英文句子“what's your name”是3个单词组成的序列,翻译成中文为“你叫什么名字”,由4个汉字词组成。标准的RNN无法处理这种输入序列和输出序列长度不相等的情况,解决这类问题的一种方法是序列到序列学习(Sequence to Sequence Learning,简称seq2seq)技术[4]。
seq2seq由两个循环神经网络组成,它能实现从一个序列到另外一个序列的映射,两个序列的长度可以不相等。seq2seq框架包括两部分,分别称为编码器和解码器,它们都是循环神经网络。这里要完成的是从一个序列到另外一个序列的预测:
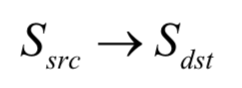
前者是源序列,后者是目标序列,二者的长度可能不相等。
用于编码器的网络接受输入序列x1,...,xT,最后T时刻产生的隐含层状态值hT作为序列的编码值,它包含了时刻1到T输入序列的所有信息,在这里我们将其简写为v,这是一个固定长度的向量。用于解码的网络每个时刻的输入值为v和yt,它可以计算目标序列y1,...,yT`的条件概率
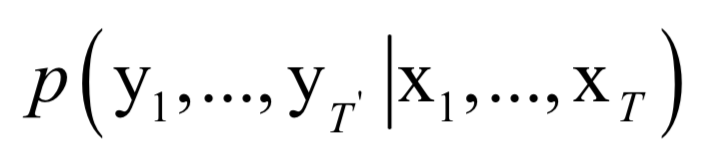
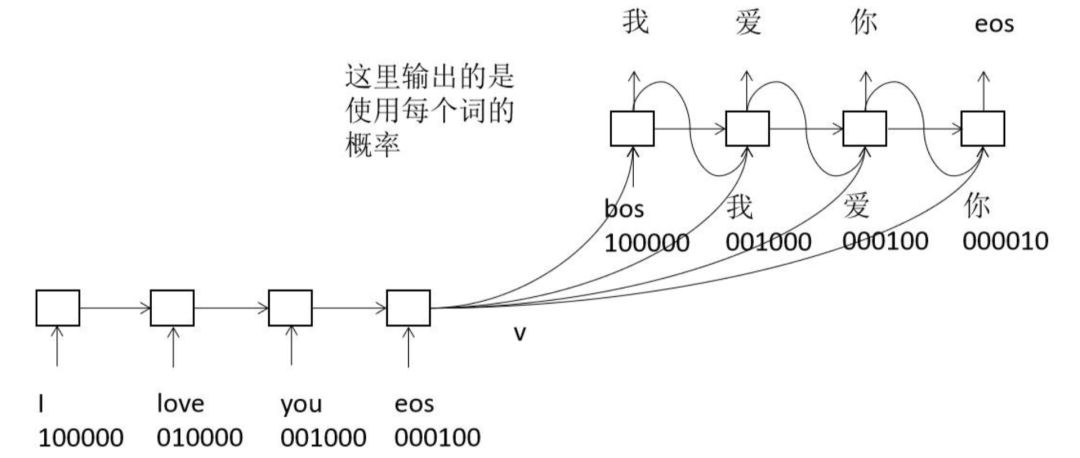
对于机器翻译而言,编码器依次接收源语言句子的每个词,最后得到语义向量v。解码器首先输入bos,即句子的开始,根据它和v预测出下一个词使用每个词的概率,挑选出概率最大的一个或几个词。接下来将这个词与v送入解码器,得到几下一个此,如此循环,直到得到eos,即句子的结尾,翻译结束。这里使用了集束搜索(beam search)技术。下图是用seq2seq做机器翻译的原理示意图。
CNN与RNN的结合
前面介绍的FCN是CNN和CNN的结合,seq2seq是RNN和RNN的结合。在编码器-解码器框架中,CNN和RNN可以杂交,谁充当编码器,谁充当解码器,都是可以的,可灵活组合用于各种不同的任务。
从图像到文字
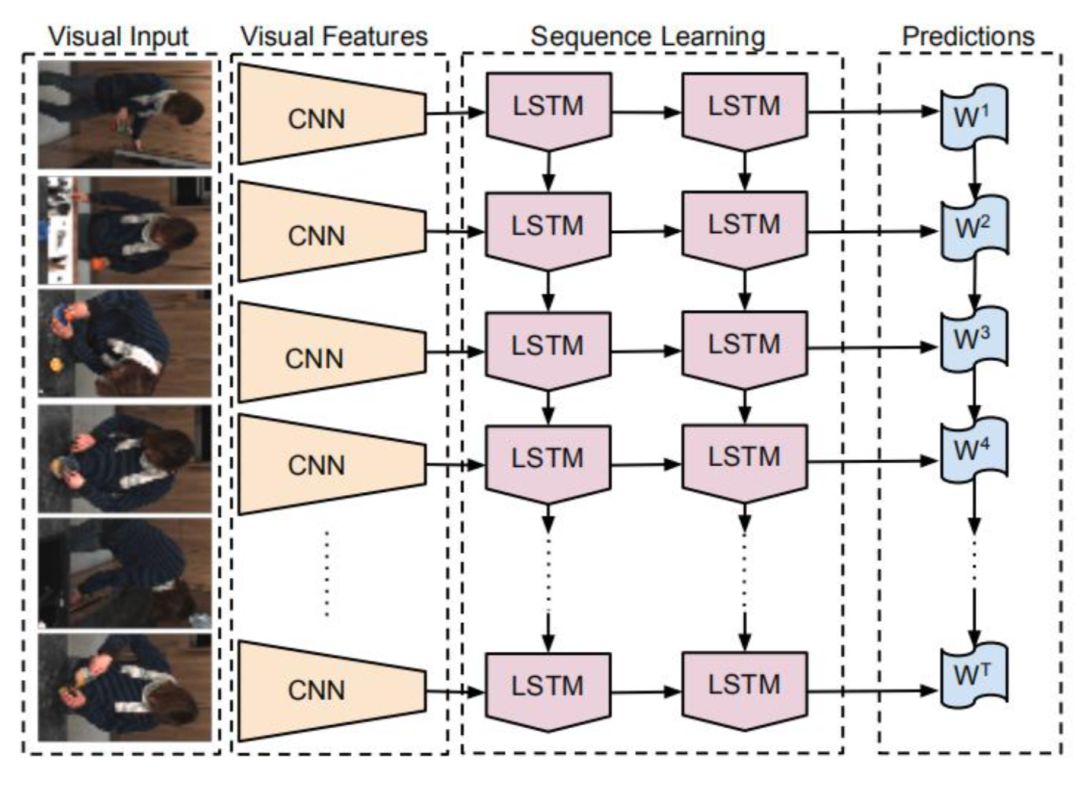
这类任务是指为图像或视频生成文字解说[5]。这是从图像到文字的映射,在这里,CNN是编码器,用于提取出图像的语义特征。RNN充当解码器,其输入为图像的语义特征,输出不固定长度的文字序列。这一结构如下图所示
从文字到图像
这是上一类任务的反过程。现在面临一个相反的问题:由一段文字来生成图像。文献[6]提出了一种用循环神经网络和深度卷积生成对抗网络解决这一问题的方法,将视觉概念从文字变成像素表示。下图是一些结果

和机器翻译类似,采用编码器-解码器框架。第一步是将一段文字转换成向量表示,即文字的语义信息,通过一个深度卷积网络和一个循环神经网络为文本产生向量输出,这个输出和图像对应。
算法的第二步是在第一步生成的文本向量基础上训练一个生成对抗网。在这里生成模型是一个深度卷积网络,负责生成图像。生成器网络实现的映射为
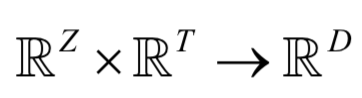
其中T为文字描述向量化后的向量维数,Z为随机噪声的维数,D是生成的图像的维数。生成网络接受随机噪声向量和文字的特征向量作为输入,输出指定大小的图像。
参考文献
[1] Carl Doersch. Tutorial on Variational Autoencoders. 2016, arXiv: Machine Learning.
[2] Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation. Computer Vision and Pattern Recognition, 2015.
[3] Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.
[4] Ilya Sutskever, Oriol Vinyals, Quoc V Le. Sequence to Sequence Learning with Neural Networks. neural information processing systems. 2014.
[5] J.Donahue, L.A.Hendricks, S.Guadarrama, M.Rohrbach, S.Venugopalan, K.Saenko, and T.Darrell. Long-term recurrent convolutional networks for visual recognition and description. arXiv preprint arXiv:1411.4389, 2014.
[6] S Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele,Honglak Lee. Generative Adversarial Text to Image Synthesis. international conference on machine learning, 2016.
@SIGAI
版权声明
本文版权归《SIGAI》,转载请自行联系。

点击下方图片或点击文末阅读原文,了解课程详情

历史文章推荐:
深度神经网络模型训练中的最新tricks总结【原理与代码汇总】
基于深度学习的艺术风格化研究【附PDF】
最新国内大学毕业论文LaTex模板集合(持续更新中)
基于深度学习的图像超分辨率最新进展与趋势【附PDF】
t-SNE:最好的降维方法之一
年龄估计技术综述
钱学森:再谈开放的复杂巨系统
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
语音关键词检测方法综述【附PPT与视频资料】
点击下方阅读原文了解课程详情↓↓
若您觉得此篇推文不错,麻烦点点在看↓↓