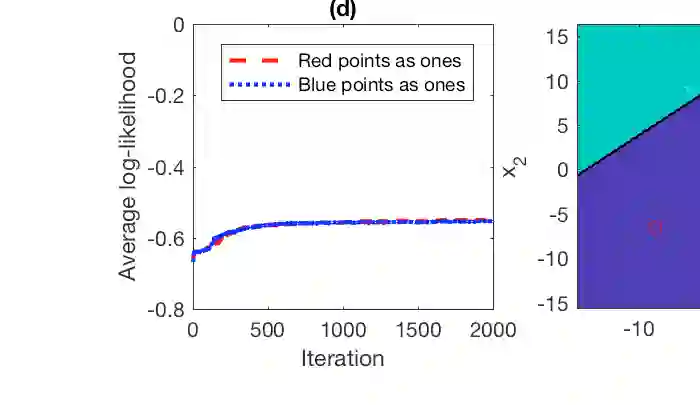
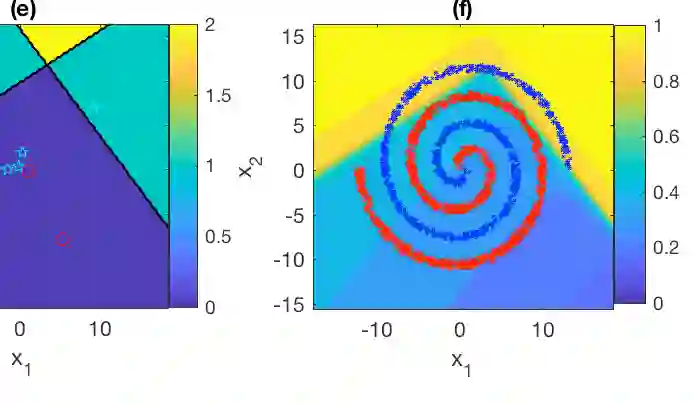
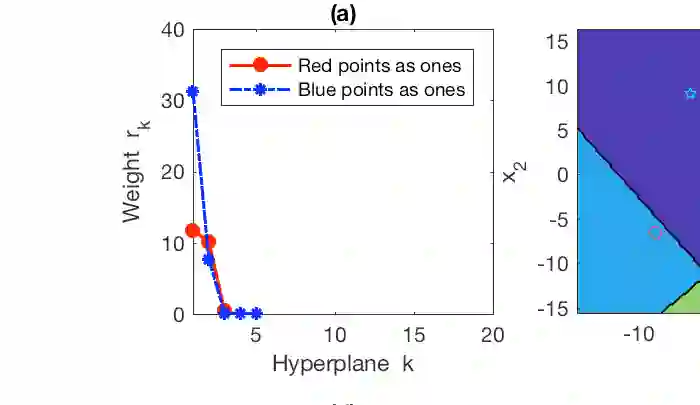
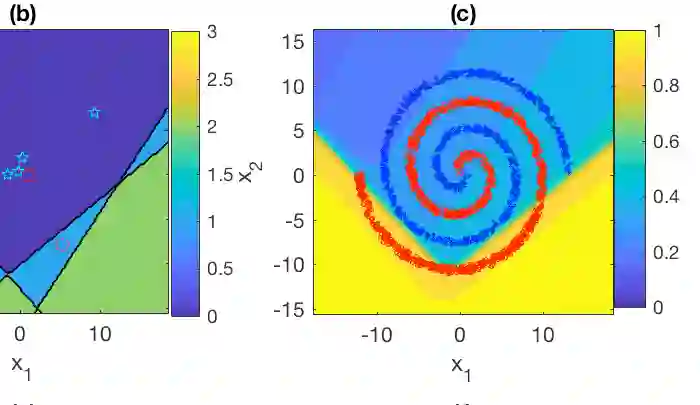
Combining Bayesian nonparametrics and a forward model selection strategy, we construct parsimonious Bayesian deep networks (PBDNs) that infer capacity-regularized network architectures from the data and require neither cross-validation nor fine-tuning when training the model. One of the two essential components of a PBDN is the development of a special infinite-wide single-hidden-layer neural network, whose number of active hidden units can be inferred from the data. The other one is the construction of a greedy layer-wise learning algorithm that uses a forward model selection criterion to determine when to stop adding another hidden layer. We develop both Gibbs sampling and stochastic gradient descent based maximum a posteriori inference for PBDNs, providing state-of-the-art classification accuracy and interpretable data subtypes near the decision boundaries, while maintaining low computational complexity for out-of-sample prediction.
翻译:结合巴伊西亚非参数和前瞻性模型选择战略,我们建造了典型的巴伊西亚深层网络(PBDNs),从数据中推断出能力正规化网络结构,在培训模型时不需要交叉验证或微调。PBDN的两个基本组成部分之一是开发一个特殊的、无限的单层单层神经网络,从数据中可以推断出活跃的隐藏单位的数量。另一个是构建一个贪婪的层次智能学习算法,使用前层选择标准来确定何时停止添加另一个隐藏层。我们为PBDNs开发了基于事后推论的Gibbs抽样和随机梯度梯度基底最大值,提供了最先进的分类精确度和在决定边界附近可解释的数据亚型,同时保持了外部抽样预测的低计算复杂性。