【泡泡一分钟】基于深度后继表示的视觉语义规划(ICCV2017-49)
每天一分钟,带你读遍机器人顶级会议文章
标题:Visual Semantic Planning using Deep Successor Representations
作者:Yuke Zhu, Daniel Gordon, Eric Kolve, Dieter Fox, Li Fei-Fei, Abhinav Gupta, Roozbeh Mottaghi, Ali Farhadi
来源:ICCV 2017 ( IEEE International Conference on Computer Vision)
播音员:水蘸墨
编译:张建 周平(51)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

真实世界智能代理的一个关键能力是他们在视觉世界中规划一系列动作以实现他们的目标的能力。
在这项工作中,我们解决视觉语义规划的问题:从视觉观察预测动作序列的任务,将动态环境从初始状态转换为目标状态。这样做需要的知识包括对象及其功能可见性,以及动作和他们的前提与效果。
我们提出通过与视觉和动态环境的交互来学习这些。我们提出的解决方案包含自举强化学习与模仿学习。为了确保跨任务的泛化,我们开发了一个基于后继表示的深度预测模型。
在具有挑战性的THOR环境中,在很宽范围内的任务下,我们的实验结果展示了接近最优的结果。
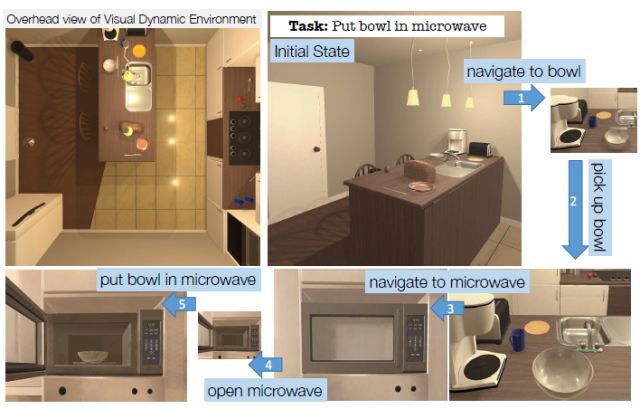
图1。给定任务和场景的初始配置,我们的代理学习与场景交互,并预测基于视觉输入来实现目标的动作序列。

图2。示例图像,演示在我们的框架中从六个动作类型中的每一个对象交互前后的状态变化。每一个动作改变视觉状态,并且某些动作可以实现进一步的交互,例如在从冰箱取出物体之前打开冰箱。

图3。我们后继表示(SR)模型的网络体系结构概述。我们的网络接受当前状态以及特定的行为,并预测立即奖励ra,s以及折扣的未来报酬Qa,s,对每个动作执行此评估。学习策略π将所有Q值的argmax作为其选择的动作。
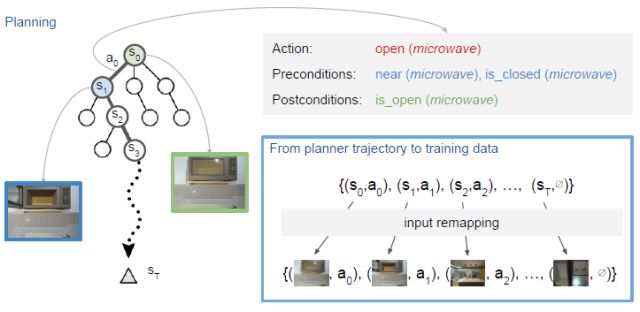
图4。我们使用一个规划器来生成从初始状态动作对(s0,a0)到目标状态sT的轨迹。我们用一种基于条形的规划语言来描述每一个场景,其中动作是由他们的前和后条件规定的。我们执行输入重新映射,在蓝色框中表示,从作为训练数据的轨迹中获得图像动作对。在执行一个动作之后,我们更新规划并重复。

Abstract
A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning. To ensure cross task generalization, we develop a deep predictive model based on successor representations. Our experimental results show near optimal results across a wide range of tasks in the challenging THOR environment.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




