赛尔笔记 | 一文读懂图神经网络
作者:哈工大SCIR博士生 郑博
一、图神经网络介绍
什么是图神经网络
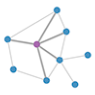
图神经网络(Graph Neural Networks, GNNs)是基于图结构的深度学习方法,近期被广泛应用到各类图像、自然语言处理等任务上。图神经网络作为神经网络扩展,可以处理以图结构表示的数据格式。在图中,每个节点都由本身的特性以及其相邻的节点和关系所定义,网络通过递归地聚合和转换相邻节点的表示向量来计算节点的表示向量。
在论文《Relational inductive biases, deep learning, and graph networks》中,作者定义了通用图网络框架graph networks (GN) framework,概括和扩展了各种图神经网络,并且支持使用简单的模块来构建复杂的结构。GN framework的主要计算单元是GN block,一个图到图的模块,它的输入是一个图,在图结构上进行计算,然后得到同样是图结构的输出。
在GN framework下,一个图可以被定义为一个三元组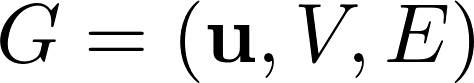

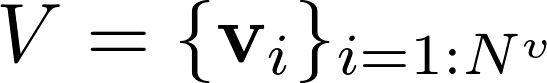

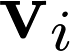
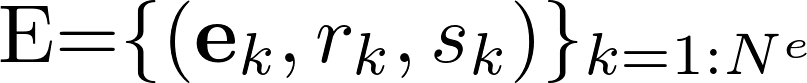
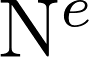
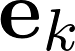
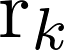
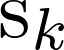
每一个GN block包含三个更新函数
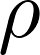
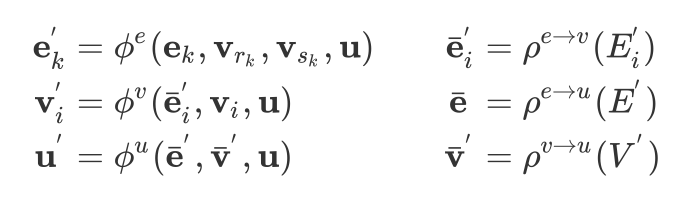
上式中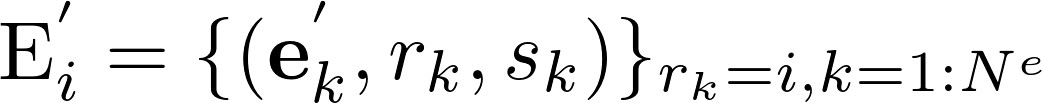
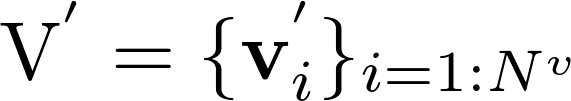
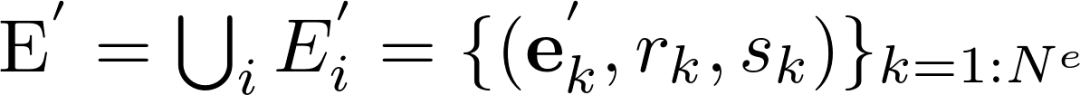
其中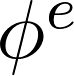
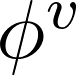
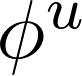
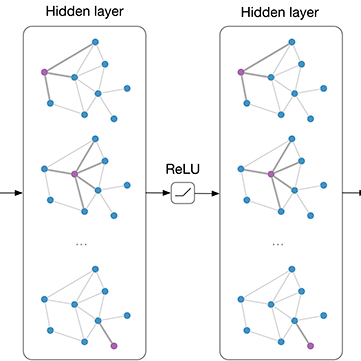
当一个GN block得到一个图
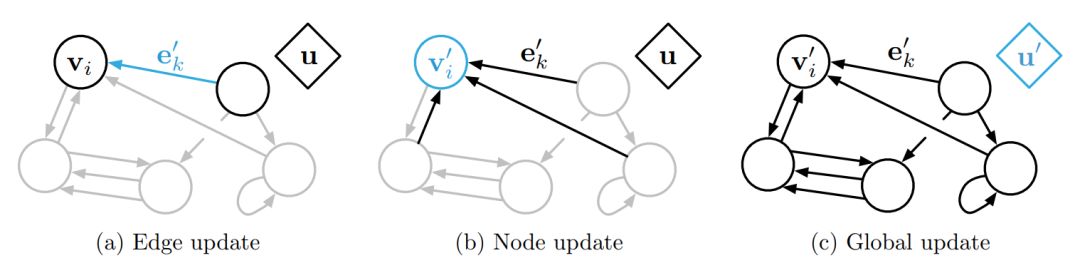
图1 一个GN block的更新过程
一个GN block的计算可以被描述为如下几步:
1. 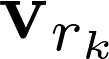
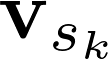
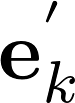
2. 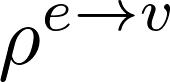
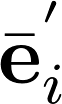
3. 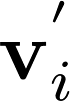
4. 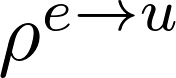
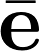
5. 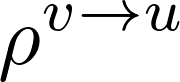
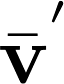
6. 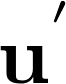
我们可以通过上述的更新步骤来套用目前的图神经网络算法,当然这里的步骤的顺序并不是严格固定的,比如可以先更新全局信息,再更新节点信息以及边的信息。
为什么要使用图神经网络
图神经网络有灵活的结构和更新方式,可以很好的表达一些数据本身的结构特性,除了一些自带图结构的数据集(如Cora,Citeseer等)以外,图神经网络目前也被应用在更多的任务上,比如文本摘要,文本分类和序列标注任务等,目前图神经网络以及其变种在很多任务上都取得了目前最好的结果。
比较常见的图神经网络算法主要有Graph Convolutional Network(GCN)和Graph Attention Network(GAT)等网络及其变种,在本文第三部分会给出基于图神经网络框架DGL的GCN以及GAT的代码及注解。
二、图神经网络库
相比于传统的基于邻接矩阵的图神经网络实现方法,目前完成度较好的图神经网络框架主要是基于PyTorch和MXNet的DGL (Deep Graph Library)和PyG (PyTorch Geometric)。笔者主要使用了DGL作为开发的框架,原因是各种网络模型的tutorial给的比较详尽,同时包括TreeLSTM这种经典模型也可以通过给定节点访问的顺序通过框架很轻松的实现,相比于不使用图网络框架的代码具有更强的可读性。
但是,实际上图神经网络框架只适用于图结构中的边和点是同一量级的情况,因为图神经网络框架的信息是通过图中的边来传递的,会将节点的表示复制多次。在这种情况下,反而不如使用邻接矩阵直接做矩阵乘法,因为使用邻接矩阵做矩阵乘法其实不会将节点信息复制多次,会对显存有极大的节省。
三、常见算法以及代码示例详解
GCN
GCN的计算公式如下:
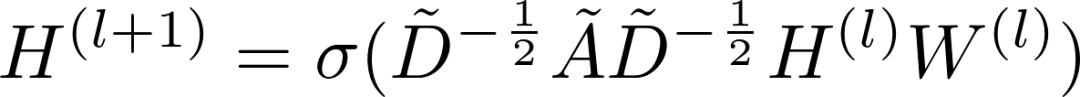
上式中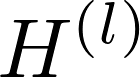

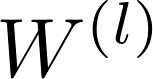
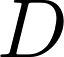
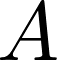
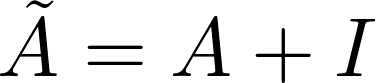
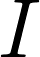
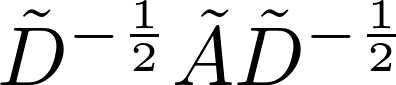
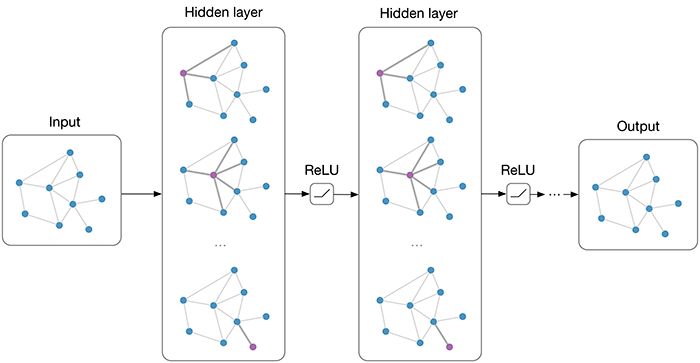
图2 在每一层图网络中,每个节点通过对邻近节点的信息聚合得到这层该节点的输出
相比于前文给出的GCN基于邻接矩阵的公式定义,GCN的公式可以被更简洁的定义为以下两步:
1)对于节点u,首先将节点邻居表示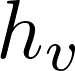
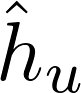
2)将得到的中间表示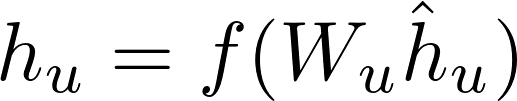
下面为基于DGL的代码示例,在代码实现中,第一步通过DGL自带的message passing函数实现,第二步通过DGL的apply_nodes方法,将基于PyTorch中nn.Module的用户自定义函数加入实现:
1import dgl
2import dgl.function as fn
3import torch as th
4import torch.nn as nn
5import torch.nn.functional as F
6from dgl import DGLGraph
7
8gcn_msg = fn.copy_src(src='h', out='m')
9gcn_reduce = fn.sum(msg='m', out='h')
接下来为apply_nodes定义更新节点的自定义函数,这里是一个线性变换加上一个非线性激活函数的网络层:
1class NodeApplyModule(nn.Module):
2 def __init__(self, in_feats, out_feats, activation):
3 super(NodeApplyModule, self).__init__()
4 self.linear = nn.Linear(in_feats, out_feats)
5 self.activation = activation
6
7 def forward(self, node):
8 h = self.linear(node.data['h'])
9 h = self.activation(h)
10 return {'h' : h}
下面定义GCN模块,一层GCN首先通过update_all方法将节点信息通过边传递,然后通过apply_nodes得到新的节点表示:
1class GCN(nn.Module):
2 def __init__(self, in_feats, out_feats, activation):
3 super(GCN, self).__init__()
4 self.apply_mod = NodeApplyModule(in_feats, out_feats, activation)
5
6 def forward(self, g, feature):
7 g.ndata['h'] = feature
8 g.update_all(gcn_msg, gcn_reduce)
9 g.apply_nodes(func=self.apply_mod)
10 return g.ndata.pop('h')
整个网络模块的定义和Pytorch中的NN模型定义本质上相同,如下我们定义两个GCN网络层:
1class Net(nn.Module):
2 def __init__(self, in_dim, hidden_dim, out_dim):
3 super(Net, self).__init__()
4 self.gcn1 = GCN(in_dim, hidden_dim, F.relu)
5 self.gcn2 = GCN(hidden_dim, out_dim, F.relu)
6
7 def forward(self, g, features):
8 x = self.gcn1(g, features)
9 x = self.gcn2(g, x)
10 return x
11net = Net()
12print(net)GAT
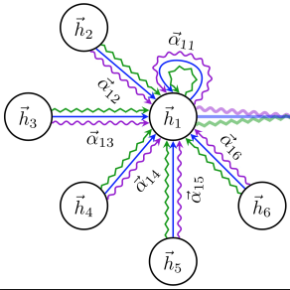
GAT和GCN的主要区别就在于邻近节点信息的聚合方式,GAT通过引入attention机制来替代GCN中的静态归一化卷积运算,下面给出使用 l 层网络输出来计算第 l+1 层网络输出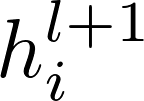
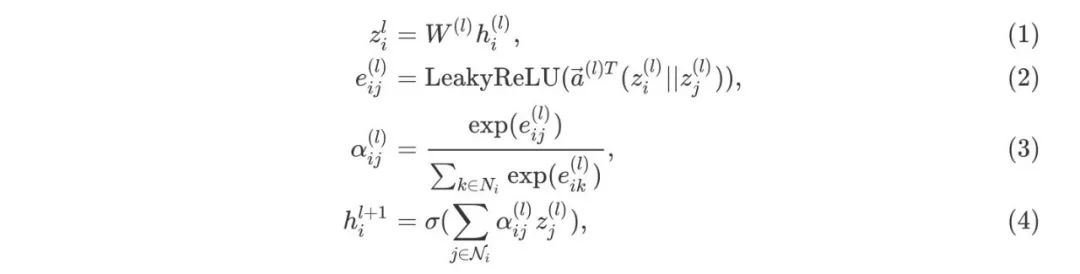
在上式中,公式(1)为上一层节点表示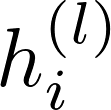
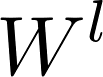
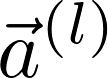
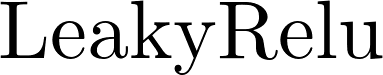
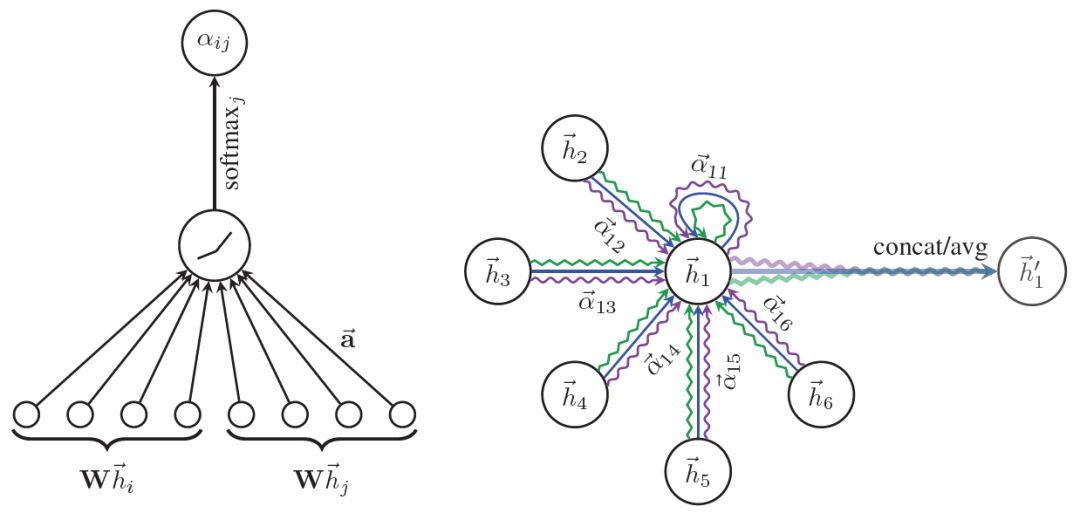
图3 Graph Attention Networks计算attention分数以及更新节点表示
下面的基于DGL的代码逐一分解了上面的四个公式,公式(1)中的线性变换直接使用Pytorch中的torch.nn.Linear模块
1import torch
2import torch.nn as nn
3import torch.nn.functional as F
4
5class GATLayer(nn.Module):
6 def __init__(self, g, in_dim, out_dim):
7 super(GATLayer, self).__init__()
8 self.g = g
9 # equation (1)
10 self.fc = nn.Linear(in_dim, out_dim, bias=False)
11 # equation (2)
12 self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
13
14
15 def edge_attention(self, edges):
16 # edge UDF for equation (2)
17 z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
18 a = self.attn_fc(z2)
19 return {'e': F.leaky_relu(a)}
20
21
22 def message_func(self, edges):
23 # message UDF for equation (3) & (4)
24 return {'z': edges.src['z'], 'e': edges.data['e']}
25
26
27 def reduce_func(self, nodes):
28 # reduce UDF for equation (3) & (4)
29 # equation (3)
30 alpha = F.softmax(nodes.mailbox['e'], dim=1)
31 # equation (4)
32 h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
33 return {'h': h}
34
35
36 def forward(self, h):
37 # equation (1)
38 z = self.fc(h)
39 self.g.ndata['z'] = z
40 # equation (2)
41 self.g.apply_edges(self.edge_attention)
42 # equation (3) & (4)
43 self.g.update_all(self.message_func, self.reduce_func)
44 return self.g.ndata.pop('h')公式(2)中的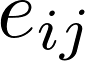
apply_edgesAPI来实现,参数是下面的自定义函数edge_attention:
1def edge_attention(self, edges):
2 # edge UDF for equation (2)
3 z2 = torch.cat([edges.src['z'], edges.dst['z']], dim=1)
4 a = self.attn_fc(z2)
5 return {'e' : F.leaky_relu(a)}这里和可学习权重向量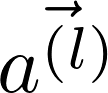
attn_fc得到,这里apply_edge会将所有的边的数据放到一个tensor里,所以cat,attn_fc可以并行计算,这也是上文提到的如果边的数量比点的数量多一个量级,最好还是使用邻接矩阵的方式实现图网络的原因,因为会将点的信息复制多次。
对于公式(3)和公式(4),使用update_allAPI来实现所有节点的信息传递,message function会发送两部分信息:经过变换的表示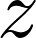
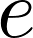
1def reduce_func(self, nodes):
2 # reduce UDF for equation (3) & (4)
3 # equation (3)
4 alpha = F.softmax(nodes.mailbox['e'], dim=1)
5 # equation (4)
6 h = torch.sum(alpha * nodes.mailbox['z'], dim=1)
7 return {'h' : h}
GAT同样使用了类似Transformer的Multi-head Attention,用来加强模型表达能力并且稳定学习过程。每一个attention head有自己独立的参数,可以通过两种方式合并它们的输出:
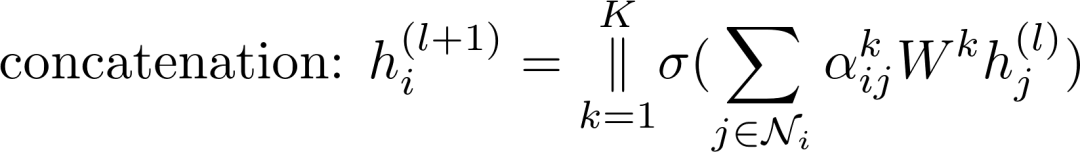
或者
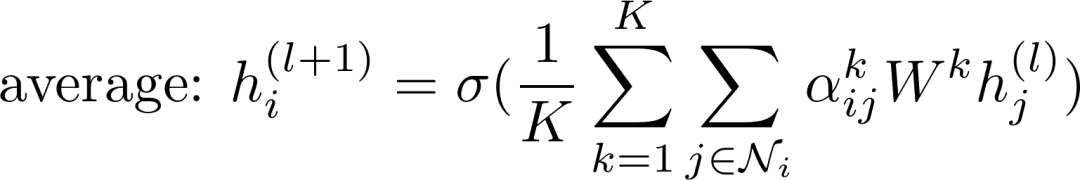
上式中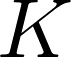
1class MultiHeadGATLayer(nn.Module):
2 def __init__(self, g, in_dim, out_dim, num_heads, merge='cat'):
3 super(MultiHeadGATLayer, self).__init__()
4 self.heads = nn.ModuleList()
5 for i in range(num_heads):
6 self.heads.append(GATLayer(g, in_dim, out_dim))
7 self.merge = merge
8
9
10 def forward(self, h):
11 head_outs = [attn_head(h) for attn_head in self.heads]
12 if self.merge == 'cat':
13 # concat on the output feature dimension (dim=1)
14 return torch.cat(head_outs, dim=1)
15 else:
16 # merge using average
17 return torch.mean(torch.stack(head_outs))
最后定义一个两层的GAT模型
1class GAT(nn.Module):
2 def __init__(self, g, in_dim, hidden_dim, out_dim, num_heads):
3 super(GAT, self).__init__()
4 self.layer1 = MultiHeadGATLayer(g, in_dim, hidden_dim, num_heads)
5 # Be aware that the input dimension is hidden_dim*num_heads since
6 # multiple head outputs are concatenated together. Also, only
7 # one attention head in the output layer.
8 self.layer2 = MultiHeadGATLayer(g, hidden_dim * num_heads, out_dim, 1)
9
10
11 def forward(self, h):
12 h = self.layer1(h)
13 h = F.elu(h)
14 h = self.layer2(h)
15 return h
上面GAT和GCN的详细代码可以在DGL的Github(https://github.com/dmlc/dgl)上找到。
四、总结
图神经网络在近期的研究中被广泛应用,作者结合参考资料和自身对图神经网络的理解,总结了一个快速上手的简要教程。除了在一些有着天然图结构的任务,图神经网络也可以应用在自然语言处理任务中,可以在模型中更好地表示信息。本文还给出了基于图神经网络框架DGL的GCN和GAT的代码及注解,但是根据实际使用经验,图神经网络框架在处理边数量比节点数量多一个量级的情况下,会比使用邻接矩阵的写法占用更多的内存,还是需要根据具体情况来选择使用。
五、参考资料
[1] https://docs.dgl.ai/
[2] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks.In ICLR, 2016
[3] Battaglia, P. W., Hamrick, J. B., Bapst, V., SanchezGonzalez, A., Zambaldi, V., Malinowski, M., Tacchetti, A., Raposo, D., Santoro, A., Faulkner, R., et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
[4] Zhou, J., Cui, G., Zhang, Z., Yang, C., Liu, Z., and Sun, M. Graph neural networks: A review of methods and applications. arXiv preprint arXiv:1812.08434, 2018.
本期责任编辑:丁 效
本期编辑:刘元兴
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:李家琦,赖勇魁,王若珂,李照鹏,冯梓娴,顾宇轩
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号:”哈工大SCIR” 。