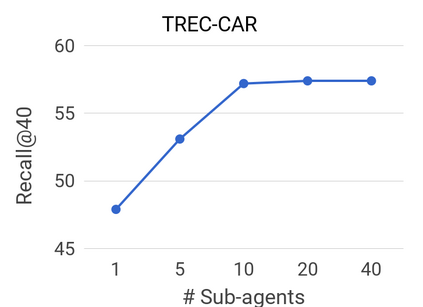
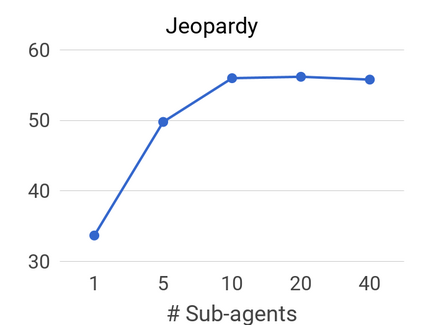
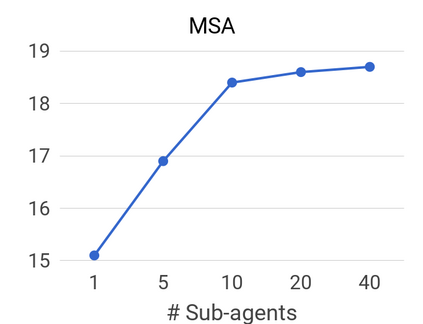
We propose a method to efficiently learn diverse strategies in reinforcement learning for query reformulation in the tasks of document retrieval and question answering. In the proposed framework an agent consists of multiple specialized sub-agents and a meta-agent that learns to aggregate the answers from sub-agents to produce a final answer. Sub-agents are trained on disjoint partitions of the training data, while the meta-agent is trained on the full training set. Our method makes learning faster, because it is highly parallelizable, and has better generalization performance than strong baselines, such as an ensemble of agents trained on the full data. We show that the improved performance is due to the increased diversity of reformulation strategies.
翻译:我们建议了一种方法,在文件检索和回答问题的任务中,有效学习各种强化学习以重订查询的战略;在提议的框架中,一种代理包括多个专门分剂和一个元试剂,学会汇总分剂的答复,以便提出最后答案;分剂接受训练,了解培训数据脱节,而分剂则接受全套培训;我们的方法使学习速度更快,因为它高度平行,比强的基线(如经过全面数据培训的代理器的组合)要好得多;我们表明,改进的性能是由于重订战略更加多样化。