NLP自然语言处理(二)——基础文本分析
这是NLP自然语言处理学习系列的第二篇,前面我们主要是从“词”的角度,介绍了jieba分词、词性标注及关键词提取的一些基础问题。下面主要从“语义”角度,总结下如何运用R进行基础的文本分析。前言:基础文本分析的主要步骤:
运用Rwordseg包进行中文分词
运用tm包生成语料库并进行清洗操作
创建文档-词频矩阵(词频表)
进行文本分析(主题模型、聚类分析等)
文本分析可视化(词云、社交网络关系图等)
一、运用Rwordseg包进行中文分词
前面我们讲过运用jieba分词技术进行中文分词处理,其实运用得最多的,是运用Rwordseg包进行中文分词。就像通关打怪兽一样,进行NLP自然语言处理,打的打一个怪兽就是对Rwordseg包进行安装了,它依赖rJava包,因此需要预先安装Java环境。它的安装可见参考资料【1】。
用Rwordseg包分词主要是segmentCN函数,例子如下。显然“京津冀”属于一个词,如此我们可运用insertWords函数,临时添加分词词典。如果想载入自定义词典,可运用installDict函数【2】。
我们再以某新闻稿为例,进行文本分析。library(Rwordseg)
segmentCN("京津冀协同发展")## [1] "京津" "冀" "协同" "发展"insertWords("京津冀")
segmentCN("京津冀协同发展")## [1] "京津冀" "协同" "发展"library(Rwordseg)
bzc <- read.csv("bzc.csv",header = TRUE,stringsAsFactors = FALSE)
sentence <- as.vector(bzc$contents)
#下面都是为了清除文本中的垃圾
sentence <- gsub("NA", "", sentence)
#将"NA"符号替换
sentence <- gsub("[[:digit:]]*", "", sentence)
#清除数字及字母[a-zA-Z]
sentence <- gsub("[a-zA-Z]", "", sentence)
sentence <- sentence[!is.na(sentence)]
x <- lapply(sentence, function(x) segmentCN(x, nature = TRUE))
msgWords <- as.data.frame(cbind(rep(bzc[,2], unlist(lapply(x, length))),
unlist(x), names(unlist(x))), stringsAsFactors = F)
rownames(msgWords) <- seq(1:length(msgWords[,1]))
names(msgWords) <- c("Docid", "Term","Nature") 生成一个分词列表,一共7篇文章。
二、运用tm包生成语料库并进行清洗操作
2.1去掉停词操作
在生成语料库前,可进行分词的清洗工作,包括删除数字、字母、特殊符号及去掉“啊、的、了、得、好”等停止词。当然也可以在生成完语料库后,运用tm包tm_mp函数进行操作,下面会提到。
经过清洗操作由2310个词,清洗为1621个词。#载入stopword文件
stopwords <- read.csv("stopword_CN.csv", header = T, sep = ",")
msgWords <- msgWords[!(msgWords$Term %in% stopwords$term),]#去除停用词现在我们先来看看清洗后,创建个词云,查看词的分布library(tmcn)
library(wordcloud)
Freq_word <- getWordFreq(string = msgWords$Term)
wordcloud(words = Freq_word$Word, freq = Freq_word$Freq,max.words = 40,random.color = TRUE, colors = rainbow(n = 7))
可以看到,效果并不是很好,一些我们不需要的词,并未被删除,如是一是可以在stopwords停词表中添加些需要停止的词,二是自创一个停词表。我们试试第二种方法。#新建停止词
stopwords_new <- c('会','处','局','市','年','二','二级','中','副')
#排除停止词
Term <- msgWords[!(msgWords$Term %in% stopwords_new),]
2.2 创建语料库
文本处理过程首先要拥有分析的语料(text corpus),因此分词过后,首先要创建语料库。tm包可以说是NLP最通用的框架了,在tm中主要的管理文件的结构被称为语料库(Corpus),代表了一系列的文档集合。通过Corpus函数,创建动态语料库【3】。library(tm)
corpus1 <- Corpus(VectorSource(x))
#inspect(corpus1) #查看语料库
#writeCorpus(corpus1)#保存为本地文件2.3 运用tm包对语料库进行清洗操作
主要使用tm_map函数处理语料的传入函数,主要如下。由于tm包没有中文停词,需要运用到tmcn包中的stopwordsCN函数。

library(tmcn)
#去除标签,转换为纯文本
corpus1 <- tm_map(corpus1,PlainTextDocument)
#删除空白
corpus1 <- tm_map(corpus1,stripWhitespace)
#去掉停止词
#corpus1 <- tm_map(corpus1,removeWords, stopwordsCN)
#词干提取
#corpus1 <- tm_map(corpus1,stemDocument)三、创建文档-词频矩阵(词频表)
创建一个文档-词频矩阵是文本挖掘的基础,可通过tm包创建,或自定义词频表创建。3.1 tm包创建
dtm <- DocumentTermMatrix(corpus1)
#查看文档#inspect(dtm)
#Non-/sparse entries: 482/2598 ---非0/是0
#Sparsity : 84% ---稀疏性 稀疏元素占全部元素的比例 #Maximal term length: 23 ---切词结果的字符最长那个的长度
#Weighting : term frequency (tf)---词频率 #如果需要考察多个文档中特有词汇的出现频率,可以手工生成字典,并将它作为生成矩阵的参数
#d<-c("质量","卫生","规范","推进")
#以这几个关键词为查询工具
#inspect(DocumentTermMatrix(corpus1,control=list(dictionary=d)))在文档词频矩阵上操作
#找出次数超过50的词
findFreqTerms(dtm, 10) ## [1] "京津冀" "快速\n检测\n工作" "快速\n检测\n质量"#找出与‘京津冀’单词相关系数在0.9以上的词
findAssocs(dtm,"京津冀",0.98)## $京津冀
## 计生委\n综合
## 0.98#因为生成的矩阵是一个稀疏矩阵,再进行降维处理,之后转为标准数据框格式 #我们可以去掉某些出现频次太低的词。
dtm1<- removeSparseTerms(dtm, sparse=0.6)
inspect(dtm1) ## <<DocumentTermMatrix (documents: 7, terms: 8)>>
## Non-/sparse entries: 26/30
## Sparsity : 54%
## Maximal term length: 8
## Weighting : term frequency (tf)
##
## Terms
## Docs 计生委\n综合 京津冀 快\n检 快速\n检测\n工作
## character(0) 1 3 0 4
## character(0) 0 0 1 0
## character(0) 0 0 4 2
## character(0) 0 0 0 0
## character(0) 0 0 0 0
## character(0) 2 10 1 3
## character(0) 1 5 1 2
……data <- as.data.frame(inspect(dtm1)) row.names(data)<- 1:73.2 手动制作頻数表
library(dplyr)
library(reshape2)
#建立一个全为1的列,方便统计
Logic <- rep(1, length(msgWords[,1]))
msgWords <- as.data.frame(cbind(msgWords, Logic), stringsAsFactors = F)
msgTerm <- dcast(msgWords, Term ~ Docid, value.var = "Logic")
#制作词频表
msgTerm <- melt(msgTerm, id = 1)
msgTerm <- msgTerm[which(msgTerm$value > 0),]
names(msgTerm) <- c("Term", "Docid", "Freq")
head(msgTerm)## Term Docid Freq
## 5 包括 2016年10月18日 1
## 7 保证 2016年10月18日 3
## 11 本次 2016年10月18日 3
## 15 标准 2016年10月18日 1
## 20 补充 2016年10月18日 1
## 23 采样 2016年10月18日 1四、进行文本分析(主题模型、聚类分析等)
聚类分析
data.scale <- scale(data)
d <- dist(data.scale, method = "euclidean")
fit <- hclust(d, method="ward.D")
#绘制聚类图
plot(fit,main ="文件聚类分析",hang = -1) 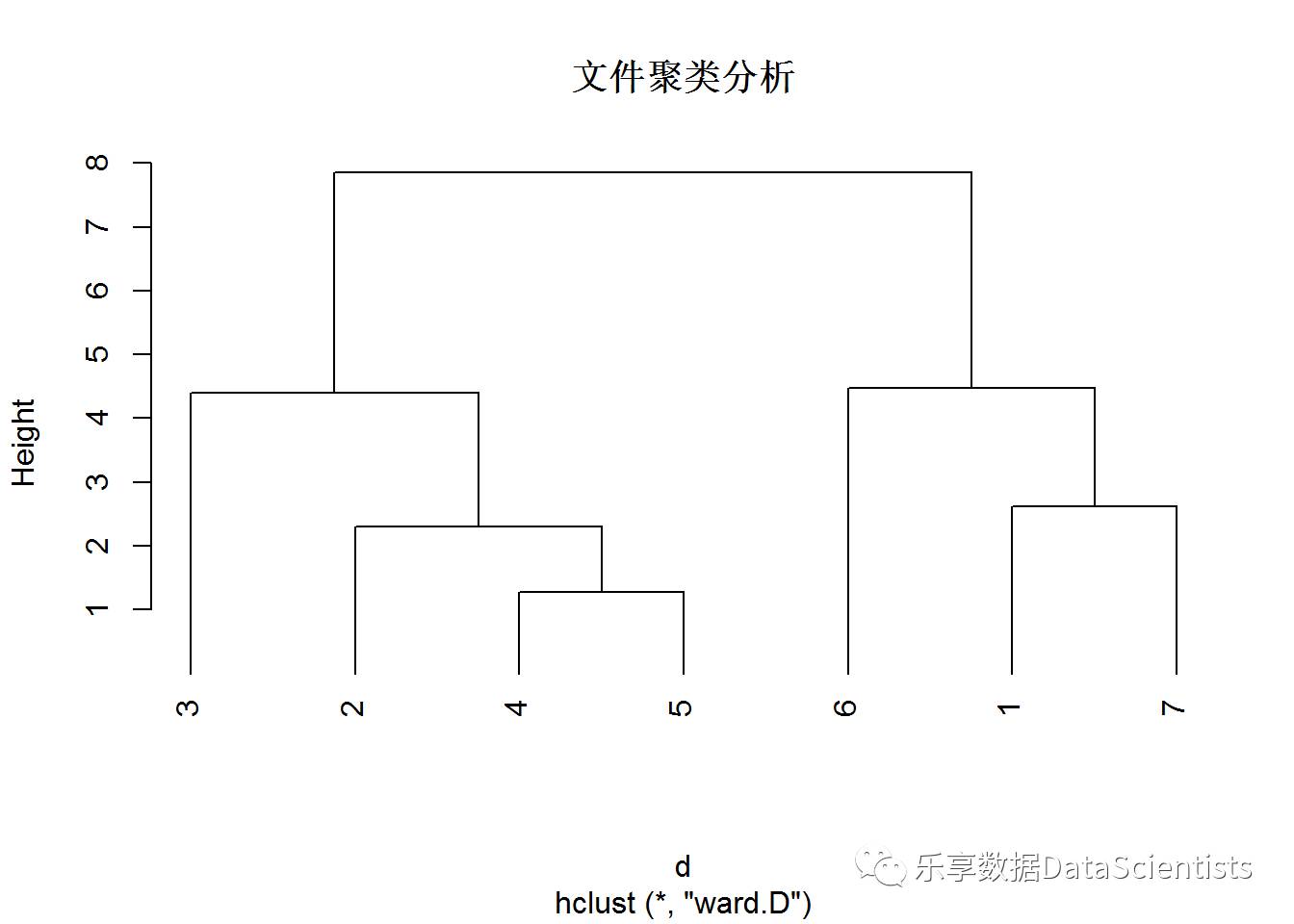
主题分析
library(topicmodels)
ctm <- CTM(dtm1, k = 2)
terms(ctm, 2, 0.05)## Topic 1 Topic 2
## [1,] "快\n检" "京津冀"
## [2,] "市\n卫生" "快速\n检测\n工作"五、可视化
除了以上的词云展示,还可以进行LDA主题分析后,进行社交网络关系展示。如下是进行可视化后图形。
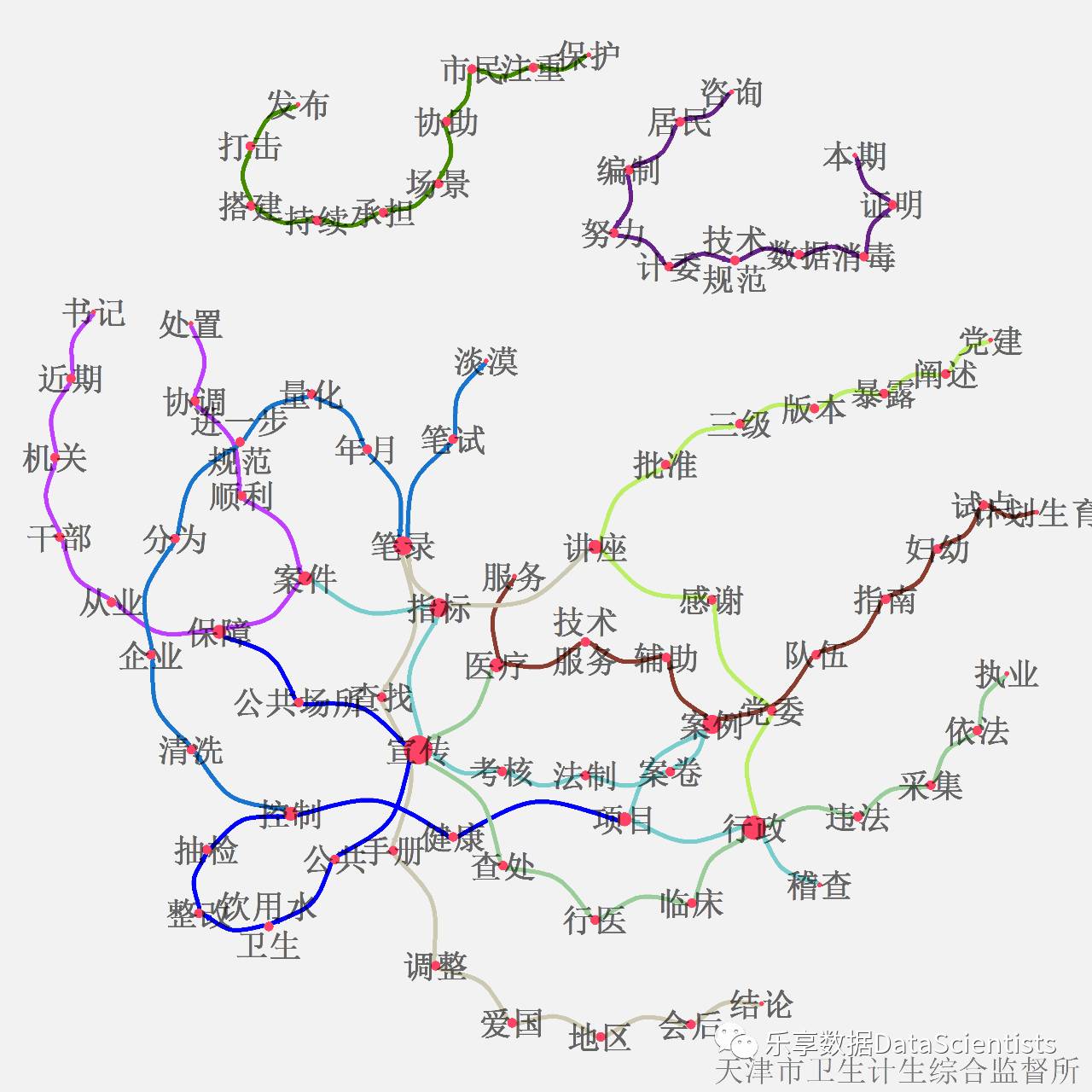
写在最后
本篇是自然语言处理(NLP)的第二篇,其中主题模型并未详细总结,在下面一篇中将重点介绍LDA主题模型、情感分析以及深度学习Word2vec进行词嵌入学习。参考资料
Rwordseg、Rweibo、tm的安装http://www.dataguru.cn/thread-482875-1-1.html
【R文本挖掘】中文分词Rwordseghttp://blog.163.com/zzz216@yeah/blog/static/162554684201412895732586/
ChinaR2013-中文文本挖掘和tmcn包http://wenku.it168.com/d_001393502.shtml
利用word2vec对关键词进行聚类http://blog.csdn.net/zhaoxinfan/article/details/11069485
深度学习 word2vec 笔记http://www.open-open.com/lib/view/1420689477515#articleHeader0
要想获取分析代码,可查看原文,进入本人的GitHubhttps://github.com/Alven8816查看下载,或通过本人邮箱yuwenhuajiayou@sina.cn与本人联系
”乐享数据“个人公众号,不代表任何团体利益,亦无任何商业目的。任何形式的转载、演绎必须经过公众号联系原作者获得授权,保留一切权力。欢迎关注“乐享数据”。

登录查看更多
相关内容

Arxiv
3+阅读 · 2019年6月26日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年6月26日