
题目: Causal Discovery in Physical Systems from Videos
摘要:
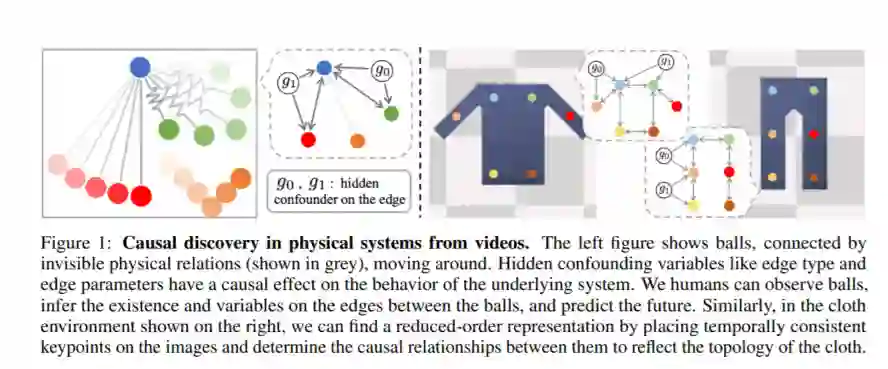
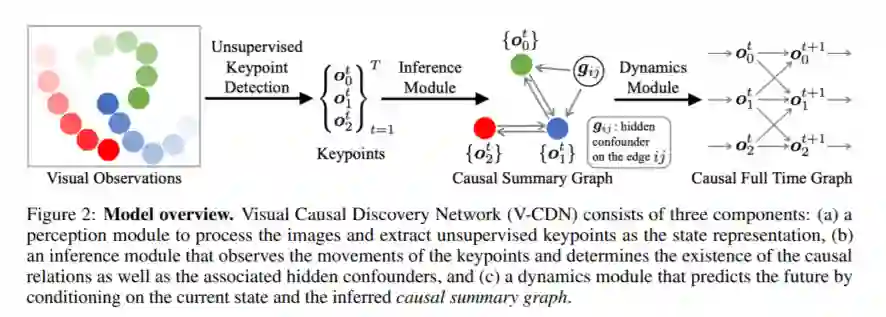
因果发现是人类认知的核心。它使我们能够对环境进行推理,并对看不见的场景做出反事实的预测,这可能与我们以前的经验大不相同。我们以端到端的方式考虑从视频中发现因果任务,而无需监督 ground-truth图结构。特别是,我们的目标是发现环境和对象变量之间的结构相关性:推断对动力系统的行为有因果关系的相互作用的类型和强度。该模型由(a)感知模块组成,该感知模块从图像中提取语义上有意义且时间上一致的关键点表示,(b)推论模块,用于确定由检测到的关键点引起的图形分布,(c)动力学模块,可以通过对推断的图进行调节来预测未来。假设可以访问不同的配置和环境条件,即来自底层系统未知干预的数据;因此,可以希望在没有明确干预的情况下发现正确的潜在因果图。我们在平面多体交互环境以及涉及衬衫和裤子等不同形状的织物的场景中评估了该方法。实验表明,该模型可以从短图像序列中正确识别相互作用,并做出长期的未来预测。模型所假设的因果结构还允许它进行反事实预测,并推断到看不见的交互图或各种大小的图系统。
成为VIP会员查看完整内容
相关内容
专知会员服务
36+阅读 · 2020年3月13日
相关主题


相关VIP内容
专知会员服务
36+阅读 · 2020年3月13日
相关资讯
相关论文