CVPR 2018论文解读 | 基于域适应弱监督学习的目标检测


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @Cratial。本文是东京大学发表于 CVPR 2018 的工作,论文提出了基于域适应的弱监督学习策略,在源域拥有充足的实例级标注的数据,但目标域仅有少量图像级标注的数据的情况下,尽可能准确地实现对目标域数据的物体检测。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:吴仕超,东北大学硕士生,研究方向为脑机接口、驾驶疲劳检测和机器学习。
■ 论文 | Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation
■ 链接 | https://www.paperweekly.site/papers/2106
■ 源码 | https://github.com/naoto0804/cross-domain-detection
引出主题
虽然深度学习技术在物体检测方面取得了巨大的成功,但目前的物体检测技术主要面向的对象是真实场景下的图像,而对于像水彩画这种非真实场景下的物体检测任务来说,一般很难获取大量带有标注的数据集,因此物体检测问题就变得比较棘手。
为解决这一问题,本文提出了基于域适应的弱监督学习策略,其可以描述为:(1)选取一个带有实例级标注的源域数据;(2)仅有图像级标注的目标域数据;(3)目标域数据的类别是源域数据类别的全集或子集。
论文的任务就是在源域拥有充足的实例级标注的数据,但目标域仅有少量图像级标注的数据的情况下,尽可能准确地实现对目标域数据的物体检测。这个任务的难点主要在于目标域没有实例级的标注,因此无法直接利用目标数据集对基于源数据集训练的模型进行微调。
针对这一问题,作者提出了两种解决方法:
1. 域迁移(domain transform,DT):即利用图像转换技术,如CycleGAN将源域数据转换为和目标数据相似的带有实例级的图像;
2. 伪标记(pseudo-labeling,PL):利用伪标记来对目标域数据产生伪实例级标注。两种方法如图 1 所示:
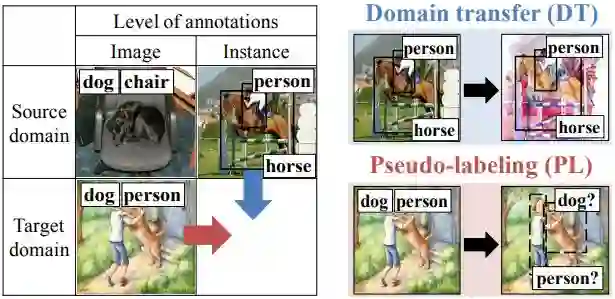
▲ 图1
为验证该策略的有效性,作者分别采集并手工标注了三个分别具有实例级标注的目标数据集:Clipart1k,Watercolor2k,Comic2k。
数据集及代码见:
https://naoto0804.github.io/cross_domain_detection/
数据集描述
笔者认为这篇文章最大的贡献之处不仅仅在于其提出的基于弱监督学习的目标检测方法,更重要的是作者所建立的数据集,为将来这方面工作的进行提供了数据支持。
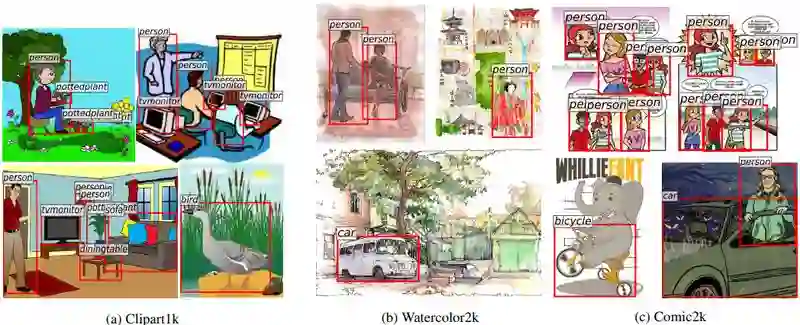
▲ 图2
在本文中,作者选取的源域数据集为 PASCAL VOC 数据集,同时作者收集并标注了 3 个目标域数据集,其示例如图 2 所示。数据集的具体信息如表 1 所示:
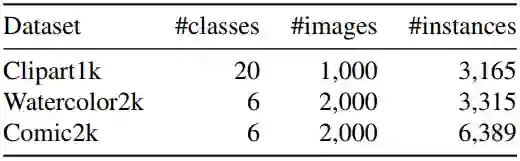
▲ 表1
方法
本文的方法如图 3 所示,首先我们对源域图像进行域迁移训练得到域迁移图像,然后对于基于源域数据集训练得到的模型,再通过域迁移图像对模型进行微调,最后再使用通过伪标记方法获取的数据对模型进行进一步的微调。
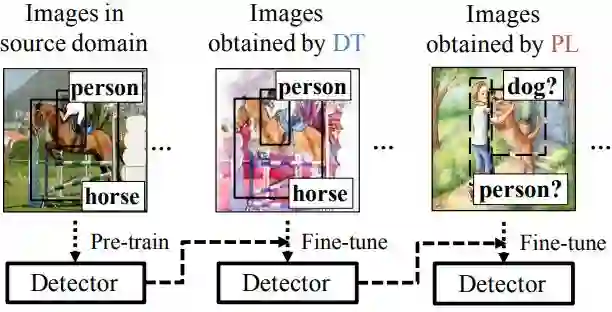
▲ 图3
域迁移(DT)
正如前面所提到的,本文主要解决的问题是目标域和源域分布不同的目标检测问题,而这部分旨在通过变换将源域数据分布变换为目标域分布,本文作者使用的是 CycleGAN [1] 来实现这种变换。
伪标记(PL)
对于只用图像级标注(即每个图像上包含哪几种类别)的目标域数据集,我们需要获取其伪实例级标注。首先,对于目标域数据中的每一幅图像 x ,使用基于源域训练的模型得到输出 d=(p,b,c) ,其中 b 是得到的 bounding box, c 是得到的类别, p 是属于该类的概率。根据这个结果,对于图像中所包含的每个类别,通过选取 top-1 概率的结果来作为目标图像的 bounding box,从而来实现对目标图像的伪标注。
实验
为证明方法的有效性,作者分别利用 PL、DT、DT+PL 的微调方法进行了实验,在 Clipart1k 数据集上的实验结果如表2所示。其中,基线(Baseline)是利用 SSD300 直接在目标域图像上进行实验的结果,而理想情况(Ideal case)是利用带实例级标注的目标域数据对模型进行微调的结果。此外,作者还利用基于弱监督检测的方法 ContextLocNet [2]、WSDDN [3] 及无监督域适应的方法 ADDA [4] 来做对比实验。
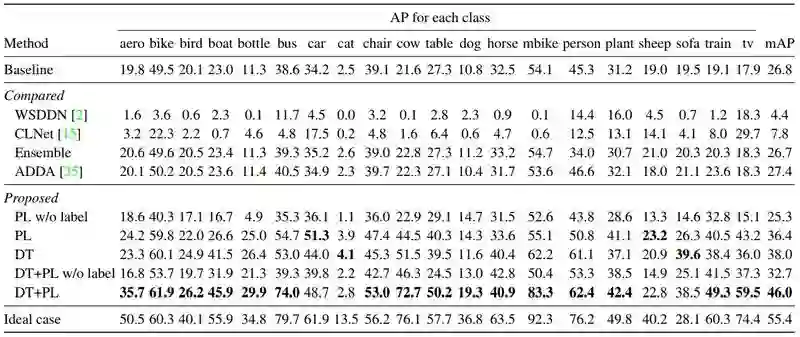
▲ 表2
从表 2 可以看出,作者提出的微调策略能够在检测性能上有较大的提升。此外,从表 2 中可以看出经过 DT 变换的微调方法可以很大程度地提升检测性能,而在不使用图像级标注的 PL 数据域进行微调的方法不仅不能提高性能,而且会导致性能有所下降,所以图像级的标签对物体检测是很重要的。
此外,作者在 YOLOv2 及 Faster R-CNN 上进行了同样的实验,实验结果同样证明了该微调策略的有效性。实验结果如表 3 所示:
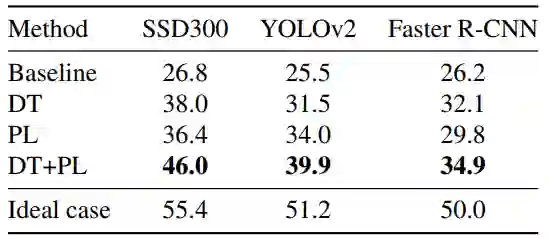
▲ 表3
为验证本文方法的有效性,作者采用论文 [5] 提供的方法对检测效果进行分析,分析结果如图 4 所示。从图中可以看出基于 DT 变换的微调模型能够很好的提高物体检测的性能,相对于 DT 来说,基于 DT+PL 的微调策略能够进一步地提高检测的性能,尤其是在容易将物体误分成不相似类别物体的分类任务上(Sim 将物体识别成与该物体类似但不相同的类别,Oth 将物体识别成其他不相似的类别)。这也进一步说明了为何图像级标注可以提高物体检测的性能。
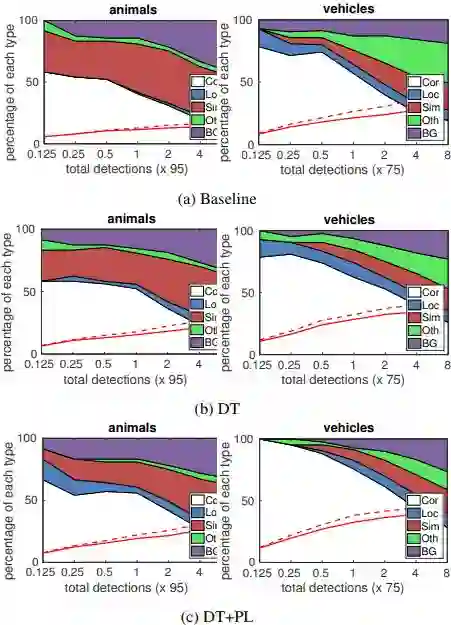
▲ 图4
此外,作者还对另外两个数据集进行了实验,实验结果分别如表 4、5 所示:
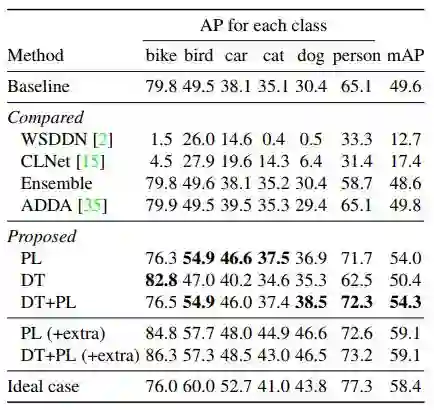
▲ 表4
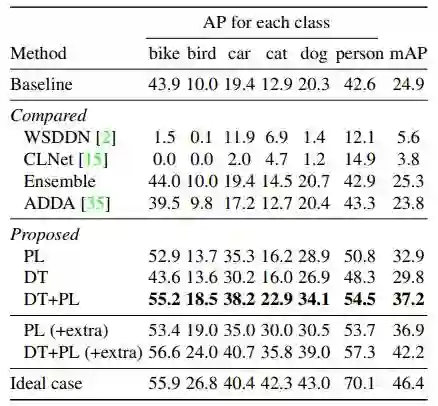
▲ 表5
总结
在本文中,作者为将当前的物体检测技术应用到一些非现实场景,即缺少大量实例级标注的场景,如水彩画的目标检测等任务,而提出了一套全新的训练策略,并建立了一些数据集来为将来这方面的工作做铺垫。笔者认为这项工作是非常有意义的,就人本身而言,我们不仅可以很好地分辨实际场景中的物体,同样可以很好地检测到一些例如动画、水彩画中的物体,即使有时我们很少接触这些,而基于深度学习的物体检测技术也应该具备这种能力。
参考文献
[1]. J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image- to-image translation using cycle-consistent adversarial net- works. In ICCV, 2017.
[2]. V. Kantorov, M. Oquab, M. Cho, and I. Laptev. Context- LocNet: Context-aware deep network models for weakly supervised localization. In ECCV, 2016.
[3]. H. Bilen and A. Vedaldi. Weakly supervised deep detection networks. In CVPR, 2016.
[4]. E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017.
[5]. D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV, 2012.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文



