ETH Zurich提出新型网络「ROAD-Net」,解决语义分割域适配问题

在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @duinodo。本文是 ETH Zurich 发表于 CVPR 2018 的工作,论文提出了两个网络策略,用于处理语义分割任务中使用合成数据训练的域适配问题。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:杜敏,华中科技大学硕士生,研究方向为模式识别与智能系统。
■ 论文 | ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes
■ 链接 | https://www.paperweekly.site/papers/1828
■ 作者 | Yuhua Chen / Wen Li / Luc Van Gool
问题背景
本文研究的是无人驾驶场景中的语义分割问题。语义分割的样本标记成本很高,使用合成数据能帮助解决样本不足问题。但是合成的数据和真实的数据之间存在差异,这种差异会极大影响使用合成数据训练的模型在真实数据上的表现。
本文研究难点在于如何处理合成数据和真实数据之间的差异,该问题存在两方面原因:
用合成数据训练的模型,很容易对合成数据过拟合,对合成数据可以提取很好的特征,而对真实数据就提取不到特征了;
合成数据和真实数据的分布存在明显的差异,而模型对合成数据存在偏好。
其实以上两点说的是一点,只不过从两个角度说,这两点分别对应本文设计的两个子模型。
解决思路
本文的主要贡献在于提出了两个网络策略,用于处理语义分割任务中使用合成数据训练的域适配问题。
为了避免模型对合成数据的过拟合,本文使用 Target Guided Distillation Module,让模型模仿真实图片的训练的特征。
为了解决数据分布不一的问题,使用 Spatial-aware Adaption Module,充分考虑两种数据在空间分布上的差异,使得模型在两种数据上能够得到相似的特征。
论文模型
1. Target Guided Distillation
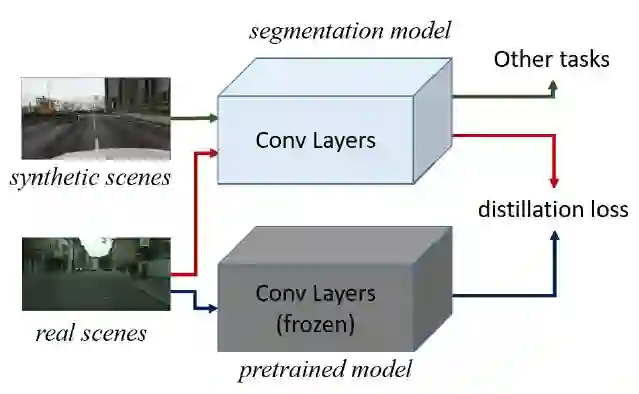
用 ImageNet 训练好的特征提取网络(图中灰色部分)作为 target,让分割模型提取的特征尽可能的像 target 提取的特征,distillation loss 采用欧拉距离计算方法。训练的时候,当输入是真实图片,计算 distillation loss;当输入是合成图片,输出分割的损失。
2. Spatial-Aware Adaption
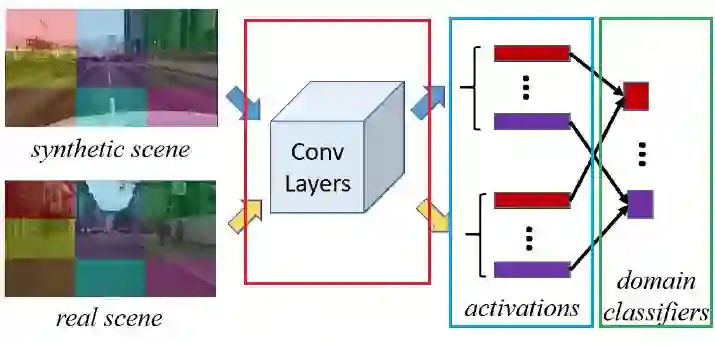
使用 max-min loss(对抗训练)的方式完成适配(domain distribution adaption)任务。适配任务的目的是,让特征提取网络,对不同分布域的数据,提取到类似的特征,而不影响后续的任务处理。
该问题的关键在于“类似的特征”如何表达。来自不同分布域的数据,内容存在差异,肯定无法直接用 mseloss 这种形式的损失来处理,所以,使用判别器损失,是比较合适的。
图中绿色框中的 domain classifier 就是这个判别器。红框同时也是上上图中分割网络所使用的卷积特征提取网络,而中间的蓝色框,表示的是标题中的“Spatial-Aware”,也就是把对用整张图的特征,分成 3x3 个区域,分别对每个区域计算判别损失。
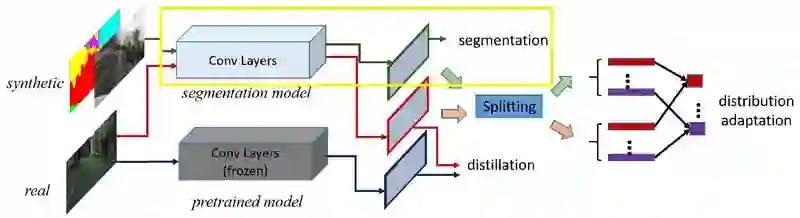
3. 整个模型
整个网络连起来,如下图所示。测试的时候,只使用用图中黄色框的部分。
实验
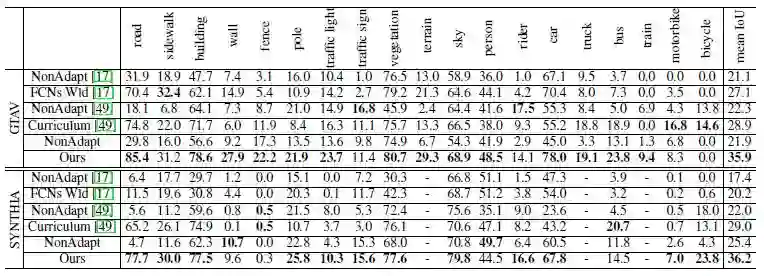
真实数据集 Cityscapes [1],合成数据集 GTAV [2],分割网络使用 PSPnet 和 Deeplab。其中,Cityscapes 仅使用图片,未使用标签(本文要处理的是尽可能不使用人工标记的样本)。
训练时,一个 batch 中有 10 张图片,5 张来自 Cityscapes,5 张来自 GTAV。使用真实图片进行测试,计算 mIOU,实验结果如下。
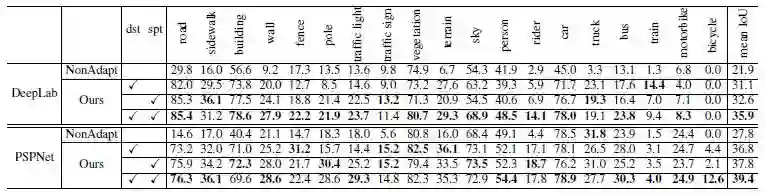
适配能提升 14 个百分点,但是相比于使用人工标记的训练结果 [3],还是要差很多很多。
本文提出的适配方法,相比于其他适配方法,效果也是最好的。
评价
本文研究的问题(使用合成数据减少对人工标注数据的依赖)很有实际意义,但是目前的效果还是差一些,似乎只能充当 boosting,离目标还有一段距离。很多视觉任务,都可以尝试这种方法,以减少对实际标注样本量的需求。
另外,是否可以研究,在使用合成数据的情况下,检测结果(在真实数据下测试的指标)随真实标记样本量的变化情况,定性地了解,到底合成数据能在多大程度上,减少手工标注量。比如,可能画出如下曲线:
如果能做到这个地步,那在实际应用中,使用合成数据进行训练这种方法,可能会广泛使用,毕竟目前还仅仅停留在学术论文的地步。
相关链接
[1] Cityscapes数据集
https://www.cityscapes-dataset.com/
[2] GTAV数据集
https://download.visinf.tu-darmstadt.de/data/from_games/
[3] 使用人工标记的训练结果
https://www.cityscapes-dataset.com/benchmarks/#pixel-level-results
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

▲ 戳我查看招聘详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



