知识图注意力网络 KGAT
自经典的GAT之后,各种花式图注意力网络层出不穷. 例如, 动态图注意力网络,异质图注意力网络, 知识图注意力网络. 本文介绍了用于推荐的知识图注意力网络KGAT,发表在KDD2019.
作者: 黄海兵
编辑: Houye

协同过滤CF算法利用用户的行为信息进行偏好预测,该方法在推荐系统里有较好的应用。但是CF算法不能对其他信息(比如商品的属性、用户信息、上文下)进行建模,而且在用户-商品交互信息较少的数据上表现较差。
为了能把其他信息利用起来,学术界常用的做法是:将用户跟商品都用embedded向量进行表示,然后将他们输入监督学习的模型里训练,将用户表示与商品表示的相关性作为训练目标。这里相关工作有:factorization machine (FM) [7], NFM (neural FM) [6], Wide&Deep [5], DCN[4],and xDeepFM [3]等。
扩展一下(加点小菜):
FM:在线性回归的基础上加入二阶线性特征。 ,优点:考虑二阶特征之间的相互作用。缺点:仅仅考虑线性特征,没有加入非线性特征。
NFM:融合了FM提取二阶线性特征与神经网络提取高阶非线性特征的两者优点。 ,其中f(x)是用神经网络对输入特征x进行特征抽取建模。
Wide&Deep:模型包括两个部分,分别为Wide部分和Deep部分,Wide部分如图1的左图所示,Deep部分如下图中的右图所示。Wide模型就是一个广义线性模型,Wide模型是前馈神经网络。两种模型进行联合训练,将两个模型的结果加权求和作为最终的预测结果。
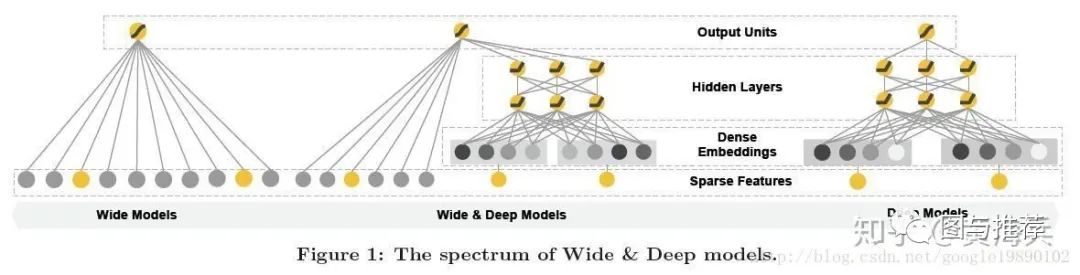
虽然这些模型都能取得不错的效果,但是这些模型有个缺点:将训练数据里(用户交互数据)的特征进行独立建模,没有考虑到交互数据之间的关系。这使得这些模型不足以从用户的行为中提取出基于属性的协同信息。
比如下图2中,用户u1看了电影 i1,这个电影是e1导演的,传统的CF方法会着重去找那些也看了电影i1的用户,比如u4跟u5。而监督学习方法会重点关注那些有相同属性e1的电影,比如i2。很显然这两类信息都可以作为推荐信息的补充,但是现有的模型不能做到上面两者信息的融合,而且这里的高阶关系也可以作为推荐信息的补充的。比如图中黄色框图里的用户看了同样由e1导演的电影i2, 还有灰色框图里电影同样也有e1的参与。
为了解决上面提到的问题,本文提出 collaborative knowledge graph (CKG)方法,将图谱关系信息及用户user点击商品item的交互图融合到一个图空间里。这样就可以融合CF信息及KG信息,同时也可以通过CKG发现高阶的关系信息。
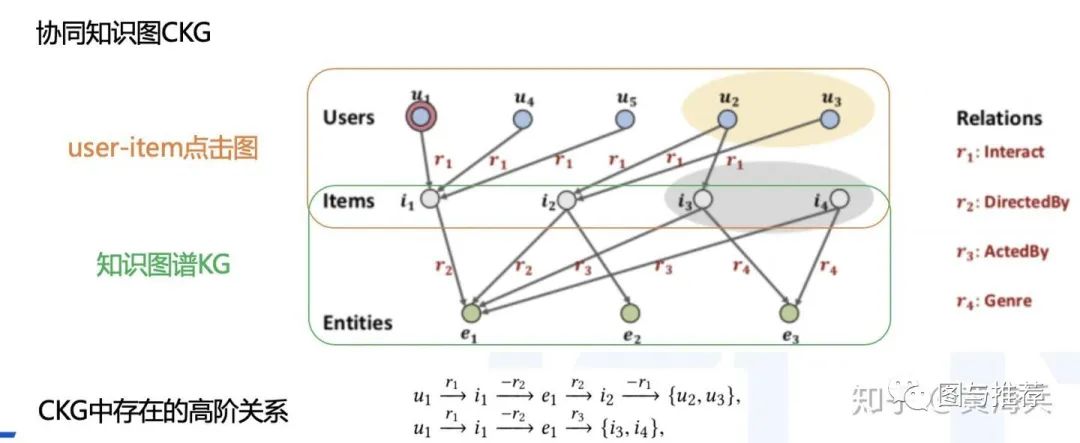
本文的贡献:
-
强调了在CKG中显式建模高阶关系信息的重要性,以便提供更多信息的用于推荐。 -
提出来一种新的推荐方法KGAT,该方法在图神经网络框架下以显式且端到端的方式实现了高阶关系的建模。 -
我们在三个公开基准上进行了大量实验,证明了KGAT的有效性及其在理解高级关系重要性方面的可解释性。
模型介绍
模型输入:用户u、实体i,CKG G
模型输出:输出用户u喜欢实体i的概率值 .
下图3是KGAT模型的框图,模型有三部分组成:CKG Embedding Layer、Attentive Embedding Propagation Layers、Prediction Layer。
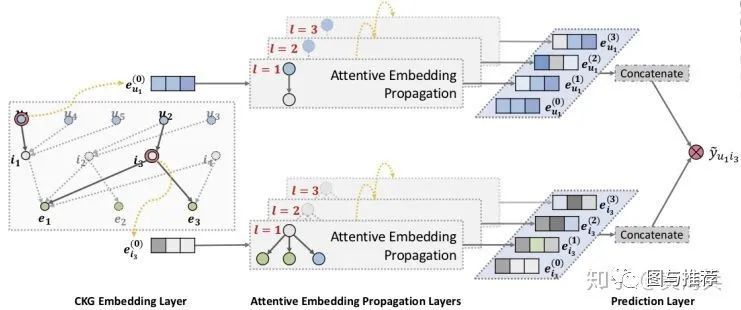
图3:KGAT模型框图 CKG Embedding Layer:
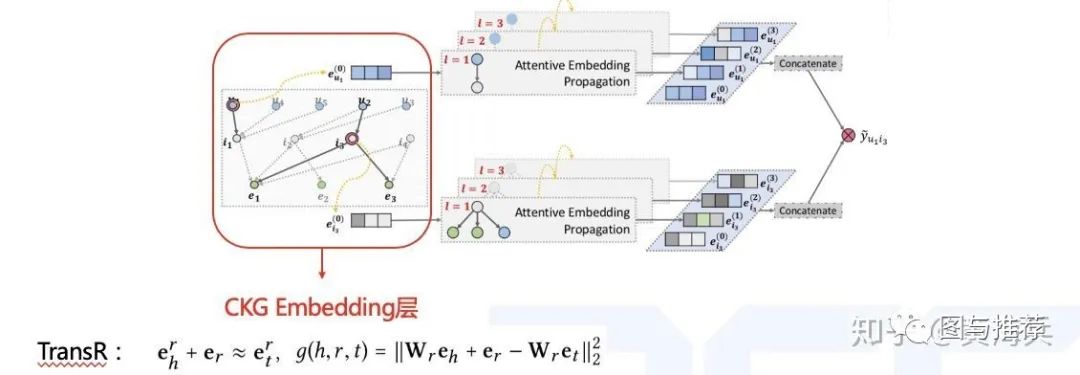
图谱embedded是在保留图结构的同时将实体和关系参数化为矩阵表示的有效方法,这里需要用到图谱关系假设transR: ,这个公式可以理解为:好的图谱三元组(h,r,t)中头结点h乘一个转化矩阵M与关系r相加后应该近似等于尾结点t乘以关系矩阵M。
公式1中 分数越低,说明这个图谱三元组越可信。我们可以通过优化下面的pair-wise的loss 来实现提升图谱embedded的表示能力。
Attentive Embedding Propagation Layers:该部分主要有三部分组成,分别是信息传播(Information Propagation),基于知识的注意力(Knowledge-aware Attention),信息聚合(Information Aggregation),最后是讨论如何实现多层表示。
信息传播:与头结点h相邻的尾结点t组成ego网络,ego网络的embedded表示 由所有尾结点加权得到;
基于知识的注意力:信息传播中的权重是按照attention方式计算得到;
信息聚合:当前节点h的表示 由两部分组成,一个节点h自身的 ,一个是h的ego网络表示 ,通过函数 得到。这里选择用选择两种交互(Bi-Interaction)方式(相加与点乘)相加得到最终表示 。
多层表示:类似于multi head,通过增加层数探索高阶连通信息。第 层的 由上一层的 与 通过信息聚合函数算的。
Prediction Layer:预测层将Attentive Embedding Propagation Layers层得到的多层用户表示 及多层item表示 进行相乘得到相关性得分 ,其中,用户user与商品item的多层表示是只是将每层表示连接即可。
损失函数:CF对应pair-wise的loss+图谱loss+参数正则loss
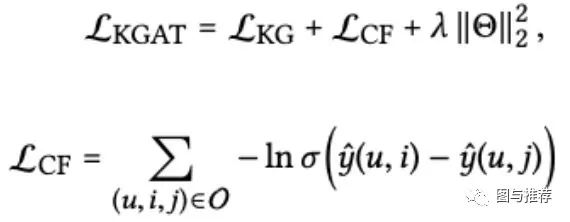
训练方法:训练时用mini-batch Adam方式的交替训练 与 .
代码讲解:(吃完正餐,再来点点心消化一下)
-
数据预处理:
需要首先将user 与 item交互图及图谱KG id化。
-
模型训练:
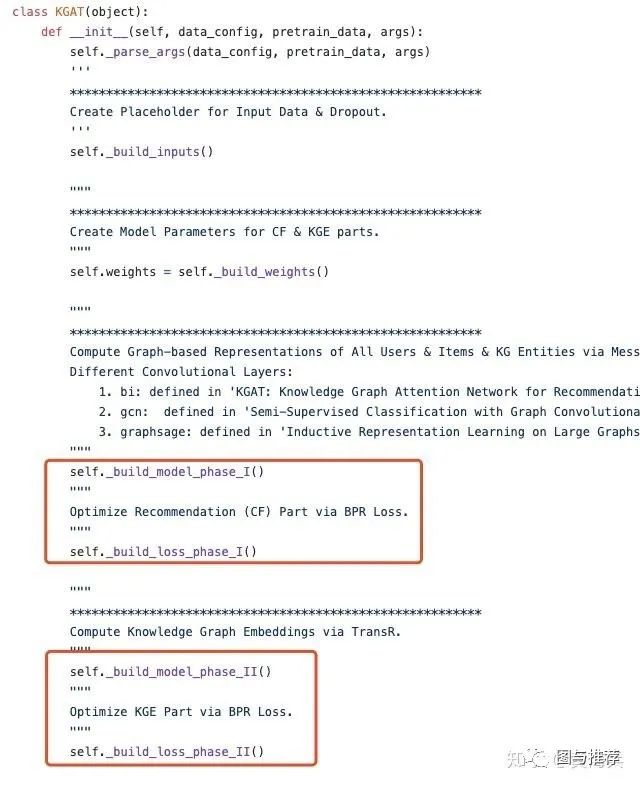
main.py:交替训练CF及KG的loss

KGAT.py: KGAT模型构建,对应main.py里两部分训练:model是训练CF的图结构,model1是训练KG的图结构。
loader_kgat.py: CF及KG数据加载
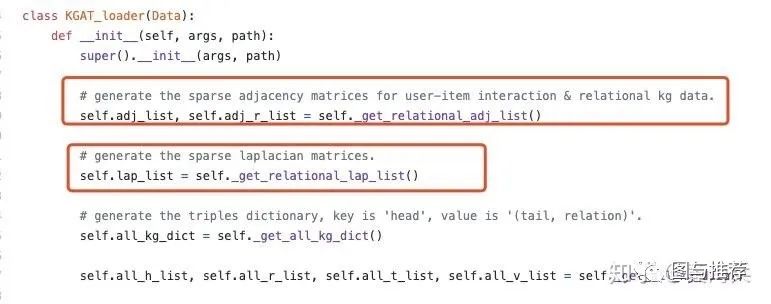
这里重点讲一下:get_lational_adj_list函数跟_get_relational_lap_list函数:
get_lational_adj_list:用稀疏矩阵变量adj_*mat_*list存储CF与KG的连通信息。

_get_relational_lap_list:主要是上一步得到的稀疏CF及KG连通矩阵进行归一化操作。

这里重点说一下为啥需要归一化:原始的连通矩阵是没有归一化的,如果没有归一化的连通矩阵与特征矩阵相乘会改变特征的原本分布,产生一些不可预测的问题,所以需要对连通矩阵进行标准化处理。
至此,美味的大餐就要结束了,希望大家用餐愉快,也欢迎各路大神一起交流厨艺。参考文献:
https://arxiv.org/pdf/1803.03467.pdf 2.https://arxiv.org/pdf/1905.07854.pdf
3.https://arxiv.org/pdf/1803.05170.pdf
4.https://arxiv.org/pdf/1708.05123.pdf
5.https://arxiv.org/abs/1606.07792
6.https://arxiv.org/pdf/1708.05027&ie=utf-8&sc_us=6917339300733978278.pdf
7.https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf


