谷歌升级版Transformer官方解读:更大、更强,解决长文本问题(开源)

新智元报道
新智元报道
来源:Google AI Blog
编辑:肖琴
【新智元导读】谷歌官方博客今天发文,详细解释了万用NLP模型Transformer的升级版——Transformer-XL,该模型利用两大技术,在5个数据集中都获得了强大的结果。
要正确理解一篇文章,有时需要参考出现在几千个单词后面的一个单词或一个句子。
这是一个长期依赖性(long-range dependence)的例子,这是序列数据中常见的现象,处理许多现实世界的任务都必须理解这种依赖。
虽然人类很自然地就会这样做,但是用神经网络建模长期依赖关系仍然很具挑战性。基于Gating的RNN和梯度裁剪(gradient clipping)技术提高了对长期依赖关性建模的能力,但仍不足以完全解决这个问题。
应对这个挑战的一种方法是使用Transformers,它允许数据单元之间直接连接,能够更好地捕获长期依赖关系。
Transformer 是谷歌在 17 年做机器翻译任务的 “Attention is all you need” 论文中提出的,引起了相当大的反响,业内有“每一位从事 NLP 研发的同仁都应该透彻搞明白 Transformer”的说法。
参考阅读:
Transformer一统江湖:自然语言处理三大特征抽取器比较
然而,在语言建模中,Transformers目前使用固定长度的上下文来实现,即将一个长的文本序列截断为几百个字符的固定长度片段,然后分别处理每个片段。

vanillaTransformer模型在训练时具有固定长度上下文
这造成了两个关键的限制:
算法无法建模超过固定长度的依赖关系。
被分割的片段通常不考虑句子边界,导致上下文碎片化,从而导致优化低效。即使是对于长期依赖性不显著的较短序列,这也是特别麻烦的。
为了解决这些限制,谷歌提出一个新的架构:Transformer-XL,它使自然语言的理解超出了固定长度的上下文。
Transformer-XL由两种技术组成:片段级递归机制(segment-level recurrence mechanism)和相对位置编码方案(relative positional encoding scheme)。
论文:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(https://arxiv.org/abs/1901.02860)
论文详细解读:谷歌、CMU重磅论文:Transformer升级版,评估速度提升超1800倍!
在训练期间,为前一个segment计算的representation被修复并缓存,以便在模型处理下一个新的segment时作为扩展上下文重新利用。
这个额外的连接将最大可能依赖关系长度增加了N倍,其中N表示网络的深度,因为上下文信息现在可以跨片段边界流动。
此外,这种递归机制还解决了上下文碎片问题,为新段前面的token提供了必要的上下文。

在训练期间具有segment-level recurrence的Transformer-XL
然而,天真地应用 segment-level recurrence是行不通的,因为当我们重用前面的段时,位置编码是不一致的。
例如,考虑一个具有上下文位置[0,1,2,3]的旧段。当处理一个新的段时,我们将两个段合并,得到位置[0,1,2,3,0,1,2,3],其中每个位置id的语义在整个序列中是不连贯的。
为此,我们提出了一种新的相对位置编码方案,使递归机制成为可能。
此外,与其他相对位置编码方案不同,我们的公式使用具有learnable transformations的固定嵌入,而不是earnable embeddings,因此在测试时更适用于较长的序列。
当这两种方法结合使用时,在评估时, Transformer-XL比vanilla Transformer模型具有更长的有效上下文。
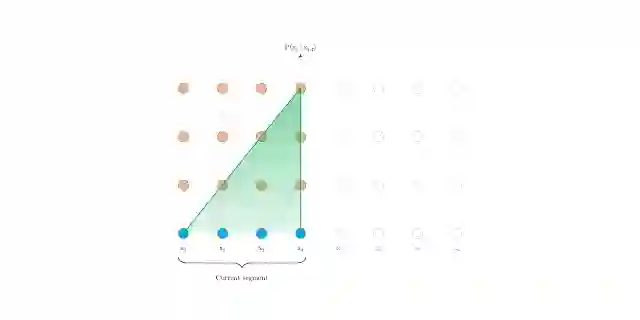
在计算时具有固定长度上下文的vanilla Transformer

在评估期间具有segment-level 递归的Transformer-XL
此外,Transformer-XL能够在不需要重新计算的情况下处理新段中的所有元素,从而显著提高了速度(将在下面讨论)。
Transformer-XL在各种主要的语言建模(LM)基准测试中获得新的最优(SoTA)结果,包括长序列和短序列上的字符级和单词级任务。实验证明, Transformer-XL 有三个优势:
Transformer-XL学习的依赖关系比RNN长约80%,比vanilla Transformers模型长450%,尽管后者在性能上比RNN好,但由于固定长度上下文的限制,对于建模长期依赖关系并不是最好的。
由于不需要重复计算,Transformer-XL在语言建模任务的评估期间比vanilla Transformer快1800+倍。
由于建模长期依赖关系的能力,Transformer-XL在长序列上具有更好的困惑度(Perplexity, 预测样本方面更准确),并且通过解决上下文碎片化问题,在短序列上也具有更好的性能。

Transformer-XL在5个数据集上的结果
Transformer-XL在5个数据集上都获得了强大的结果:在enwiki8上将bpc/perplexity的最新 state-of-the-art(SoTA)结果从1.06提高到0.99,在text8上从1.13提高到1.08,在WikiText-103上从20.5提高到18.3,在One Billion Word上从23.7提高到21.8,在Penn Treebank上从55.3提高到54.5。
研究人员展望了Transformer-XL的许多令人兴奋的潜在应用,包括但不限于改进语言模型预训练方法(例如BERT),生成逼真的、长篇的文章,以及在图像和语音领域的应用。
论文中使用的代码、预训练模型和超参数都已全部开源:
https://github.com/kimiyoung/transformer-xl
论文地址:
https://arxiv.org/abs/1901.02860
更多阅读:
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




