图上的归纳表示学习

简介:
Network Embedding 旨在为图中的每个顶点获得特征表示。近年的Deepwalk,LINE, node2vec, SDNE, DNGR等模型能够高效地、直推式(transductive)地得到节点的embedding。然而,这些方法无法有效适应动态图中新增节点的需求, 往往需要从头训练或至少局部重训练。本篇文章提出一种适用于大规模网络的归纳式(inductive)学习方法-GraphSAGE,能够为新 增节点快速生成embedding,而无需额外训练过程。
模型:
大部分直推式表示学习的主要问题有:
1)缺乏权值共享(Deepwalk, LINE, node2vec)。节点的embedding直接是一个N*d的矩阵, 互相之间没有共享学习参数。
2)输入维度固定为|V|。无论是基于skip-gram的浅层模型还是基于autoencoder的深层模型,输入的维度都是点集的大小。上面两个问题限制了模型泛化到动态图的能力,新增节点会导致点集扩大到|v'|,而原始网络的输入只能是|V|。
因此,本文提出了一个邻居聚集的方法。主要步骤分为三部分:
1)邻居采样。因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居。
2)邻居特征聚集。通过聚集采样到的邻居特征,更新当前节点的特征。网络第k层聚集到的 邻居即为BFS过程第k层的邻居。
3)训练。既可以用获得的embedding预测节点的上下文信息(context),也可以利用embedding做有监督训练。
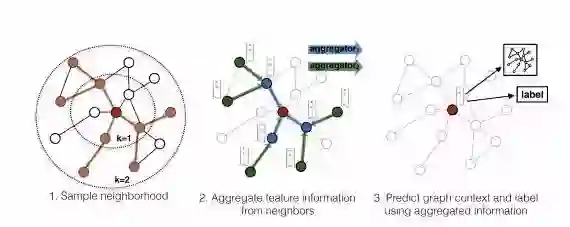
采样过程使用均匀采样;聚集函数分别试验了MEAN,LSTM,Pooling;训练时的损失函数定义为:
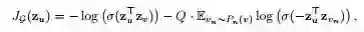
可以看出,也是采用了负采样的优化方法。在训练好网络的参数后,生成新加入节点的方式是:

实验:
本文选用了Citation,Reddit和PPI数据集,在inductive learning任务上,GraphSAGE远远超过其它基准模型,尤其是在有监督任务上。 在PPI数据集上,即使是在训练过程中完全未见过的图上也有很好的泛化性能。
总结:
GraphSAGE是inductive network embedding领域的重要工作,使得动态图的嵌入变得高效,但是邻居采样以及特征聚集方法仍有可提升空间。 这篇文章受到了广泛地关注,后续很多工作都是在此工作上的拓展和提升,比如将邻居的均匀采样过程用attention来替代,赋予不同邻居不同的权重等。
根据论文启发,对应综合动态静态结合的数据的建模思路。数据: 静态信息 ---multi-hot形式的向量,表示商品的静态属性。动态信息---是用户行为对每个商品的行为的异构事件序列。背景信息---如时间节日,季节等。问题: 动态地推荐Top-N商品。