CVPR 2019 Oral 论文解读 | 无监督域适应语义分割

AI 科技评论按:百度研究院、华中科技大学、悉尼科技大学联合新作——关于无监督领域自适应语义分割的论文《 Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation》被 CCF A 类学术会议 CVPR2019 收录为 Oral 论文 。该论文提出了一种从「虚拟域」泛化到「现实域」的无监督语义分割算法,旨在利用易获取的虚拟场景标注数据来完成对标注成本高昂的现实场景数据的语义分割,大大减少了人工标注成本。 本文是论文作者之一罗 亚威独家提供的论文解读。
论文地址: https://arxiv.org/abs/1809.09478
· 1. 问题背景 ·
基于深度学习的语义分割方法效果出众,但需要大量的人工标注进行监督训练。不同于图像分类等任务,语义分割需要像素级别的人工标注,费时费力,无法大规模实施。借助于计算机虚拟图像技术,如3D游戏,用户可以几乎无成本地获得无限量自动标注数据。然而虚拟图像和现实图像间存在严重的视觉差异(域偏移),如纹理、光照、视角差异等等,这些差异导致在虚拟图像上训练出的深度模型往往在真实图像数据集上的分割精度很低。
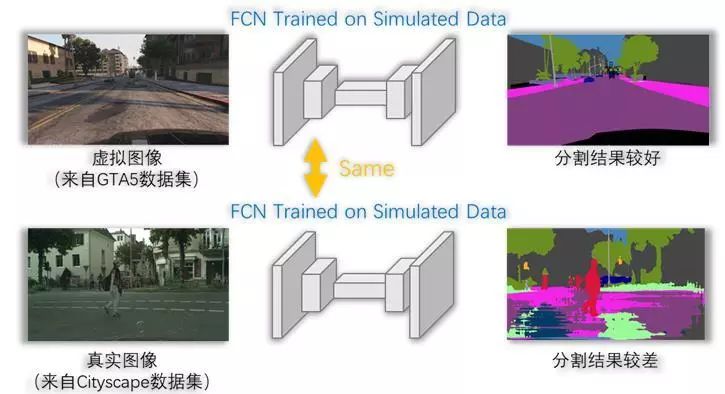
图1. 问题背景
· 2. 传统方法 ·
针对上述域偏移问题,一种广泛采用的方法是在网络中加入一个域判别器Discriminator (D),利用对抗训练的机制,减少源域Source (S)和目标域Target(T)之间不同分布的差异,以加强原始网络(G)在域间的泛化能力。方法具体包括两方面:
(1)利用源域的有标签数据进行有监督学习,提取领域知识:
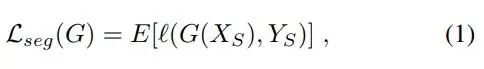
其中Xs,Ys为源域数据及其对应标签。
(2)通过对抗学习,降低域判别器(D)的精度,以对齐源域与目标域的特征分布:
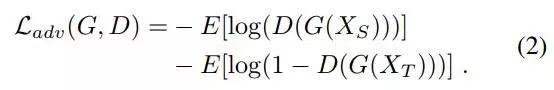
其中XT为目标域数据,无标签。
· 3. 我们针对传统方法的改进 ·
以上基于对抗学习的传统域适应方法只能对齐全局特征分布(Marginal Distribution),而忽略了不同域之间,相同语义特征的语义一致性(Joint Distribution),在训练过程中容易造成负迁移,如图2(a)所示。举例来说,目标域中的车辆这一类,可能与源域中的车辆在视觉上是接近的。因此,在没有经过域适应算法之前,目标域车辆也能够被正确分割。然而,为了迎合传统方法的全局对齐,目标域中的车辆特征反而有可能会被映射到源域中的其他类别,如火车等,造成语义不一致。
针对这一问题,我们在今年CVPR的论文中,向对抗学习框架里加入了联合训练的思想,解决了传统域适应方法中的语义不一致性和负迁移等键问题。具体做法见图2(b),我们采用了两个互斥分类器对目标域特征进行分类。当两个分类器给出的预测很一致时,我们认为该特征已经能被很好的分类,语义一致性较高,所以应减少全局对齐策略对这些特征产生的负面影响。反之,当两个分类器给出的预测不一致,说明该目标域特征还未被很好地分类,依然需要用对抗损失进行与源域特征的对齐。所以应加大对齐力度,使其尽快和源域特征对应。
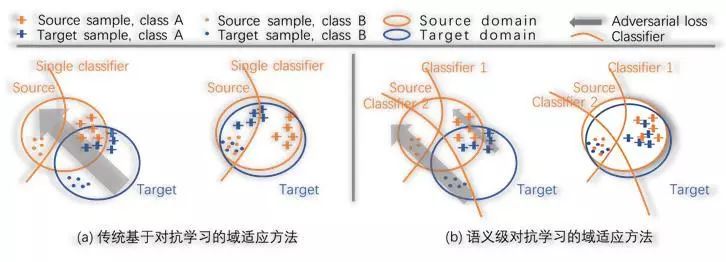
图2. 传统方法和本文方法对比
· 4. 网络结构 ·
为了实现上述语义级对抗目标,我们提出了Category-Level Adversarial Network (CLAN)。 遵循联合训练的思想,我们在生成网络中采用了互斥分类器的结构,以判断目标域的隐层特征是否已达到了局部语义对齐。在后续对抗训练时, 网络依据互斥分类器产生的两个预测向量之差(Discrepancy)来对判别网络所反馈的对抗损失进行加权。网络结构如下图3所示。
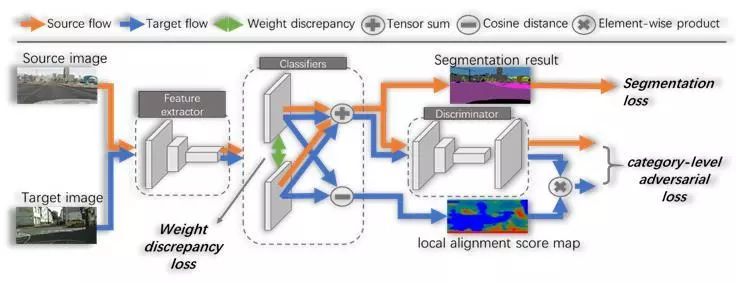
图3. 网络结构
图3中,橙色的线条表示源域流,蓝色的线条表示目标域流,绿色的双箭头表示我们在训练中强迫两个分类器的参数正交,以达到互斥分类器的目的。源域流和传统的方法并无很大不同,唯一的区别是我们集成了互斥分类器产生的预测作为源域的集成预测。该预测一方面被标签监督,产生分割损失(Segmentation Loss),如式(3)所示:
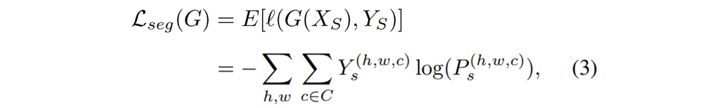
另一方面,该预测进入判别器D,作为源域样本。
绿色的双箭头处,我们使用余弦距离作为损失,训练两个分类器产生不同的模型参数:
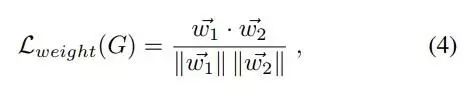
目标域流中,集成预测同样进入判别器D。不同的是,我们维持两个分类器预测的差值,作为局部对齐程度的依据 (local alignment score map)。该差值与D所反馈的损失相乘,生成语义级别的对抗损失:
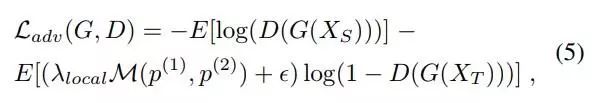
该策略加大了语义不一致特征的对齐力度,而减弱了语义一致的特征受全局对齐的影响,从而加强了特征间的语义对齐,防止了负迁移的产生。
最后,根据以上三个损失,我们可以得出最终的总体损失函数:
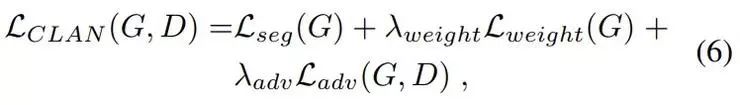
基于以上损失函数,算法整体的优化目标为:
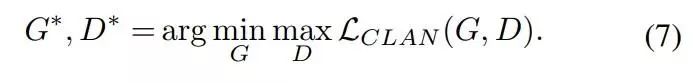
在训练中,我们交替优化G和D,直至损失收敛。
· 5. 特征空间分析 ·
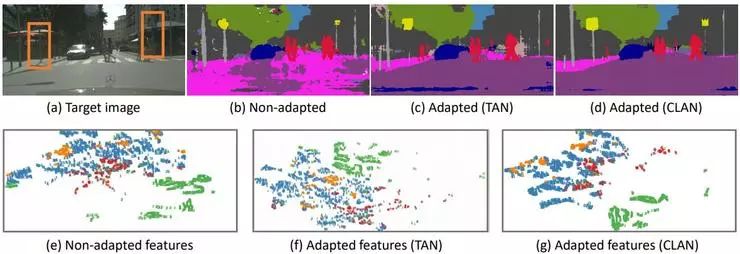
图4. T-SNE
我们重点关注不常见类,如图4(a)中黄框内的柱子,交通标志。这些类经过传统方法的分布对齐,反而在分割结果中消失了。结合特征的t-SNE图,我们可以得出结论,有些类的特征在没有进行域迁移之前,就已经是对齐的。传统的全局域适应方法反而会破坏这种语义一致性,造成负迁移。而我们提出的语义级别对抗降低了全局对齐对这些已对齐类的影响,很好的解决了这一问题。
· 6. 实验结果 ·
我们在两个域适应语义分割任务,即GTA5 -> Cityscapes 和 SYNTHIA -> Cityscapes 上进行了实验验证。我们采用最常见的Insertion over Union作为分割精度的衡量指标,实验结果如下。从表1和表2中可以看出,在不同网络结构(VGG16,ResNet101)中,我们的方法(CLAN)域适应效果都达到了 state-of-the-art的精度。特别的,在一些不常见类上(用蓝色表示),传统方法容易造成负迁移,而CLAN明显要优于其他方法。
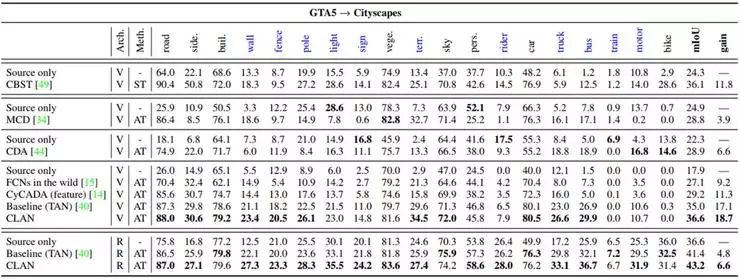
表 1. 由虚拟数据集GTA5 迁移至真实数据集 Cityscapes 的域适应分割精度对比。
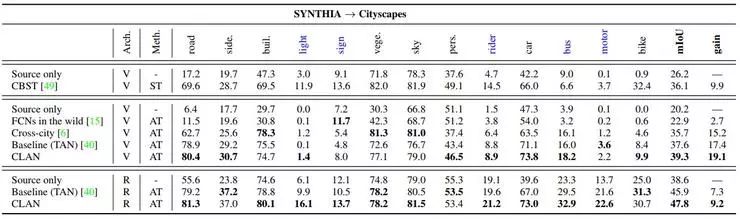
表 2. 由虚拟数据集SYNTHIA 迁移至真实数据集 Cityscapes 的域适应分割精度对比。
第二个实验中,我们了展示隐空间层面,源域和目标域间同语义特征簇的中心距离。该距离越小,说明两个域间的语义对齐越好。结果见图 5。
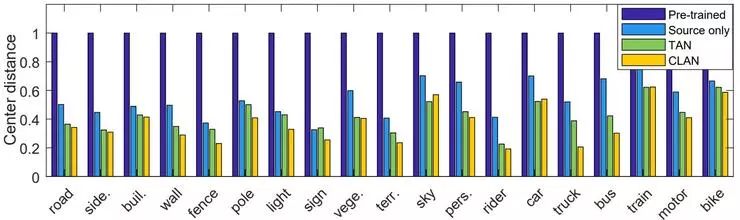
图5
最后,我们给出分割结果的可视化效果。我们的算法大大提高了分割精度。

· 7. 总结 ·
《Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation》引入了联合训练结合对抗学习的设计,在无监督域适应语义分割任务中取得了较好的实验结果。该算法能应用前景广泛,比如能够很好地应用到自动驾驶中,让车辆在不同的驾驶环境中也能保持鲁棒的街景识别率。
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,现价仅999元,限量3张,送完即止。(打开以下任意一条链接即可兑换,先到先得)
https://gair.leiphone.com/gair/coupon/s/5cee3a5ec02b1
https://gair.leiphone.com/gair/coupon/s/5cee3a5ebfff8
https://gair.leiphone.com/gair/coupon/s/5cee3a5ebfd33





