1 引言
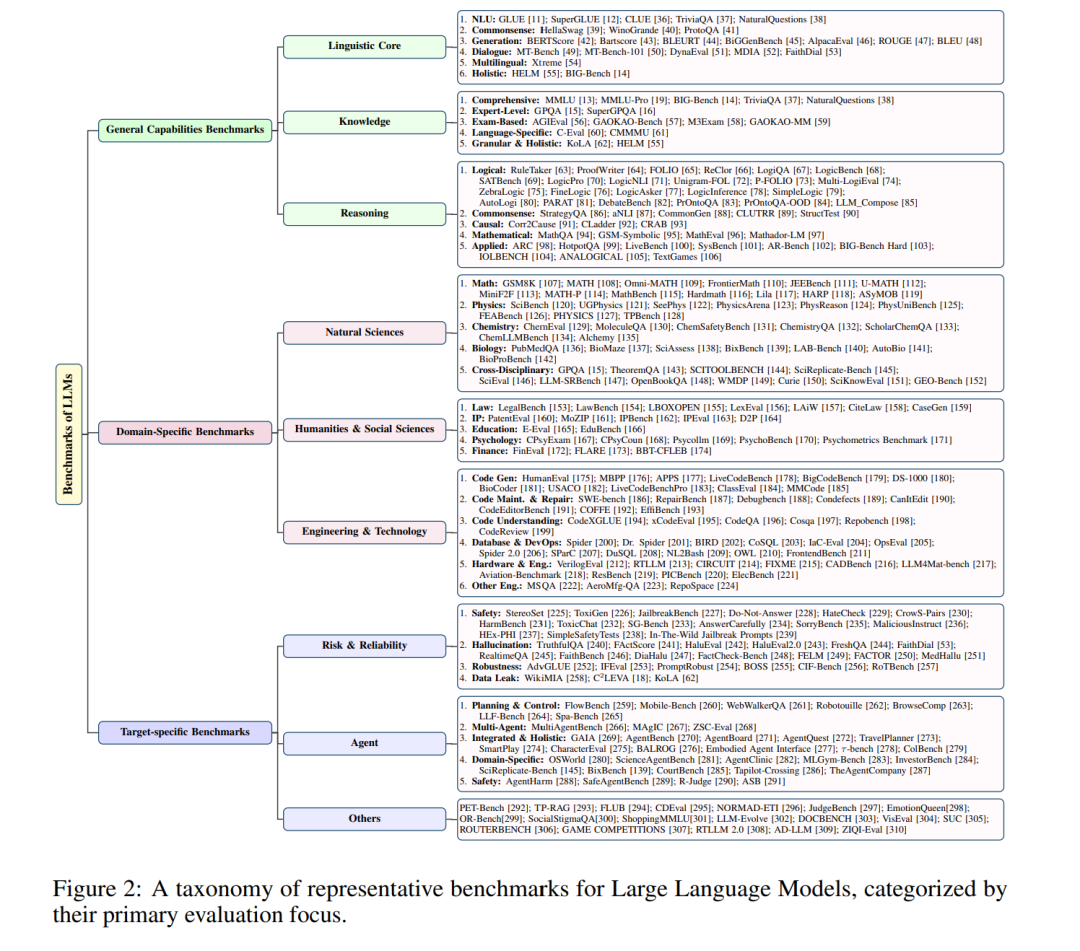
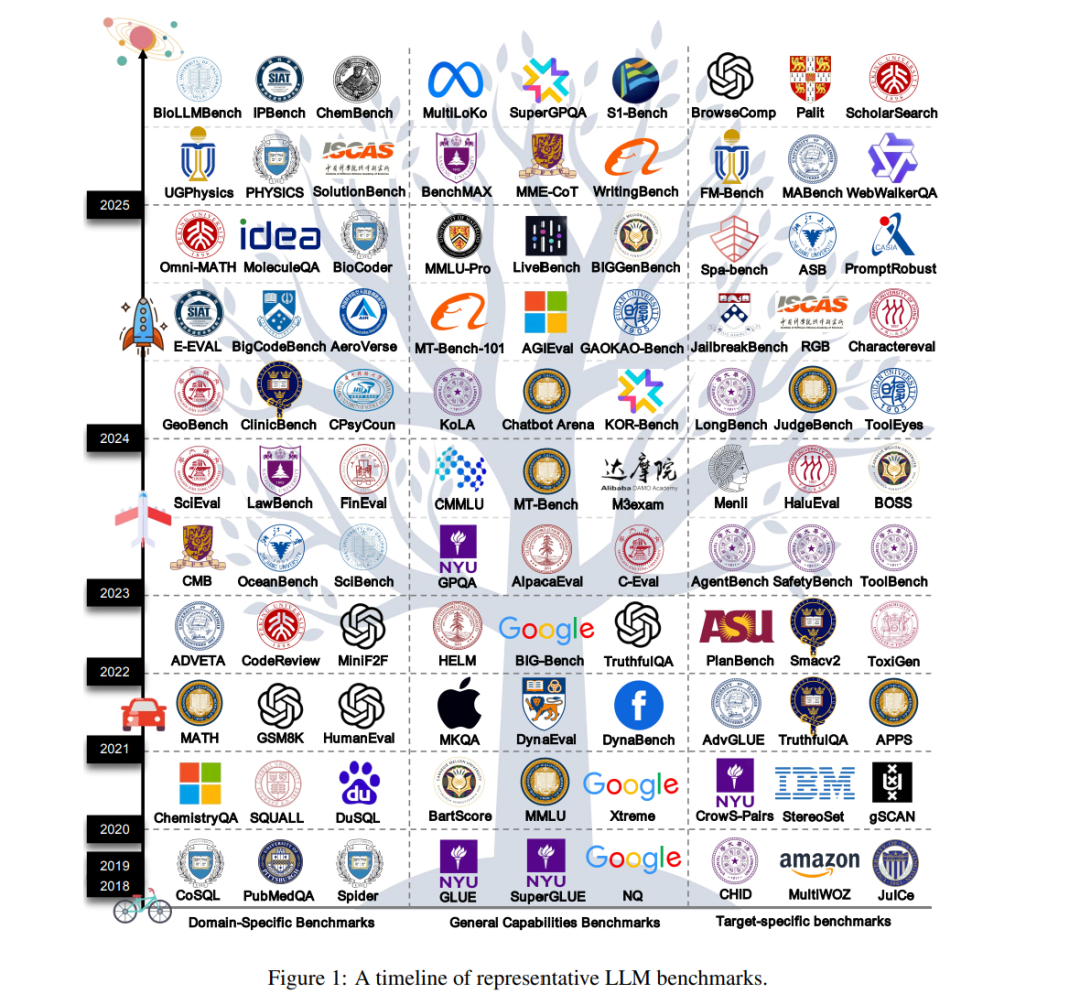
自从 2017 年 Transformer 架构 [1] 被提出以来,大语言模型(LLMs)凭借其强大的自然语言处理能力,在人工智能(AI)领域掀起了一场革命性浪潮。从基础的自然语言理解与文本生成任务,到复杂的逻辑推理与智能体交互,LLMs 不断拓展 AI 的能力边界,并重塑了人机交互范式与信息处理模式。随着 GPT 系列 [2, 3, 4]、LLaMA 系列 [5, 6, 7]、Qwen 系列 [8, 9, 10] 等模型的相继推出,LLMs 已经广泛渗透到智能客服、内容创作、教育、医疗、法律等领域,成为推动数字经济发展和社会智能化转型的核心驱动力。 随着 LLM 技术迭代的加速,建立一个科学而全面的评价体系已变得尤为迫切。作为衡量模型性能的量化评估手段,基准不仅是检验模型能力的核心工具,也是引导模型发展方向、推动技术创新的关键环节。通过基准测试,研究者可以客观比较不同模型的优劣,准确定位技术瓶颈,并为算法优化与架构设计提供数据支撑;同时,标准化的评估结果有助于建立用户信任,确保模型在安全性与公平性方面符合社会与伦理规范。 然而,与早期以 GLUE [11] 和 SuperGLUE [12] 为代表的语言模型评测基准相比,LLM 时代的模型参数规模呈指数级增长,能力维度也从单任务拓展到多任务与多领域(如 MMLU [13]、GIG-bench [14]、GPQA [15]、SuperGPQA [16]),评测范式也从固定任务转向多任务与多领域。这些变化对评估体系的科学性与适应性提出了更高要求。 目前,LLM 评估领域仍面临诸多亟待解决的挑战。首先,数据泄漏 [17, 18] 问题日益突出,部分模型在训练阶段已暴露于评测数据,导致评测结果虚高,无法真实反映模型的泛化能力;其次,静态评测 [13, 19] 难以模拟动态的真实场景,难以预测模型在面对新任务和新领域时的表现。再者,评估指标的单一性(如过度依赖准确率和 BLEU 分数)无法全面刻画 LLMs 的复杂能力,而对于偏见与安全漏洞的检测、以及指令遵循性的系统化评估等关键需求仍未得到有效满足。此外,大规模评估所需的算力与人力成本高昂,以及任务设计难以覆盖真实世界复杂性,这些因素都严重制约了 LLMs 的健康发展。图1 展示了具有代表性的大语言模型基准的时间线,说明了这一快速演化的过程。 本文首次针对 LLM 基准开展系统性的综述与前瞻性分析,主要贡献如下: 1. 首次对 283 个 LLM 基准 进行系统分析与归纳,总结为三大类:通用能力基准、领域特定基准与目标特定基准。 1. 从数据来源、数据格式、数据规模、评测方法、评测指标等多个维度,全面剖析各类基准的设计动机与局限性,并为后续基准创新提供可直接借鉴的设计范式。 1. 指出当前 LLM 基准所面临的三大突出问题:数据污染导致的分数虚高、文化与语言偏差引发的不公平评估、以及缺乏对“过程可信度”和“动态环境”的评估。