【纽约大学】贝叶斯深度学习和泛化性的概率观点,附27页PPT下载
【导读】纽约大学的Andrew Gordon Wilson和Pavel Izmailov在论文中从概率角度的泛化性对贝叶斯深度学习进行了探讨。贝叶斯方法的关键区别在于它是基于边缘化,而不是基于最优化的,这为它带来了许多优势。
纽约大学的论文《Bayesian Deep Learning and a Probabilistic Perspective of Generalization》从概率角度的泛化性对贝叶斯深度学习进行了探讨。论文的地址为:
https://arxiv.org/pdf/2002.08791.pdf
下面我们简单介绍一下文章的内容。
摘要
贝叶斯方法的关键区别是边缘化,而不是使用单一的权重设置。贝叶斯边缘化可以特别提高现代深度神经网络的准确性和校准,这是典型的不由数据完全确定,可以代表许多令人信服的但不同的解决方案。我们证明了深度集成为近似贝叶斯边缘化提供了一种有效的机制,并提出了一种相关的方法,通过在没有显著开销的情况下,在吸引域边缘化来进一步改进预测分布。我们还研究了神经网络权值的模糊分布所隐含的先验函数,从概率的角度解释了这些模型的泛化性质。从这个角度出发,我们解释了那些对于神经网络泛化来说神秘而独特的结果,比如用随机标签来拟合图像的能力,并证明了这些结果可以用高斯过程来重现。最后,我们提供了校正预测分布的贝叶斯观点。
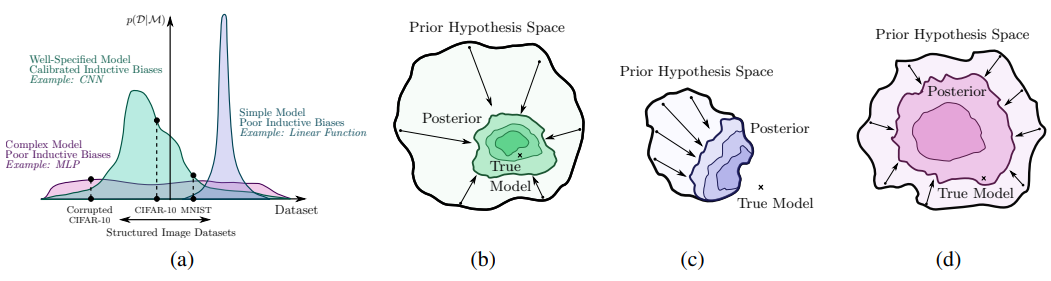
泛化性的概率观点
(a)理想情况下,模型支持大范围的数据集,但存在归纳偏差,为正在考虑的某一类问题提供了很高的先验概率。在CIFAR-10中,卷积神经网络CNN比线性模型和全连接的MLP更受欢迎(虽然我们不认为MLP模型通常具有较差的归纳偏差,但这里我们考虑的是一个涉及图像和一个非常大的MLP的假设示例)。
(b)通过表示一个大的假设空间,一个模型可以围绕一个真正的解决方案进行收缩,而在现实世界中,真正的解决方案往往是非常复杂的。
(c)如果支持被截断,模型将收敛到一个错误的解决方案。
(d)即使假设空间包含真理,一个模型也不会有效收缩,除非它也有合理的归纳偏差。
文章大致内容
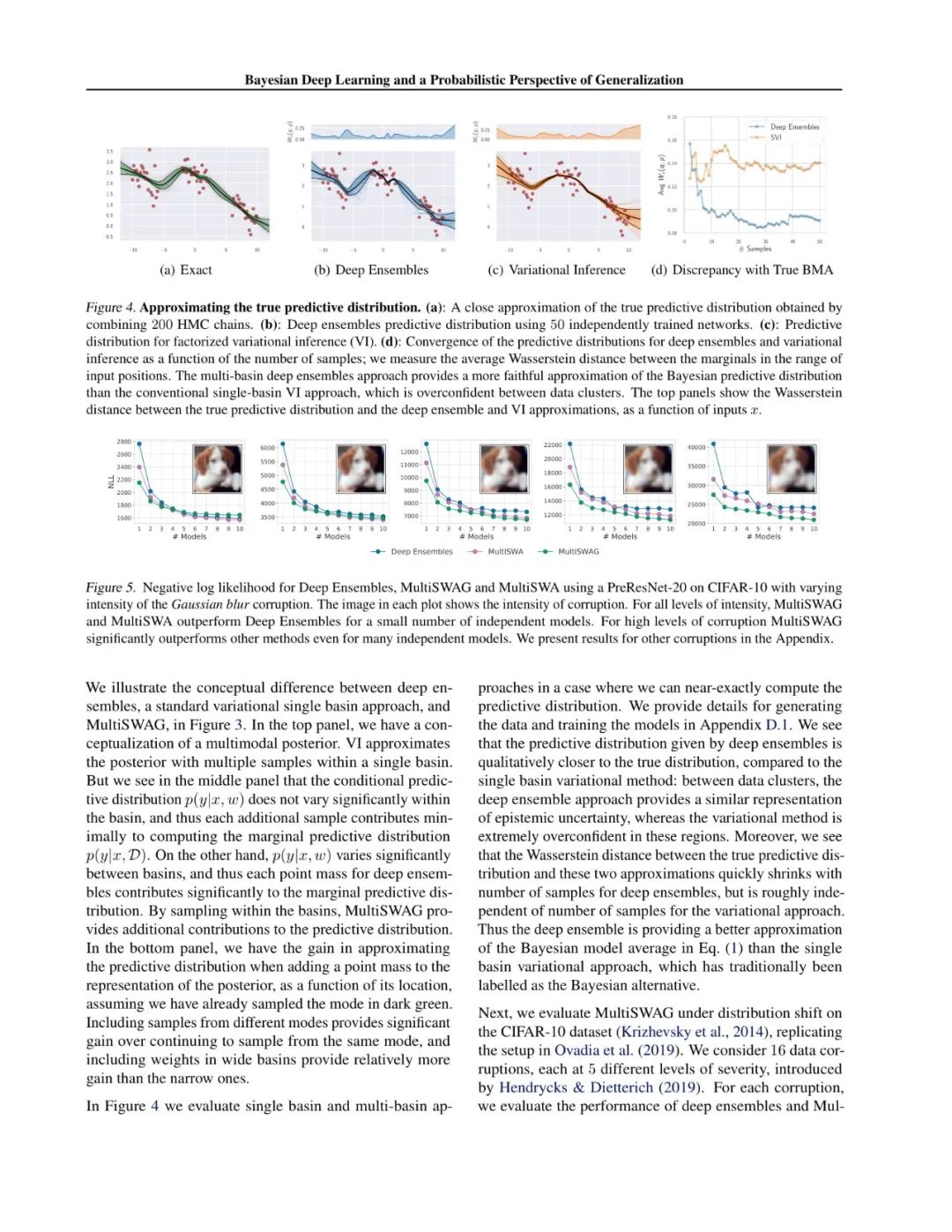
本文从概率角度的泛化性对贝叶斯深度学习进行了探讨。贝叶斯方法的关键区别在于它是基于边缘化,而不是基于最优化的,在这里我们用所有参数的后验概率加权来表示解决方案,而不是把所有的东西都押在一个参数设置上。神经网络通常不由数据完全确定,可以代表许多不同但高性能的模型,这对应着不同的参数设置,这正是边缘化将对精度和校准产生最大的影响。此外,我们还澄清了最近的深度集成并不是贝叶斯推理的竞争方法,而是一种强制性的贝叶斯边缘化机制。事实上,我们的经验证明,与标准贝叶斯方法相比,深度集成可以提供更好的贝叶斯预测分布近似值。我们进一步提出了一种新的方法,灵感来自于深度集成,它在吸引域边缘化,实现了性能的显著提高,并使用了相似的训练时间。
文章的目录如下:
简介
相关工作
贝叶斯边缘化
深度学习中边缘化的重要性
蒙特卡洛之外
深度集成是一种贝叶斯模型平均方法
边缘化的经验研究
神经网络先验
深度图像先验和随机网络特征
先验类别关联
CIFAR-10数据集上先验方差的影响
重新思考泛化性
讨论
贝叶斯神经网络先验的未来
“但这是真正的贝叶斯么?”
便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“BDLPPG” 就可以获取《Bayesian Deep Learning and a Probabilistic Perspective of Generalization》27页PDF专知下载链接索引








参考链接:
https://arxiv.org/pdf/2002.08791.pdf






