对Reformer的深入解读

作者:Madison May
编译:ronghuaiyang
Reformer之前已经提过几次,这次带大家更加深入的了解一下这个方法的思想及背后的动机。

自从最初的"Attention is All You Need"论文在NLP社区掀起了Transformer热潮,似乎我们一直在不懈地追求更大的模型。在2019年夏天,英伟达发布了他们的MegatronLM论文 —— 83亿参数。在2020年2月,微软再次加大赌注,发布了一篇关于Turing-NLG的博客文章,拥有170亿个参数。
理解当我们增加参数数量和训练数据的时候,这些模型能到什么程度肯定是有价值的,我很高兴有这些资源可以进行大规模实验的公司已经这么做了。但是,相比来说,我们在如何把Transformer架构变的更加高效这件事情上,投入的太少了。
"Reformer: The Efficient Transformer" 来自 Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya ,与过去两年的“越大越好”的趋势形成了鲜明的对比,并在2020年的ICLR进行了报告。Reformer的论文读起来就像呼吸了一股清新的空气 —— 这篇文章主要关注自注意力操作是如何随序列长度扩展的,并提出了一种替代的注意了机制,可以将来自更长的上下文的信息整合到语言模型中。
使用Reformer对Transformer的改变,可以在单个加速器上对长度为64000的序列进行注意力操作,相比于 MegatronLM和TuringNLP中的1024的上下文长度,形成了鲜明的对比。这两个模型都采用了模型并行管道来拷贝大量的参数。
Self-Attention的回顾
在深入研究Reformer体系结构的细节之前,让我们简要回顾一下self-attention的形成过程,以获得一些在合并长上下文中所遇到的困难的背景知识。
为了简单起见,我们只讨论与单头的点积注意力,尽管在实践中使用了多头注意力。
如果你想要更深入的回顾一下self-attention机制,我强烈推荐Alexander Rush的Annotated Transformer,还有Jay Alammar的Illustrated Transformer。
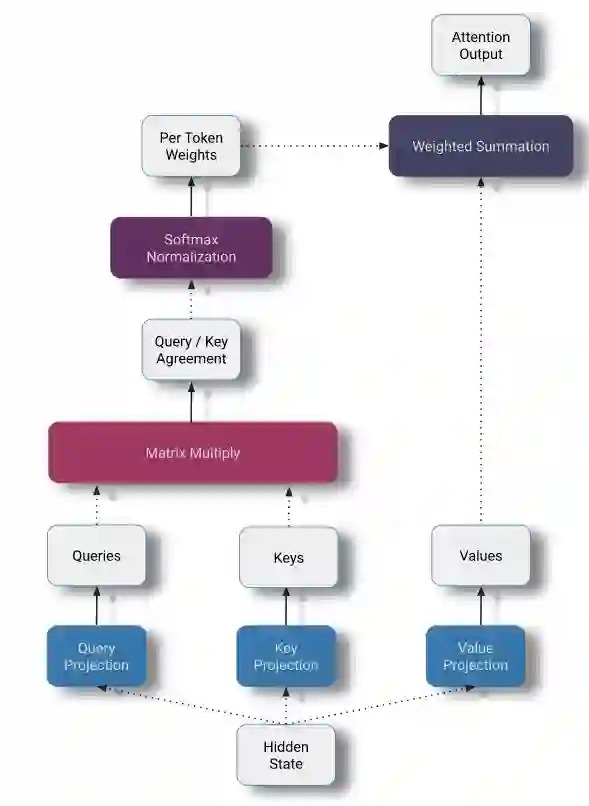
我们可以把self-attention分为三个主要部分:
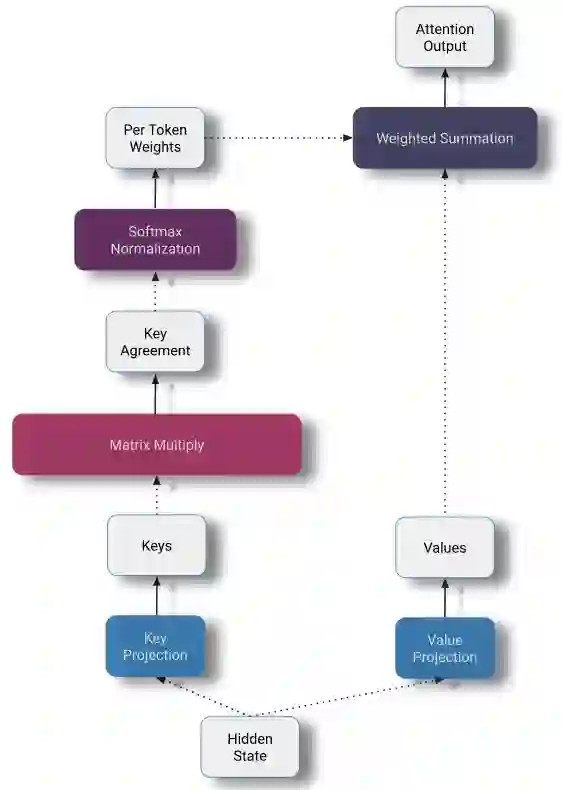
Query - Key - Value投影
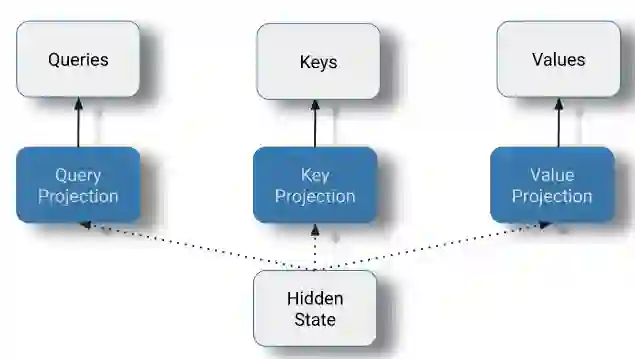
在此阶段,每个token的当前隐藏状态通过线性投影分解为三个部分。
queries = np.matmul(query_weights, hidden) + query_bias
keys = np.matmul(key_weights, hidden) + key_bias
values = np.matmul(value_weights, hidden) + value_bias
Query / Key矩阵乘法
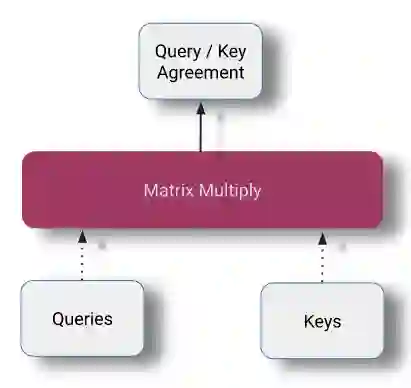
在投影之后,将queries和keys相乘以计算两两的相似度。这是用矩阵乘法实现的。
qk_agreement = np.matmul(queries, np.swapaxes(keys, -1, -2))
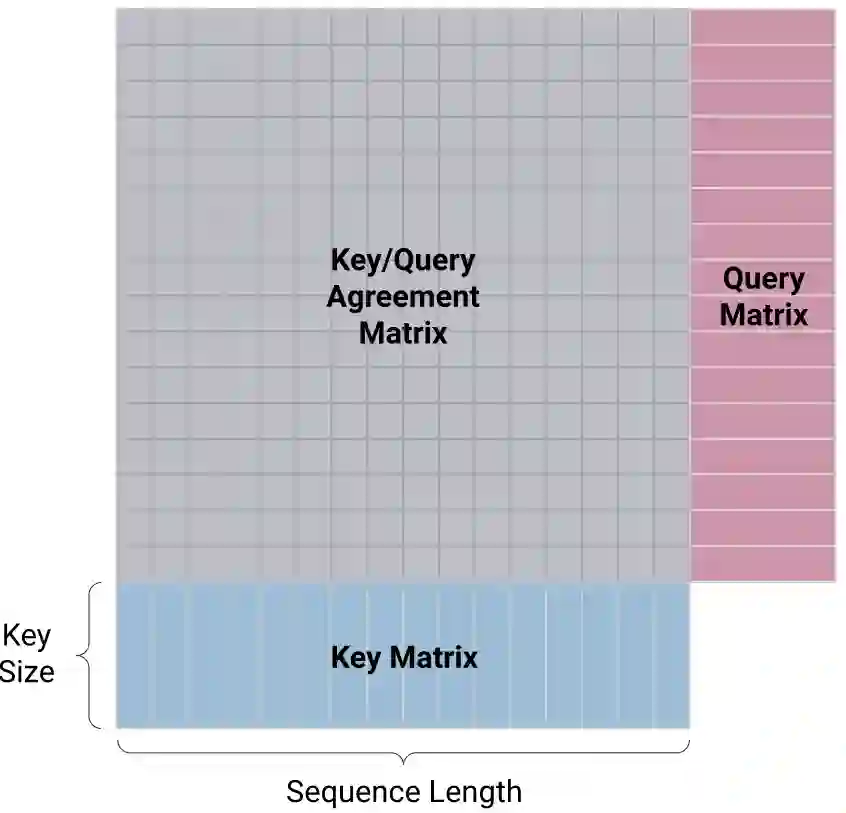
如果你的keys和queries是形状为(batch, sequence_length, hidden_size)的张量,那么矩阵乘法的输出就是形状为(batch, sequence_length, sequence_length)的张量。
这种看似无关紧要的矩阵乘法正是这种self-attention操作的计算复杂性问题的根源。对于序列长度的线性增加,计算输出所需的乘法次数以平方方式增加,因为我们需要为输入中每一对可能的token计算相似性。这O(L²)的复杂性意味着序列的长度超过1024的token使用原始的transformer结构是不切实际的。事实上,BERT和它的继任者RoBERTa中所选择的上下文长度只有512。
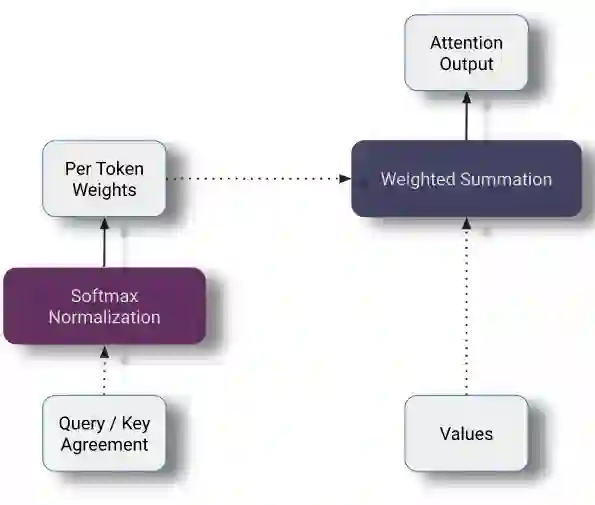
Softmax + Values的加权和
key / value 协同矩阵中的项除以了一个缩放因子sqrt(hidden_size),用来消除hidden size这个参数对注意力分布的影响。对于每个query,我们在所有keys上计算一个softmax,以确保矩阵的每一行和为1—— 确保新的隐藏状态的大小不依赖于序列长度。最后,我们用我们的注意力矩阵乘以我们的values矩阵,为每个token生成一个新的隐藏表示。
attention_weights = softmax(qk_agreement / qk_agreement.shape[-1])
attention_outputs = np.matmul(attention_weights, values)
计算复杂度 — 解决方案
如前所述,虽然点积注意力方式非常好用,允许任意的token在我们的上下文中从任何其他的token中聚合信息,这种灵活性是有代价的,一个不幸的O (L²)计算复杂度。
有几篇论文提出了帮助解决这种计算复杂性的transformer的变体。"Generating Long Sequences With Sparse Transformers”建议使用成对的注意力操作和精心选择的注意力模式来分解注意操作。"Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context"引入了一种循环机制,允许整合来自比自注意力操作的上下文更大的距离的信息。
The Reformer
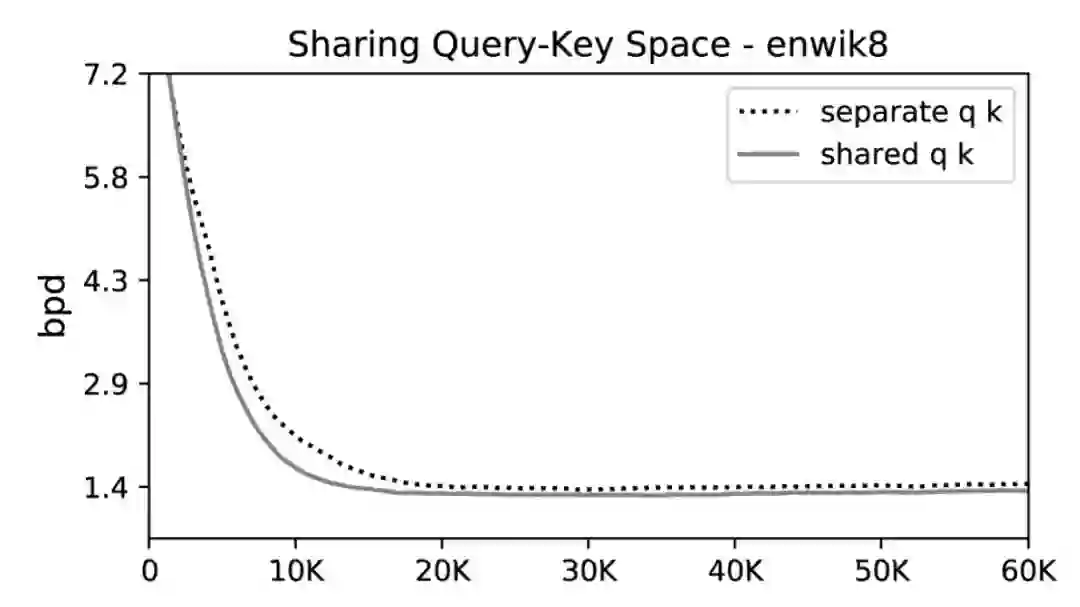
"Reformer: The Efficient Transformer"的作者采用了一种完全不同的方法来处理序列长度问题。首先,他们观察到学习不同的keys和queries的投影并不是严格必要的。他们丢弃了query投影,并将注意力权重替换为key的函数。
有点令人惊讶的是,尽管他们从注意力模块中移除了一些参数,他们的模型在enwiki8上的性能并没有下降。
现在,注意力块不再包含queries的单独投影,我们只有key和value对。然而,计算key的协同矩阵(通过将每个key与其他key进行比较)仍然是非常昂贵的。
不幸的是我们可能并没有利用好所有的这些计算。softmax的输出通常由几个关键元素控制 — 其余的往往在噪声中消失。我们在计算softmax的时候,并不一定需要那些注意力权重很小的token。
在编写传统软件时,我们总是会遇到这个问题。如果我们想找到与给定key对应的value,我们通常不会遍历所有key的列表并检查每个key是否匹配。相反,我们使用散列映射数据结构来执行O(1)的查找,而不是O(n)比较。
方便的是,向量空间的哈希映射确实存在类似的情况,它被称为“局部敏感哈希”(LSH)。正是基于这种方法,Reformer的论文的作者们希望产生一个transformer的替代方案,以避免使用点积注意力的平方复杂性。
局部敏感哈希 (LSH)
局部敏感哈希是一组将高维向量映射到一组离散值(桶/集群)的方法。它最常用来作为近似最近邻搜索的一种方法,用于近似的重复检测或视觉搜索等应用。
局部敏感哈希方法尝试将高维空间中相近的向量以高概率分配到相同的哈希。有效的哈希函数有很多种,最简单的可能是随机投影。
lsh_proj = np.random.randn(hidden_size, hash_size)
hash_value = np.sign(np.dot(x, lsh_proj.T))
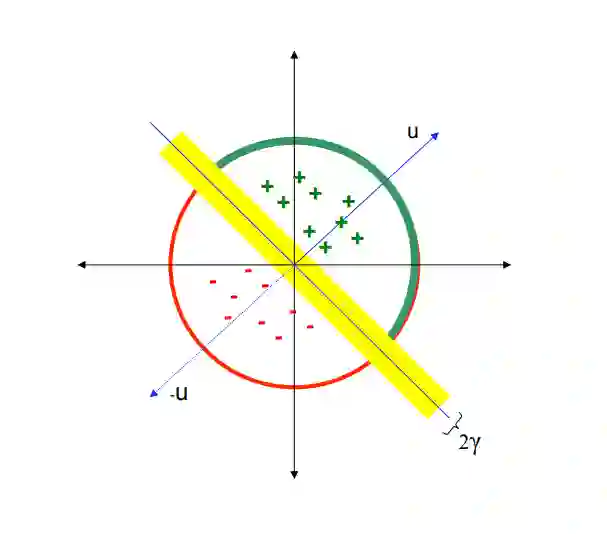
换句话说,我们选择一个随机的向量集合,观察输入向量在每个向量上的投影是正的还是负的,然后使用这个二值向量来表示给定向量的预期存储区。下图说明了LSH投影矩阵“u”中单个向量的处理过程。绿色的正号表示与向量u点积为正的点,而红色的负号表示与向量u点积为负的点。
LSH注意力
Reformer的论文选择了局部敏感哈希的angular变体。它们首先约束每个输入向量的L2范数(即将向量投影到一个单位球面上),然后应用一系列的旋转,最后找到每个旋转向量所属的切片。
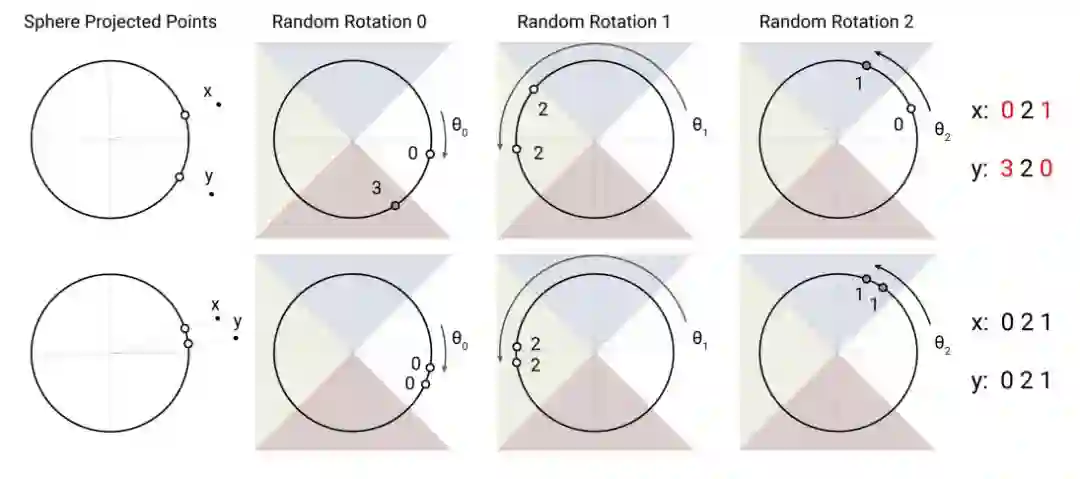
找到给定的向量选择之后属于哪个桶也可以看成是找到和输入最一致的向量 —— 下面是Reformer的代码:
# simplified to only compute a singular hash
random_rotations = np.random.randn(hidden_dim, n_buckets // 2)
rotated_vectors = np.dot(x, random_rotations)
rotated_vectors = np.hstack([rotated_vectors, -rotated_vectors])
buckets = np.argmax(rotated_vectors, axis=-1)
在为每个token计算一个桶之后,将根据它们的桶对这些token进行排序,并将标准的点积注意力应用到桶中的token的块上。

有了足够多的桶,这就大大减少了所有的给定的token需要处理的token的数量 —— 在实验中,Reformer的论文运行的模型被配置为使用128块大小的块。因此,LSH操作将昂贵的key协同矩阵乘法的上下文大小限制为更易于管理的值。
我们现在的时间复杂度为O (L*log(L)) ,而不是时间复杂度成正比O (L²), 这允许我们把注意力操作扩展到更长的序列的时候不会由于运行时间而受到影响。
因为这个分桶过程是随机的,所以Reformer有选择地多次运行这个过程,以减少两个在输入空间很近的向量被随机地放在不同的桶中的可能性。当所有的事情都做了之后,你就有了一个完全替代标准的多头注意力的方法,它可以与计算完整的注意力矩阵相媲美。
内存复杂度
不幸的是,实现更好的时间复杂度只是问题的一半。如果我们将新的LSH注意力块替换为标准的多头注意力,并尝试输入新长度的信息,我们将很快认识到系统中的下一个瓶颈 — 内存复杂性。
即使我们已经非常小心地最小化了注意力操作的计算复杂度,我们仍然必须将所有的key和value存储在内存中,更糟糕的是,在训练期间,我们需要缓存激活以计算参数更新。
Reformer论文使用了序列长度为64k的enwiki8语言建模数据集来做实验,隐藏单元的大小为1024,层数为12层,这意味着存储key和value需要2 * 64000 * 1024 * 12 = ~ 1.5B个浮点数,大约是6GB的内存。使用这种内存使用方式,我们将无法在训练期间使用大的批处理大小,从而影响我们的运行时间。
一个选择是实现gradient checkpoint来帮助限制我们的内存使用。允许我们减少内存使用,只存储从正向传递中的关键的激活,剩余的在反向传递中重新计算。因此,我们可以选择只在key和value投影之前存储隐藏状态,而不是存储key和value,然后第二次重新投影隐藏状态来计算梯度。
不幸的是,这使我们的后向传递的成本增加了一倍,因此我们能够支持更大的批处理大小所获得的好处将通过重新计算得到部分缓解。更重要的是,即使我们选择只存储输入的一小部分,存储单个层的激活需要250MB的空间,这意味着我们很难在12GB的GPU上支持超过12个样本的批处理大小。
RevNets
幸运的是,我们还有其他方法来减少内存使用。RevNet。
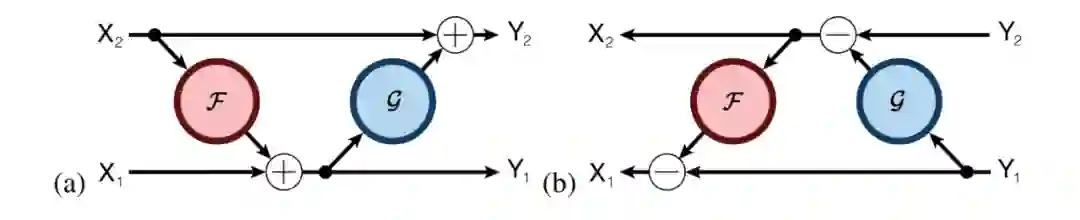
RevNets有个非常聪明的计算技巧,通过以一种特定的方式构造每一层,使内存使用与网络深度保持一致。每一层分为两个部分,X₁和X₂,前向计算如下:
def forward_pass(x1, x2, Wf, Wg):
"""
Need an extra node in the computational graph
because the gradient of the loss with respect to z1 # differs from the gradient of loss with respect to y1
x1: one half of layer input
x2: other half of layer input
Wf: weights that parameterize function f
Wg: weights that parameterize function g
"""
z1 = x1 + f(Wf, x2)
y2 = x2 + g(Wg, z1)
y1 = z1
可视化一下,看起来就是这样:
由于该层的特定结构,我们可以编写一个自定义函数参数更新,这意味着我们不需要缓存任何激活来计算我们的后向传播。类似于使用梯度检查点,我们仍然需要做一些冗余计算。然而,由于每一层的输入都可以很容易地从它的输出中构造出来,我们的内存使用不再随网络中层数的增加而增加。
# paraphrased from the RevNet paper
def backward_pass(y1, y2, d_y1, d_y2, Wf, Wg):
"""
Pseudocode for RevNet of backward pass
y1: one half of layer output
y2: second half of layer output
d_y1: derivative of y1
d_y2: derivative of y2
Wf: weights that parameterize function f
Wg: weights that parameterize function g
"""
z1 = y1
# Extra computation -- the price we pay for memory
# complexity that doesn't scale with n_layers
# Importantly this means we don't have to store x1 or x2!
x2 = y2 - g(Wg, z1)
x1 = y1 - f(Wf, x2)
# Standard backprop:
# vjp --> Vector Jacobian Product
d_Wf, partial_x2 = jax.vjp(f, Wf, x2)(d_z1)
d_Wg, partial_z1 = jax.vjp(g, Wg, z1)(d_y2)
d_z1 = d_y1 + partial_z1
d_x2 = d_y2 + partial_x2
d_x1 = d_z1
return x1, x2, d_x1, d_x2, d_Wf, d_Wg
在实践中,Reformer定义f(x)是LSH注意力块,g (x)是标准的前向块,来自transformer结构。
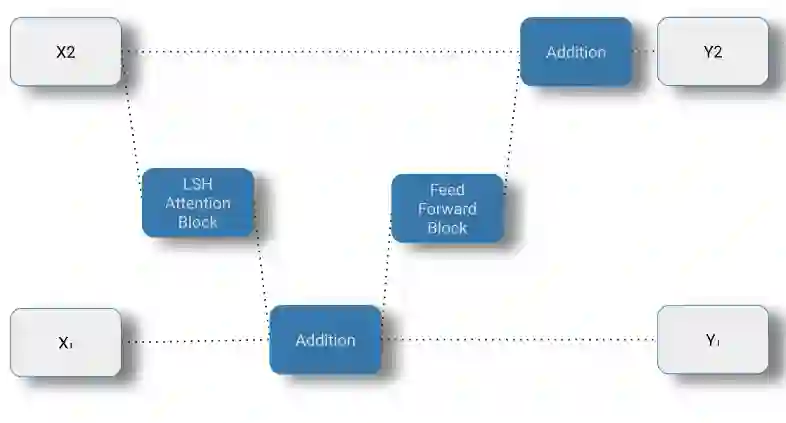
有了RevNet架构,我们只需要在内存中存储单层的激活,就可以在训练期间使用更大的批处理大小!现在我们不再受训练期间激活的内存占用的限制,我们可以利用LSH注意力块改进时间复杂度。
重要的是,语言模型的loss不会因为可逆层结构而降低。
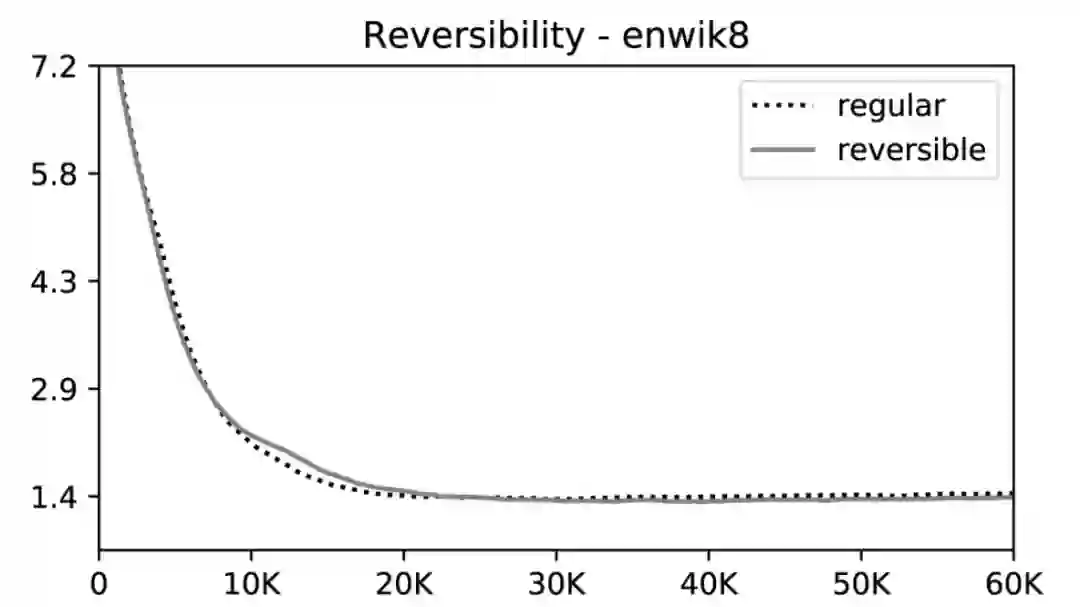
这些变化实现起来并不容易 —— 很明显Nikita Kitaev, Łukasz Kaiser和Anselm Levskaya付出巨大的努力在平衡时间和内存。
总的来说,这些变化使得序列长度的扩展成为可能。虽然结果是初步的,但在enwiki8上的实验表明,在语言建模任务上,Reformer可以与它的重量级前辈竞争。
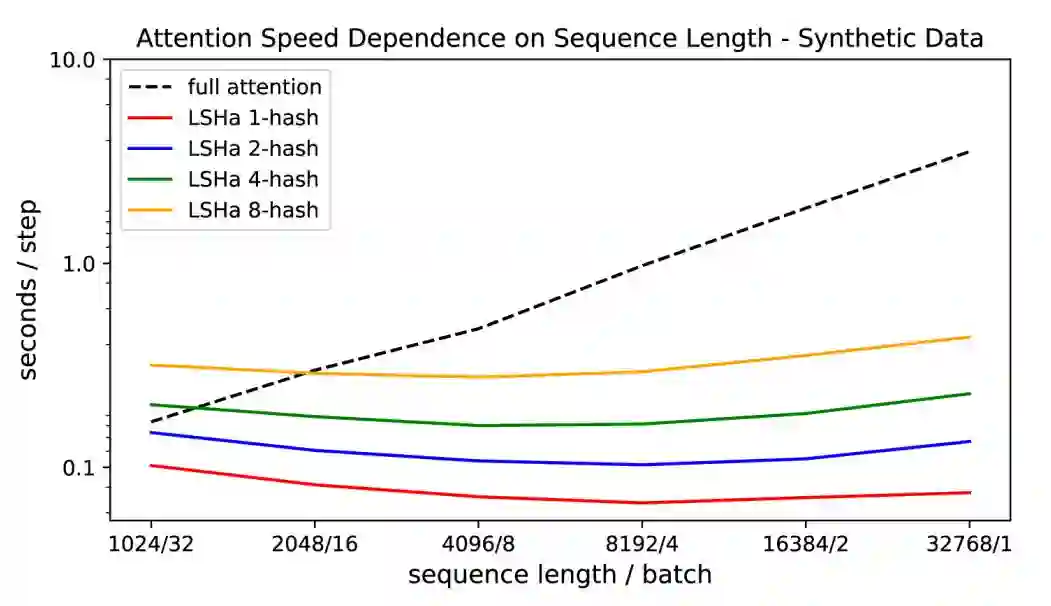
总结
位置敏感哈希的注意力和可逆层构成了Reformer的蓝图,非常高兴可以看到基于transformer的结构选择去优化和处理长序列的问题,而不是简单的扩展之前的工作。

英文原文:https://www.pragmatic.ml/reformer-deep-dive/
推荐阅读
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





