计算机视觉顶会 CVPR 2019 的论文接前几天公布了接受论文:在超过 5100 篇投稿中,共有 1300 篇被接收,达到了接近 25.2% 的接收率。上周小编推出CVPR2019图卷积网络相关论文,反响热烈。CVPR2019 最新发布的论文有很多关于生成对抗网络(GAN)相关论文,今天小编专门整理最新十篇生成对抗网络相关视觉论文—风格迁移、图像合成、异常检测、事件、故事可视化、Text2Scene等。
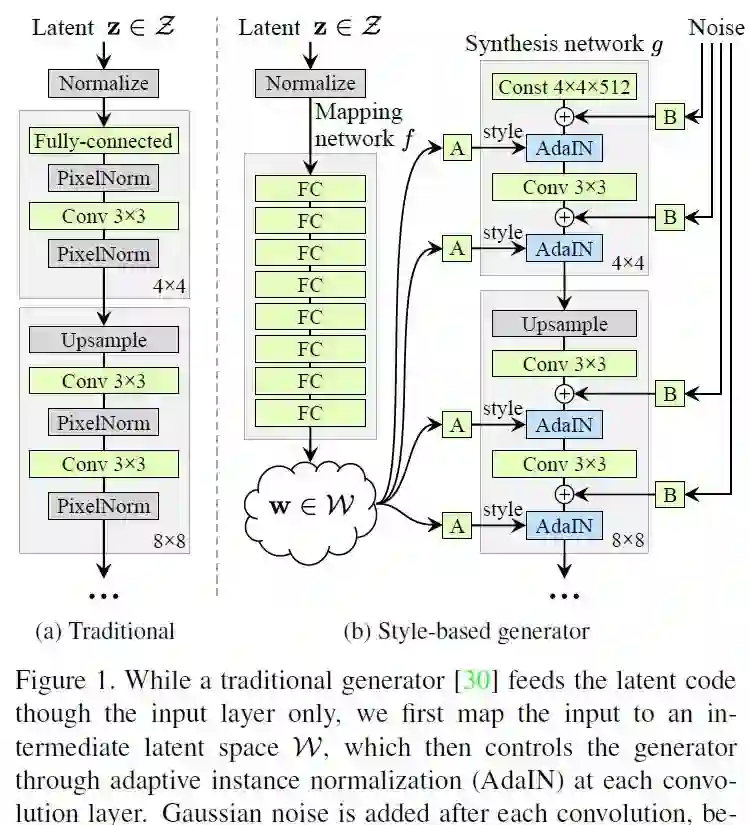
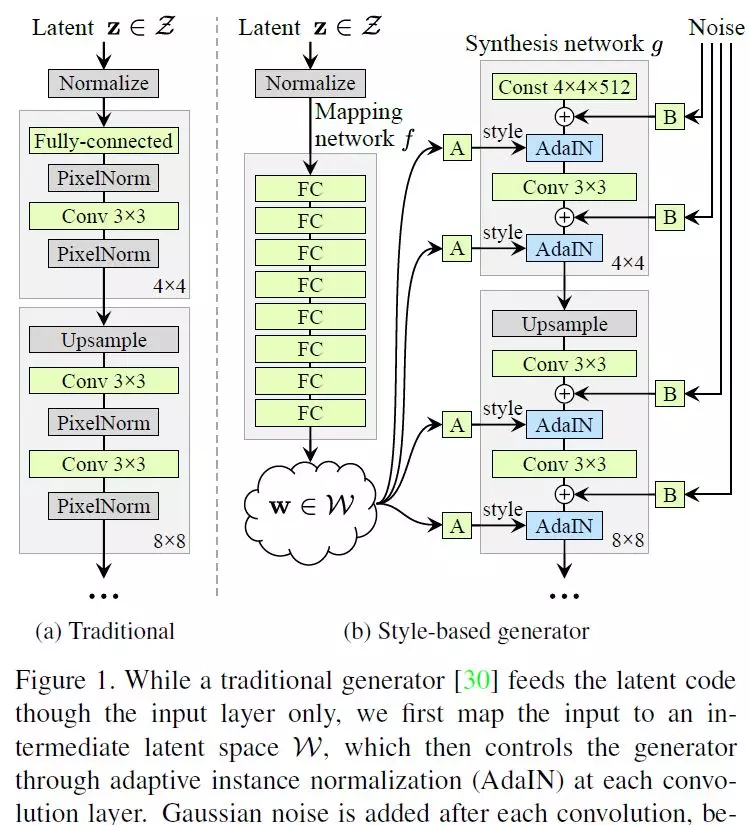
1、A Style-Based Generator Architecture for Generative Adversarial Networks(一种用于生成对抗网络的基于Style的新生成器结构)
作者:Tero Karras, Samuli Laine, Timo Aila
摘要:我们借鉴了风格迁移的相关工作,提出了一种用于生成对抗网络的替代生成器结构。新的结构自动学习、无监督地分离高级属性(例如,在人脸训练时的姿势和身份)和生成图像中的随机变化(例如雀斑、头发),并支持对合成的直观、特定尺度的控制。该算法改进了传统的分布质量度量方法,提高了插补性能,并较好地解决了潜在的变化因素。为了量化interpolation quality和disentanglement,我们提出了两种新的、适用于任何生成器架构的自动化方法。最后,我们介绍了一个新的,高度多样化和高质量的人脸数据集。
网址:
https://arxiv.org/abs/1812.04948v3
代码链接:
https://github.com/NVlabs/stylegan
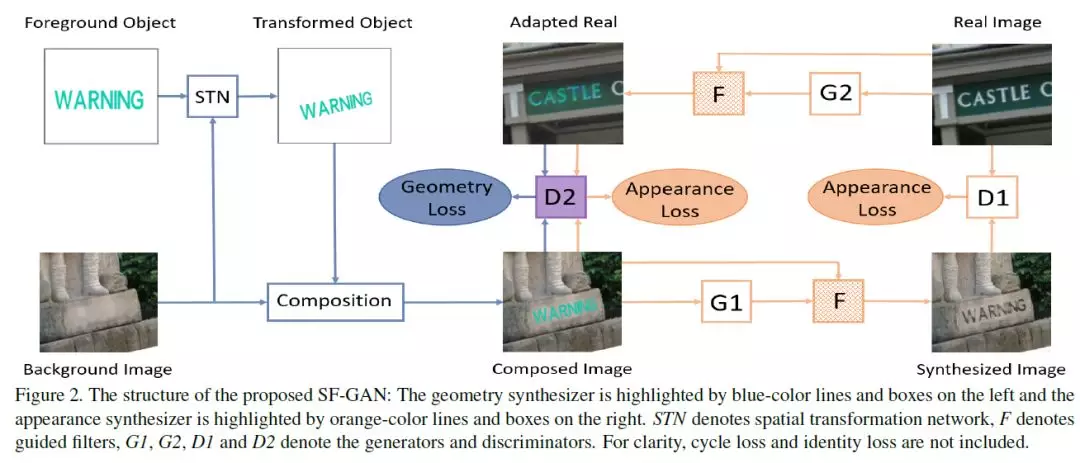
2、Spatial Fusion GAN for Image Synthesis(基于空间融合GAN的图像合成)
作者:Fangneng Zhan, Hongyuan Zhu, Shijian Lu
摘要:生成对抗网络(GANs)的最新研究成果显示了其在真实图像合成方面的巨大潜力,而现有的大多数文章都是在外观空间或几何空间进行合成,但同时使用两者的很少。本文提出了一种新颖的空间融合GAN (SF-GAN),它结合了几何合成器和表观合成器,实现了几何和外观空间的综合真实感。该几何合成器学习背景图像的背景几何,并一致地将前景对象转换和放置到背景图像中。该外观合成器对前景对象的颜色、亮度和样式进行调整,并将其和谐地嵌入背景图像中,其中引入了一个用于细节保存的引导滤波器。这两个合成器相互连接,作为相互参照,可以在没有监督的情况下进行端到端训练。对SF-GAN在两个任务中进行了评估: (1)为训练更好的识别模型,进行了逼真的场景文本图像合成;(2)戴眼镜和帽子,与真人相匹配的眼镜和帽子。定性和定量的比较表明了所提出的SF-GAN的优越性。
网址:
https://arxiv.org/abs/1812.05840v2
代码链接:
https://github.com/fnzhan/SF-GAN
3、f-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning(任意样本学习的特征生成框架)
作者:Yongqin Xian, Saurabh Sharma, Bernt Schiele, Zeynep Akata
摘要:当标记的训练数据很少时,一种很有前途的数据增强方法是使用未知类的属性生成它们的视觉特征。为了学习CNN特征的类条件分布,这些模型依赖于成对的图像特征和类属性。因此,他们无法利用大量未标记的数据样本。在本文中,我们在一个统一的特征生成框架中处理任意样本学习问题,即零样本和少样本。我们建立了一个结合VAE和GANs的强度的条件生成模型,并通过一个无条件的判别器学习未标记图像的边缘特征分布。我们的实验表明,我们的模型学习了CUB、SUN、AWA和ImageNet这5个数据集的CNN特征,并建立了一种新的最前沿的任意样本学习,即归纳和转换(广义)零样本和少样本学习设置。我们还证明了我们所学习的特性是可解释的: 我们通过将它们反转回像素空间来对它们进行可视化,并通过生成文本参数来解释它们为什么与某个标签相关联。
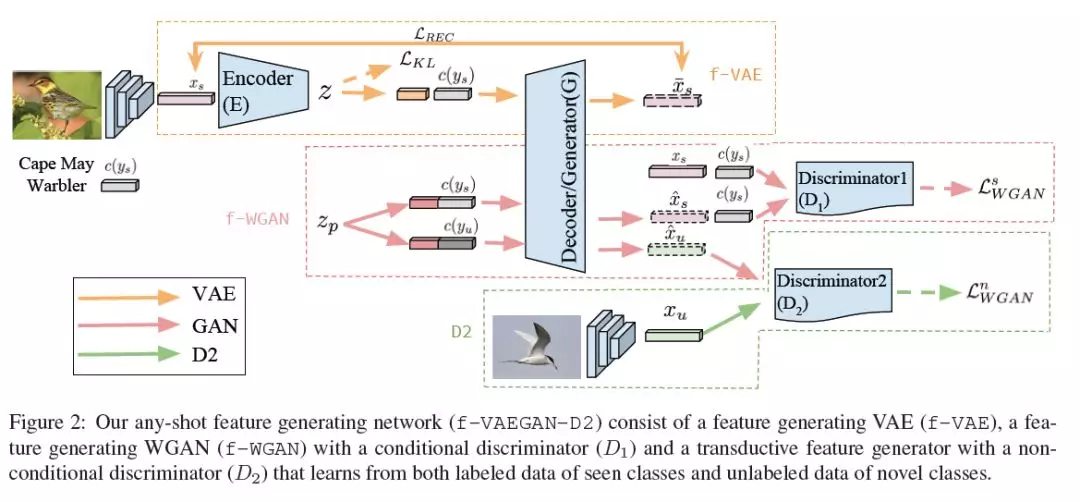
网址:
https://arxiv.org/abs/1903.10132v1
4、OCGAN: One-class Novelty Detection Using GANs with Constrained Latent Representations(OCGAN:使用具有约束潜在表征的GAN进行One-class异常检测)
作者:Pramuditha Perera, Ramesh Nallapati, Bing Xiang
摘要:针对单类异常检测的经典问题,提出了一种新的OCGAN模型,其中,给定一组来自特定类的示例,目标是确定查询示例是否来自同一类。我们的解决方案基于使用去噪自编码器网络学习类内示例的潜在表示。我们工作的关键贡献是我们显式地约束潜在空间,使其只表示给定的类。为了实现这一目标,首先,我们通过在编码器的输出层引入tanh激活函数来强制潜在空间获得有限的支持。其次,在反方向训练的潜在空间中使用判别器,保证了类内样本的编码表示形式类似于从同一有界空间抽取的均匀随机样本。第三,在输入空间中使用第二个对抗性判别器,确保所有随机抽取的潜在样本生成的示例看起来都是真实的。最后,我们介绍了一种基于梯度下降的采样技术,该技术探索潜在空间中的点,这些点生成潜在的类外示例,并将这些类外示例反馈给网络,进一步训练网络从这些点生成类内示例。该方法通过四个公开可用的数据集,使用两种one-class异常检测协议来证明其有效性,跟别的方法相比,我们的方法实现了最先进的结果。
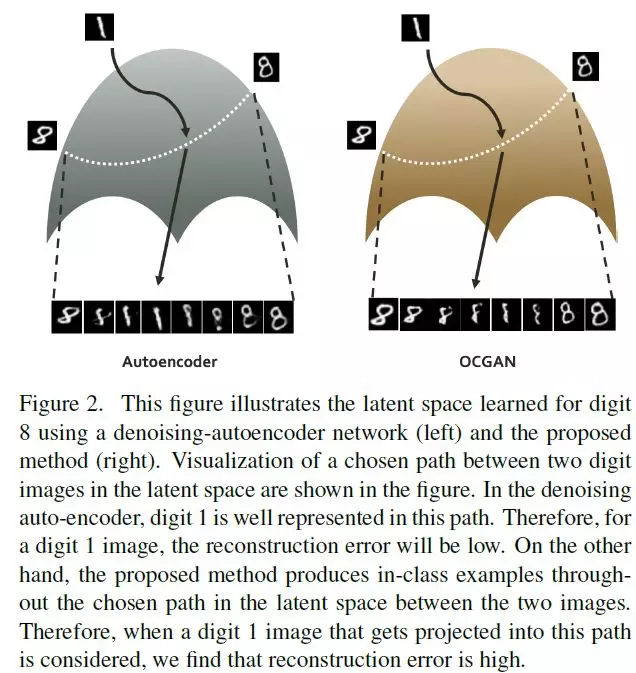
网址:
https://arxiv.org/abs/1903.08550v1
代码链接:
https://github.com/fidler-lab/curve-gcn
5、Event-based High Dynamic Range Image and Very High Frame Rate Video Generation using Conditional Generative Adversarial Networks(使用条件生成对抗网络生成基于事件的高动态范围图像和超高帧率视频)
作者:S. Mohammad Mostafavi I., Lin Wang, Yo-Sung Ho, Kuk-Jin Yoon
摘要:与传统相机相比,Event camera具有低延迟、高时间分辨率、高动态范围等优点。然而,由于Event camera的输出是超时的异步事件序列而不是实际强度图像,因此不能直接应用现有算法。因此,需要从事件中为其他任务生成强度图像。在本文中,我们揭开了基于Event camera的条件生成对抗网络的潜力,从事件数据流的可调部分创建图像/视频。利用事件的时空坐标栈作为输入,训练网络根据时空强度变化再现图像。并且,还证明了Event camera在极端光照条件下也能生成高动态范围(HDR)图像,在快速运动下也能生成非模糊图像。此外,还演示了生成非常高帧率视频的可能性,理论上可以达到每秒100万帧(FPS),因为Event camera的时间分辨率大约为1{\mu}s。通过与使用在线可用的真实数据集和Event camera模拟器生成的合成数据集在同一像素事件网格线上捕获的强度图像进行比较,对所提出的方法进行了评估。

网址:
https://arxiv.org/abs/1811.08230
6、GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction(GANFIT: 用于高保真三维人脸重建的生成对抗网络拟合)
作者:Baris Gecer, Stylianos Ploumpis, Irene Kotsia, Stefanos Zafeiriou
摘要:在过去的几年里,利用深度卷积神经网络(DCNNs)的强大功能,从单个图像中重建三维人脸结构已经做了大量的工作。在最近的研究中,我们使用了可微渲染器来学习人脸识别特征与三维形态和纹理模型参数之间的关系。纹理特征要么对应于线性纹理空间的组件,要么由自编码器直接从野外图像(in-the-wild images)中学习。在所有情况下,人脸纹理重建的最先进的方法仍然不能以高保真度来建模纹理。在这篇论文中,我们采取了一个完全不同的方法,利用生成对抗网络(GANs)和DCNNs的力量,从单一的图像重建面部纹理和形状。也就是说,我们利用GAN在UV空间中训练一个非常强大的面部纹理生成器。在此基础上,利用非线性优化方法,对原三维形态模型(3DMMs)拟合方法进行了重新研究,找到了最优的潜在参数,并在新的视角下对测试图像进行了重构。利用端到端可微框架,我们通过预先训练的深层身份特征来优化参数。我们在真实感和保真性的三维人脸重建方面取得了优异的效果,并首次实现了基于高频细节的人脸纹理重建。
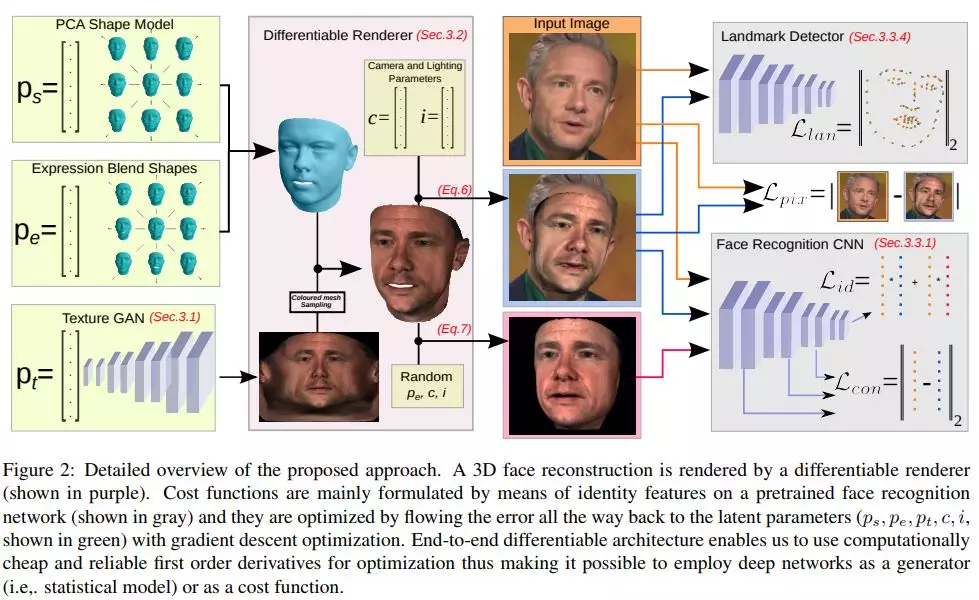
网址:
https://arxiv.org/abs/1902.05978
代码链接:
https://github.com/barisgecer/ganfit
7、Self-Supervised Generative Adversarial Networks(自监督生成对抗网络)
作者:Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lucic, Neil Houlsby
摘要:条件GAN是自然图像合成的前沿。这种模型的主要缺点是需要标记数据。在这项工作中,我们使用了两种流行的无监督学习技术,对抗性训练(adversarial training)和自监督(self-supervision),以缩小有条件和无条件GAN之间的差距。特别是,我们允许网络在表示学习的任务上进行协作,同时在经典的GAN游戏中具有对抗性。自监督的作用是鼓励discriminator学习有意义的特征表示,这些特征在训练中不会被遗忘。我们对学习图像表示的质量和合成图像的质量进行了经验检验。在相同条件下,自监督GAN获得与最先进的条件相似的性能。最后,我们证明了这种完全无监督学习的方法可以在无条件生成ImageNet时扩展到FID为33。
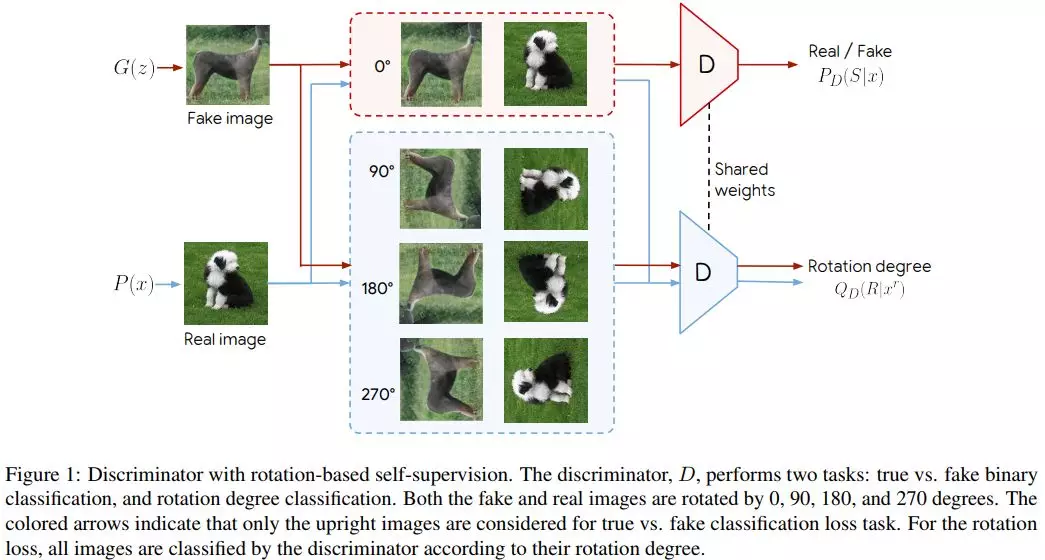
网址:
https://arxiv.org/abs/1811.11212
代码链接:
https://github.com/google/compare_gan
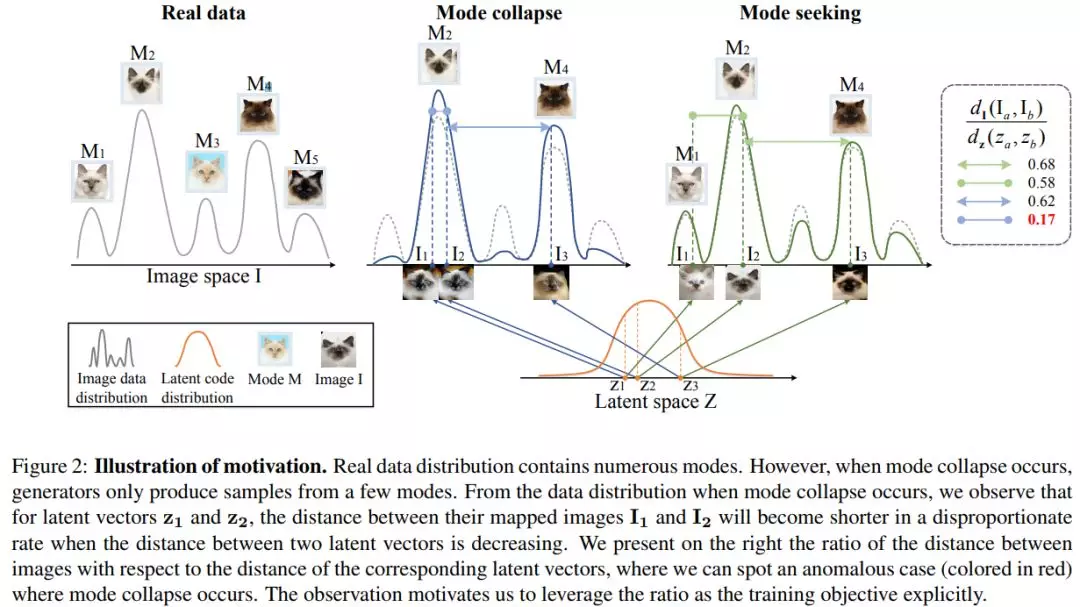
8、Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis(基于Mode Seeking的生成对抗网络方法应用于多种图像合成)
作者:Qi Mao, Hsin-Ying Lee, Hung-Yu Tseng, Siwei Ma, Ming-Hsuan Yang
摘要:大多数条件生成任务都期望给定一个条件上下文的不同输出。然而,条件生成对抗网络(cGANs)往往只关注先验条件信息,而忽略了输入噪声向量,从而导致了输出的变化。最近解决cGANs模式崩溃问题的尝试通常是特定于任务的,而且计算成本很高。在这项工作中,我们提出了一个简单而有效的正则化项来解决cGANs的模式崩溃问题。该方法显式地将生成的图像与对应的潜在编码(latent codes)之间的距离比值最大化,从而鼓励生成器在训练过程中探索更多的小模式。这种寻求正则化项的模式很容易适用于各种条件生成任务,而不需要增加训练开销或修改原有的网络结构。基于不同的baseline模型,我们在三个条件图像合成任务上验证了该算法的有效性,任务包括分类生成、图像到图像的转换、文本到图像的合成。定性和定量结果都证明了所提出的正则化方法在不损失质量的情况下提高多样性的有效性。
网址:
https://arxiv.org/abs/1903.10132v1
代码链接:
https://github.com/HelenMao/MSGAN
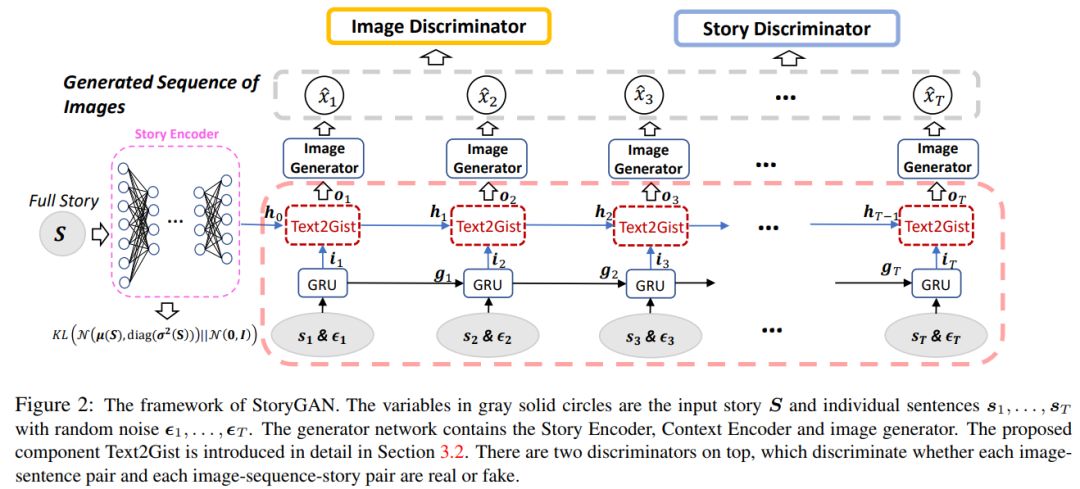
9、StoryGAN: A Sequential Conditional GAN for Story Visualization(StoryGAN: 序列条件GAN的故事可视化)
作者:Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, Jianfeng Gao
摘要:在这项工作中,我们提出了一个新的任务,称为故事可视化(Story Visualization)。给定一个多句的段落,通过为每个句子生成一个图像序列来可视化故事。与视频生成不同,故事可视化不太关注生成图像(帧)中的连续性,而是更关注动态场景和角色之间的全局一致性——这是任何单一图像或视频生成方法都无法解决的挑战。因此,我们提出了一个新的基于序列条件GAN框架的故事到图像序列生成模型StoryGAN。我们的模型的独特之处在于,它由一个动态跟踪故事流的深层上下文编码器和两个分别位于故事和图像级别的鉴别器组成,以提高图像质量和生成序列的一致性。为了评估模型,我们修改了现有的数据集,以创建CLEVR-SV和Pororo-SV数据集。从经验上看,StoryGAN在图像质量、上下文一致性度量和人类评估方面优于最先进的模型。
网址:
https://arxiv.org/abs/1809.01110
代码链接:
https://github.com/yitong91/StoryGAN
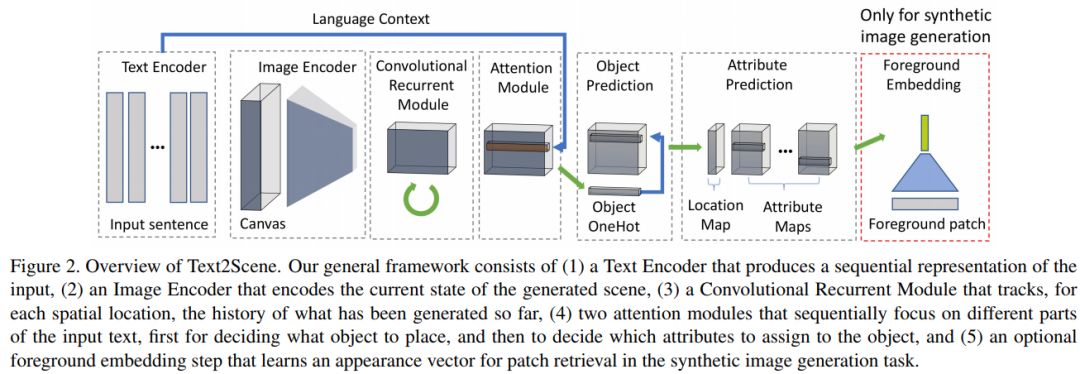
10、Text2Scene: 从文本描述生成合成场景(使用条件生成对抗网络生成基于事件的高动态范围图像和超高帧率视频)
作者:Fuwen Tan, Song Feng, Vicente Ordonez
摘要:我们提出了Text2Scene模型,该模型对输入的自然语言描述进行解释,以生成各种形式的合成场景表示;从抽象的卡通场景到合成图像。与最近的工作不同,我们的方法不使用生成对抗网络,而是将编码器-解码器模型与基于半参数检索的方法相结合。Text2Scene学习通过关注输入文本的不同部分以及生成场景的当前状态,在每一个时间步骤中依次生成对象及其属性(位置、大小、外观等)。我们表明,在微小的修改下,所提出的框架可以处理不同形式的场景表示的生成,包括卡通场景、与真实图像对应的对象布局以及合成图像组合。我们的方法不仅与最先进的基于GAN的自动度量方法和基于人类判断的方法相比具有竞争力,而且更通用、更易于解释。
网址:
https://arxiv.org/abs/1811.08230
下载链接:https://pan.baidu.com/s/1_6kTGXGmojKjIq1U1nITfg 提取码:lb7k