
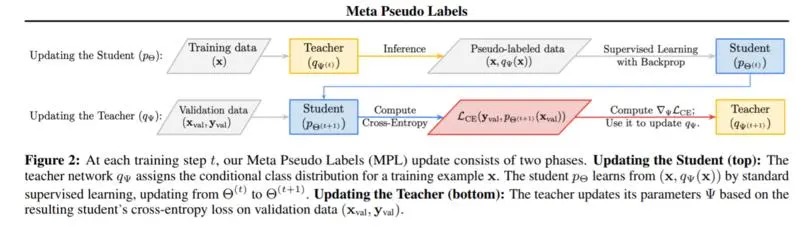
许多深度神经网络的训练算法可以解释为最小化网络预测与目标分布之间的交叉熵损失。在监督学习中,这种目标分布通常是一个one hot向量。在半监督学习中,这种目标分布通常是由一个预先训练好的教师模型来训练主网络生成的。在这项工作中,我们没有使用这种预定义的目标分布,而是证明了学习根据主网络的学习状态来调整目标分布可以获得更好的性能。特别地,我们提出了一种有效的元学习算法,该算法鼓励教师以改善主网络学习的方式来调整训练样本的目标分布。教师通过在一个预定的验证集上评估主网络计算出的策略梯度来更新。我们的实验证明了在强基线上的重大改进,并在CIFAR-10、SVHN和ImageNet上建立了最新的性能。例如,使用小型数据集上的ResNets,我们在CIFAR-10上实现了96.1%(包含4,000个标记示例),在ImageNet上实现了73.9%(包含10%示例)的top-1。同时,在完整的数据集上加上额外的未标记数据,我们在CIFAR-10上获得98.6%的准确率,在ImageNet上获得86.9%的top-1的准确率。
成为VIP会员查看完整内容
相关内容

专知会员服务
17+阅读 · 2019年11月17日
Arxiv
8+阅读 · 2020年4月13日
Arxiv
12+阅读 · 2018年1月29日
相关VIP内容
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日
Arxiv
12+阅读 · 2018年1月29日