再谈变分自编码器VAE:从贝叶斯观点出发
作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前几天写了文章变分自编码器VAE:原来是这么一回事,从一种比较通俗的观点来理解变分自编码器(VAE),在那篇文章的视角中,VAE 跟普通的自编码器差别不大,无非是多加了噪声并对噪声做了约束。
然而,当初我想要弄懂 VAE 的初衷,是想看看究竟贝叶斯学派的概率图模型究竟是如何与深度学习结合来发挥作用的,如果仅仅是得到一个通俗的理解,那显然是不够的。
所以我对 VAE 继续思考了几天,试图用更一般的、概率化的语言来把 VAE 说清楚。事实上,这种思考也能回答通俗理解中无法解答的问题,比如重构损失用 MSE 好还是交叉熵好、重构损失和 KL 损失应该怎么平衡,等等。
建议在阅读变分自编码器VAE:原来是这么一回事后再对本文进行阅读,本文在内容上尽量不与前文重复。
准备
在进入对 VAE 的描述之前,我觉得有必要把一些概念性的内容讲一下。
数值计算 vs 采样计算
对于不是很熟悉概率统计的读者,容易混淆的两个概念应该是数值计算和采样计算,也有读者对三味Capsule:矩阵Capsule与EM路由出现过同样的疑惑。比如已知概率密度函数 p(x),那么 x 的期望也就定义为:

如果要对它进行数值计算,也就是数值积分,那么可以选若干个有代表性的点 x0<x1<x2<⋯<xn,然后得到:
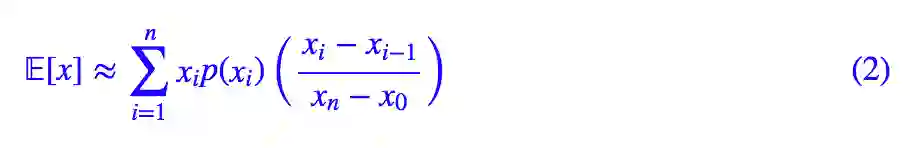
这里不讨论“有代表性”是什么意思,也不讨论提高数值计算精度的方法。这样写出来,是为了跟采样计算对比。如果从 p(x) 中采样若干个点 x1,x2,…,xn,那么我们有:
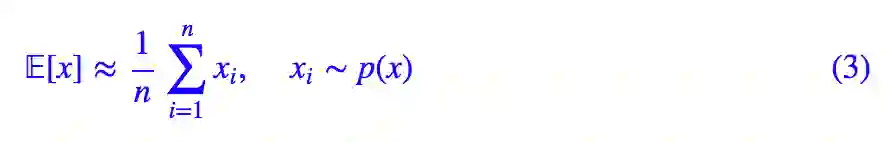
我们可以比较 (2) 跟 (3),它们的主要区别是 (2) 中包含了概率的计算而 (3) 中仅有 x 的计算,这是因为在 (3) 中 xi 是从 p(x) 中依概率采样出来的,概率大的 xi 出现的次数也多,所以可以说采样的结果已经包含了 p(x) 在里边,就不用再乘以 p(xi) 了。
更一般地,我们可以写出:
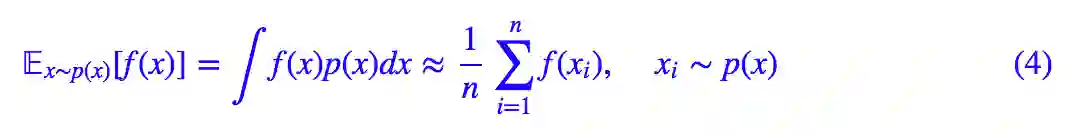
这就是蒙特卡洛模拟的基础。
KL散度及变分
我们通常用 KL 散度来度量两个概率分布 p(x) 和 q(x) 之间的差异,定义为:
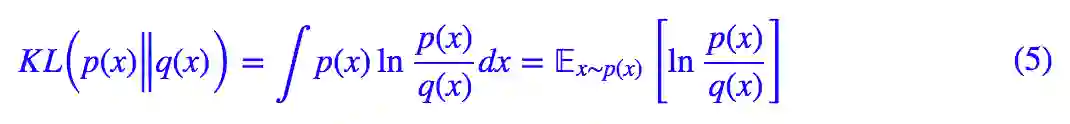
KL 散度的主要性质是非负性,如果固定 p(x),那么 KL(p(x)‖‖‖q(x))=0⇔p(x)=q(x);如果固定 q(x),同样有 KL(p(x)‖‖‖q(x))=0⇔p(x)=q(x),也就是不管固定哪一个,最小化 KL 散度的结果都是两者尽可能相等。
这一点的严格证明要用到变分法,而事实上 VAE 中的 V(变分)就是因为 VAE 的推导就是因为用到了 KL 散度(进而也包含了变分法)。
当然,KL 散度有一个比较明显的问题,就是当 q(x) 在某个区域等于 0,而 p(x) 在该区域不等于 0,那么 KL 散度就出现无穷大。
这是 KL 散度的固有问题,我们只能想办法规避它,比如隐变量的先验分布我们用高斯分布而不是均匀分布,原因便在此,这一点我们在前文变分自编码器VAE:原来是这么一回事中也提到过了。
顺便说点题外话,度量两个概率分布之间的差异只有 KL 散度吗?
当然不是,我们可以看维基百科的 Statistical Distance 一节,里边介绍了不少分布距离,比如有一个很漂亮的度量,我们称之为巴氏距离(Bhattacharyya distance),定义为:
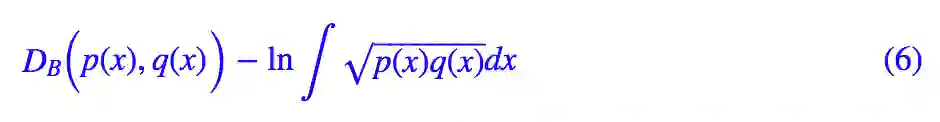
这个距离不仅对称,还没有 KL 散度的无穷大问题。然而我们还是选用 KL 散度,因为我们不仅要理论上的漂亮,还要实践上的可行。KL 散度可以写成期望的形式,这允许我们对其进行采样计算,
相反,巴氏距离就没那么容易了,读者要是想把下面计算过程中的 KL 散度替换成巴氏距离,就会发现寸步难行了。
本文的符号表
讲解 VAE 免不了出现大量的公式和符号,这里将部分式子的含义提前列举如下:

框架
这里通过直接对联合分布进行近似的方式,简明快捷地给出了 VAE 的理论框架。
直面联合分布
出发点依然没变,这里再重述一下。首先我们有一批数据样本 {x1,…,xn},其整体用 x 来描述,我们希望借助隐变量 z 描述 x 的分布 p(x):
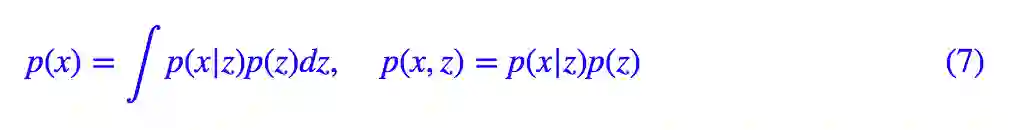
这样(理论上)我们既描述了 p(x),又得到了生成模型 p(x|z),一举两得。
接下来就是利用 KL 散度进行近似。但我一直搞不明白的是,为什么从原作 Auto-Encoding Variational Bayes 开始,VAE 的教程就聚焦于后验分布 p(z|x) 的描述?
也许是受了 EM 算法的影响,这个问题上不能应用 EM 算法,就是因为后验分布 p(z|x) 难以计算,所以 VAE 的作者就聚焦于 p(z|x) 的推导。
但事实上,直接来对 p(x,z) 进行近似是最为干脆的。具体来说,我们设想用一个新的联合概率分布 q(x,z) 来逼近 p(x,z),那么我们用 KL 散度来看它们的距离:
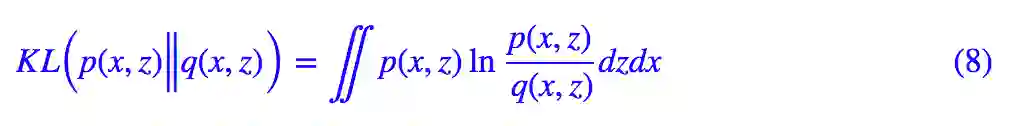
KL 散度是我们的终极目标,因为我们希望两个分布越接近越好,所以 KL 散度越小越好。由于我们手头上只有 x 的样本,因此利用 p(x,z)=p(x)p(z|x) 对上式进行改写:
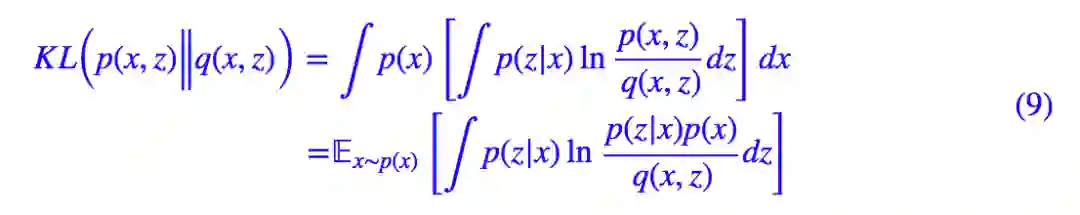
这样一来利用 (4) 式,把各个 xi 代入就可以进行计算了,这个式子还可以进一步简化,因为:
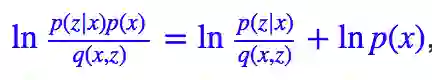
而:
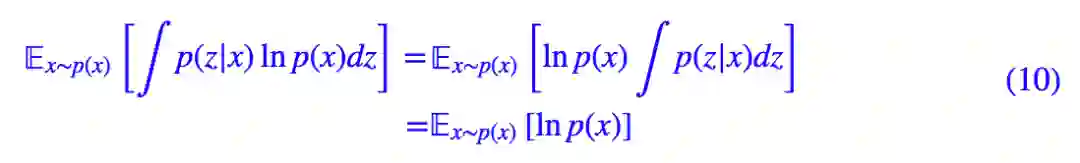
注意这里的 p(x) 是根据样本 x1,x2,…,xn 确定的关于 x 的先验分布(更常见的写法是 p̃(x)),尽管我们不一定能准确写出它的形式,但它是确定的、存在的,因此这一项只是一个常数,所以可以写出:
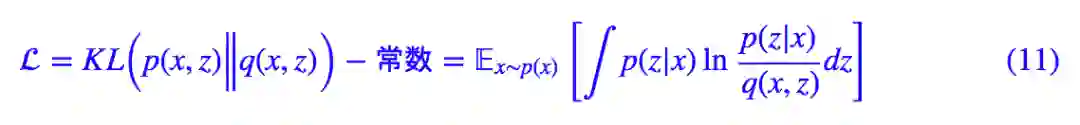
目前最小化 KL(p(x,z)‖q(x,z)) 也就等价于最小化 L。注意减去的常数一般是负数(概率小于 1,取对数就小于 0),而 KL 散度本来就非负,非负数减去一个负数,结果会是一个正数,所以 L 恒大于一个某个正数。
你的VAE已经送达
到这里,我们回顾初衷——为了得到生成模型,所以我们把 q(x,z) 写成 q(x|z)q(z),于是就有:
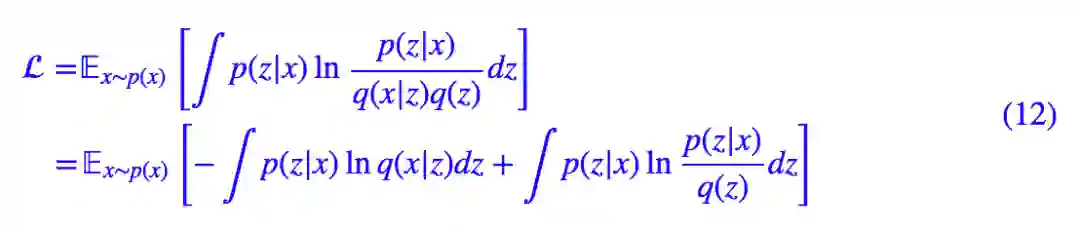
再简明一点,那就是:
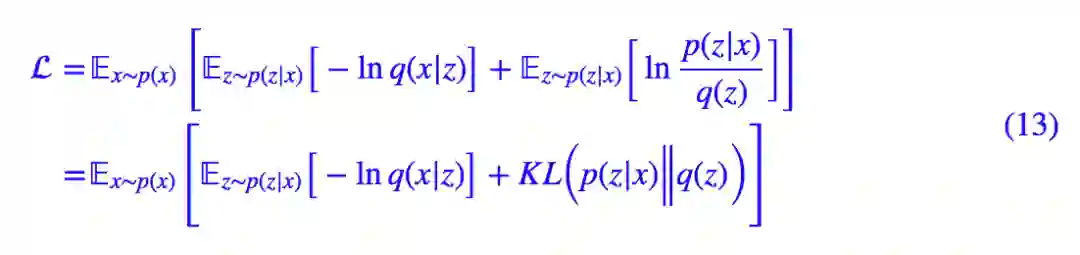
看,括号内的不就是 VAE 的损失函数吗?只不过我们换了个符号而已。我们就是要想办法找到适当的 q(x|z) 和 q(z) 使得 L 最小化。
再回顾一下整个过程,我们几乎都没做什么“让人难以想到”的形式变换,但 VAE 就出来了。所以,没有必要去对后验分布进行分析,直面联合分布,我们能更快捷地到达终点。
不能搞分裂
鉴于 (13) 式的特点,我们也许会将 L 分开为两部分看:𝔼z∼p(z|x)[−lnq(x|z)] 的期望和 KL(p(z|x)‖q(z)) 的期望,并且认为问题变成了两个 loss 的分别最小化。
然而这种看法是不妥的,我们前面已经分析了,L 会大于一个正数,这就意味着 𝔼z∼p(z|x)[−lnq(x|z)] 和 KL(p(z|x)‖q(z)) 两部分的 loss 不可能同时为零——尽管它们每一个都有可能为 0。这也表明这两部分的 loss 其实是相互拮抗的。
所以,L 不能割裂来看,而是要整体来看,整个的 L 越小模型就越接近收敛,而不能只单独观察某一部分的 loss。
事实上,这正是 GAN 模型中梦寐以求的——有一个总指标能够指示生成模型的训练进程,在 VAE 模型中天然就具备了这种能力了,而 GAN 中要到 WGAN 才有这么一个指标。
实验
截止到上面的内容,其实我们已经完成了 VAE 整体的理论构建。但为了要将它付诸于实验,还需要做一些工作。事实上原论文 Auto-Encoding Variational Bayes 也在这部分做了比较充分的展开,但遗憾的是,网上很多 VAE 教程都只是推导到 (13) 式就没有细说了。
后验分布近似
现在 q(z),q(x|z),p(z|x) 全都是未知的,连形式都还没确定,而为了实验,就得把 (13) 式的每一项都明确写出来。
首先,为了便于采样,我们假设 z∼N(0,I),即标准的多元正态分布,这就解决了 q(z)。那 q(x|z),p(z|x) 呢?一股脑用神经网络拟合吧。
注:本来如果已知 q(x|z) 和 q(z),那么 p(z|x) 最合理的估计应该是:
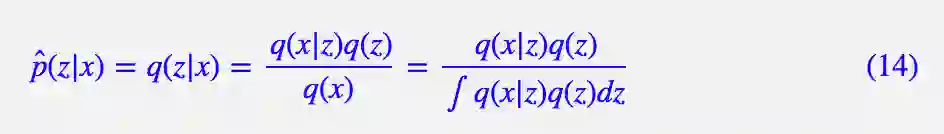
这其实就是 EM 算法中的后验概率估计的步骤,具体可以参考从最大似然到EM算法:一致的理解方式。但事实上,分母的积分几乎不可能完成,因此这是行不通的。所以干脆用一般的网络去近似它,这样不一定能达到最优,但终究是一个可用的近似。
具体来说,我们假设 p(z|x) 也是(各分量独立的)正态分布,其均值和方差由 x 来决定,这个“决定”,就是一个神经网络:
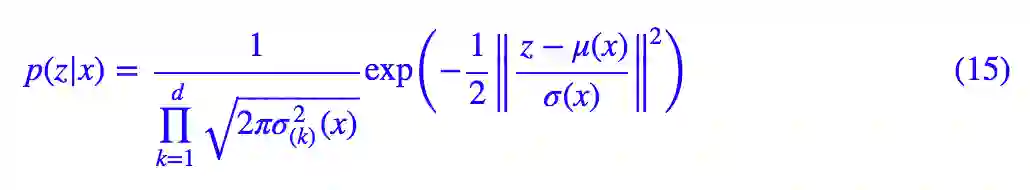
这里的 μ(x),σ^2(x) 是输入为 x、输出分别为均值和方差的神经网络,其中 μ(x) 就起到了类似 encoder 的作用。既然假定了高斯分布,那么 (13) 式中的 KL 散度这一项就可以先算出来:
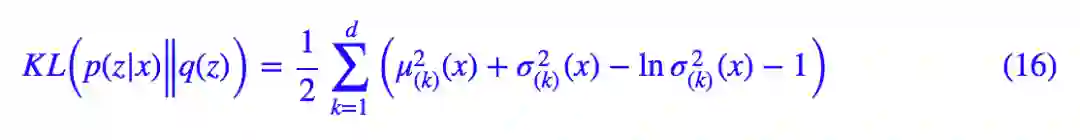
也就是我们所说的 KL loss,这在上一篇文章已经给出。
生成模型近似
现在只剩生成模型部分 q(x|z) 了,该选什么分布呢?论文 Auto-Encoding Variational Bayes 给出了两种候选方案:伯努利分布或正态分布。
什么?又是正态分布?是不是太过简化了?然而并没有办法,因为我们要构造一个分布,而不是任意一个函数,既然是分布就得满足归一化的要求,而要满足归一化,又要容易算,我们还真没多少选择。
伯努利分布模型
首先来看伯努利分布,众所周知它其实就是一个二元分布:

所以伯努利分布只适用于 x 是一个多元的二值向量的情况,比如 x 是二值图像时(mnist 可以看成是这种情况)。这种情况下,我们用神经网络 ρ(z) 来算参数 ρ,从而得到:
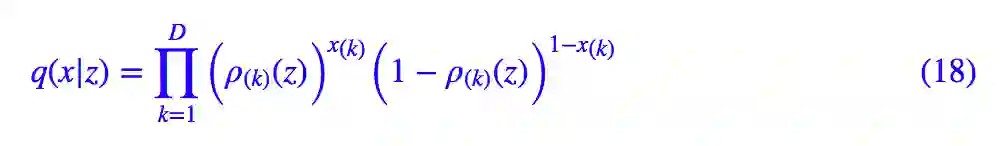
这时候可以算出:
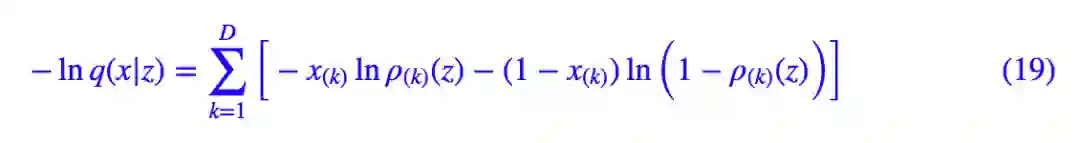
这表明 ρ(z) 要压缩到 0~1 之间(比如用 sigmoid 激活),然后用交叉熵作为损失函数,这里 ρ(z) 就起到了类似 decoder 的作用。
正态分布模型
然后是正态分布,这跟 p(z|x) 是一样的,只不过 x,z 交换了位置:
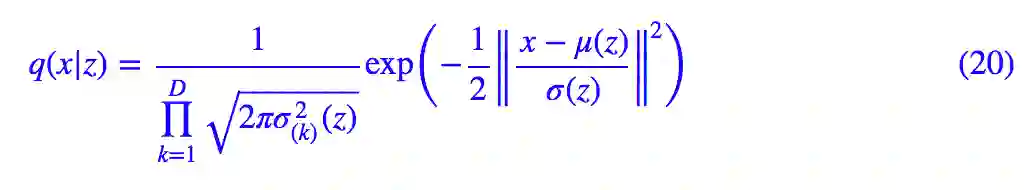
这里的 μ(z),σ^2(z) 是输入为 z、输出分别为均值和方差的神经网络,μ(z) 就起到了 decoder 的作用。于是:
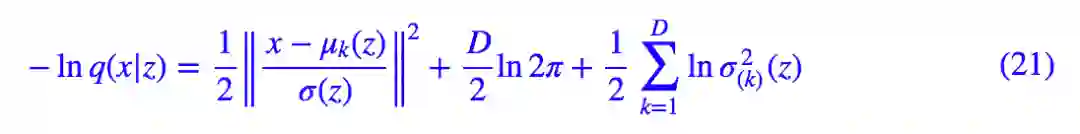
很多时候我们会固定方差为一个常数 σ^2,这时候:
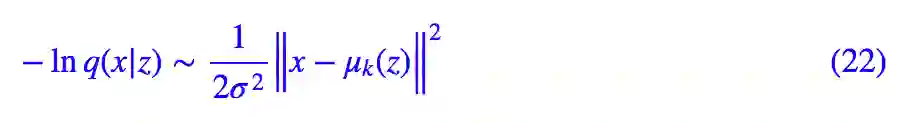
这就出现了 MSE 损失函数。
所以现在就清楚了,对于二值数据,我们可以对 decoder 用 sigmoid 函数激活,然后用交叉熵作为损失函数,这对应于 q(x|z) 为伯努利分布;而对于一般数据,我们用 MSE 作为损失函数,这对应于 q(x|z) 为固定方差的正态分布。
采样计算技巧
前一节做了那么多的事情,无非是希望能将 (13) 式明确地写下来。当我们假设 p(z|x) 和 q(z) 都是正态分布时,(13) 式的 KL 散度部分就已经算出来了,结果是 (16) 式;当我们假设 q(x|z) 是伯努利分布或者高斯分布时,−lnq(x|z) 也能算出来了。
现在缺什么呢? 采样!
p(z|x) 的作用分两部分,一部分是用来算 KL(p(z|x)‖q(z)),另一部分是用来算 𝔼z∼p(z|x)[−lnq(x|z)] 的,而 𝔼z∼p(z|x)[−lnq(x|z)] 就意味着:
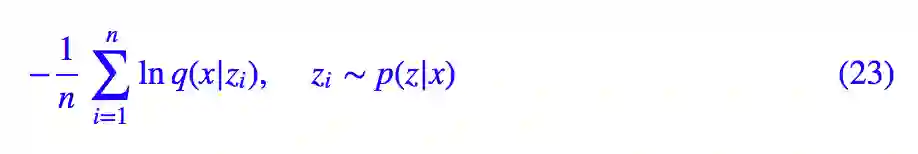
我们已经假定了 p(z|x) 是正态分布,均值和方差由模型来算,这样一来,借助“重参数技巧”就可以完成采样。
但是采样多少个才适合呢?标准的 VAE 非常直接了当:一个!所以这时候 (13) 式就变得非常简单了:
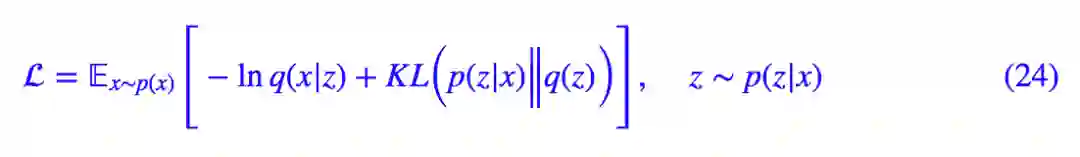
该式中的每一项,可以在把 (16),(19),(21),(22) 式找到。这因为标准的 VAE 只采样了一个,所以这时候它就跟普通的 AE 对应起来了。
那么最后的问题就是采样一个究竟够了吗?事实上我们会运行多个 epoch,每次的隐变量都是随机生成的,因此当 epoch 数足够多时,事实上是可以保证采样的充分性的。我也实验过采样多个的情形,感觉生成的样本并没有明显变化。
致敬
这篇文章从贝叶斯理论的角度出发,对 VAE 的整体流程做了一个梳理。用这种角度考察的时候,我们心里需要紧抓住两个点:“分布”和“采样”——写出分布形式,并且通过采样来简化过程。
简单来说,由于直接描述复杂分布是难以做到的,所以我们通过引入隐变量来将它变成条件分布的叠加。而这时候我们对隐变量的分布和条件分布都可以做适当的简化(比如都假设为正态分布),并且在条件分布的参数可以跟深度学习模型结合起来(用深度学习来算隐变量的参数),至此,“深度概率图模型”就可见一斑了。
让我们一起致敬贝叶斯大神,以及众多研究概率图模型的大牛,他们都是真正的勇者。

点击以下标题查看相关内容:


我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot02)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 进入作者博客



