【泡泡一分钟】基于深度增强学习的目标驱动式室内场景视觉导航(ICRA-21)
每天一分钟,带你读遍机器人顶级会议文章
标题:Target-driven visual navigation in indoor scenes using deepreinforcement learning
作者:Yuke Zhu,Roozbeh Mottaghi,Eric Kolve, Joseph J. Lim,Abhinav Gupta, Li Fei-Fei, Ali Farhadi
来源:ICRA2017
播音员:申影
编译:赵博欣
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

今天介绍的文章是“Target-driven visual navigation in indoor scenes using deepreinforcement learning”——基于深度增强学习的目标驱动式室内场景视觉导航,该文章发表在ICRA2017。
深度增强学习中有以下两个问题较少得到解决:(1)缺少对新目标一般化的能力;(2)数据低效。即模型需要多个(且通常是昂贵的)试错集合才能收敛,使得它不适用于真实世界场景。本文则主要解决上述两个问题,并将我们的模型应用于目标驱动的视觉导航中。首先,为了解决第一个问题,我们提出一个行动-评价模型,该模型输出的策略是目标和当前状态的函数,这使得模型具备更好的一般化能力。为了解决第二个问题,本文提出AI2-THOR框架,它提供了一个具备高质量三维场景和物理引擎的环境,能够使智能体行动并与物体交互。因此,我们可以有效的搜集大量训练样本。(结果)表明我们提出的方法(1)比目前最新的深度增强学习算法收敛速度更快;(2)在目标和场景之间能够一般化;(3)可以推广到真实的机器人场景(尽管模型是在仿真环境下训练);(4)端到端训练,且不需要特征处理、帧与帧之间的特征匹配以及环境的三维重构。
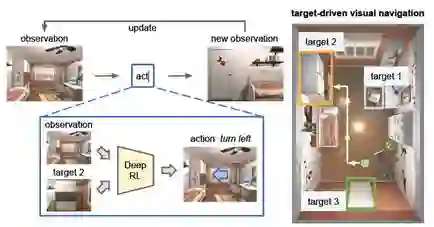
图1 本文深度增强学习模型的目标是以最少的步数导航到一个视觉目标。我们的模型以当前观测状态和目标图像为输入,以在三维场景中生成一个动作为输出。我们的模型学习导航到场景中的不同目标,而无需重新训练。
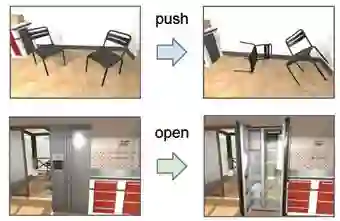
图3 本文的框架为智能体提供了一个丰富的交互平台。它支持物理交互,比如推动或移动物体(图第一行所示),也可以与物体交互,比如改变其状态(图中第二行所示)
Abstract
Two less addressed issues of deep reinforcementlearning are (1) lack of generalization capability to new goals, and (2) datainefficiency, i.e., the model requires several (and often costly) episodes oftrial and error to converge, which makes it impractical to be applied toreal-world scenarios. In this paper, we address these two issues and apply ourmodel to target-driven visual navigation. To address the first issue, wepropose an actor-critic model whose policy is a function of the goal as well asthe current state, which allows better generalization. To address the secondissue, we propose the AI2-THOR framework, which provides an environment withhigh-quality 3D scenes and a physics engine. Our framework enables agents totake actions and interact with objects. Hence, we can collect a huge number oftraining samples efficiently. We show that our proposed method (1) convergesfaster than the state-of-the-art deep reinforcement learning methods, (2)generalizes across targets and scenes, (3) generalizes to a real robot scenariowith a small amount of fine-tuning (although the model is trained insimulation), (4) is end-to-end trainable and does not need feature engineering,feature matching between frames or 3D reconstruction of the environment.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
回复关键词“TAR-NAV”,即可获取英文下载。

泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


