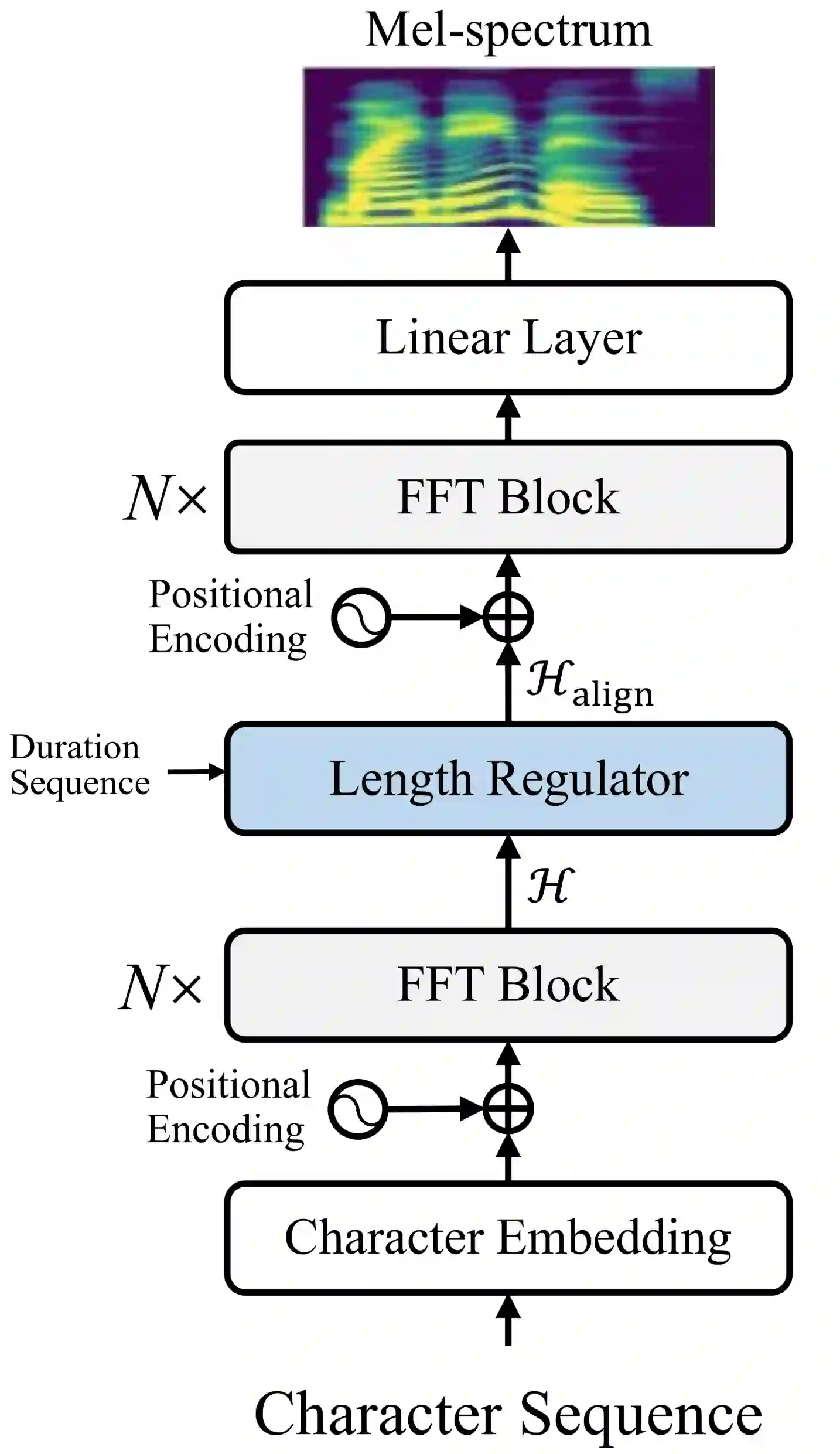
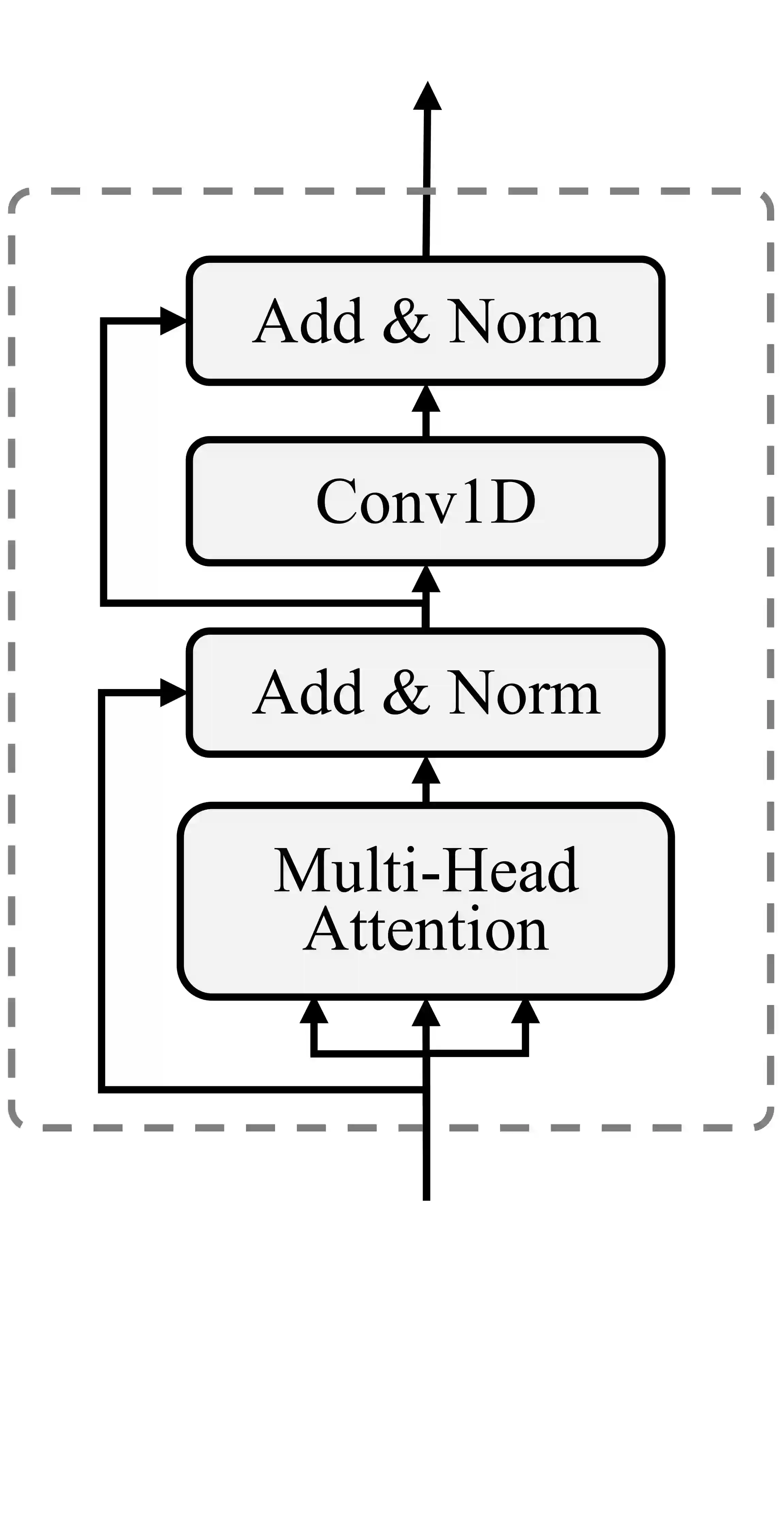
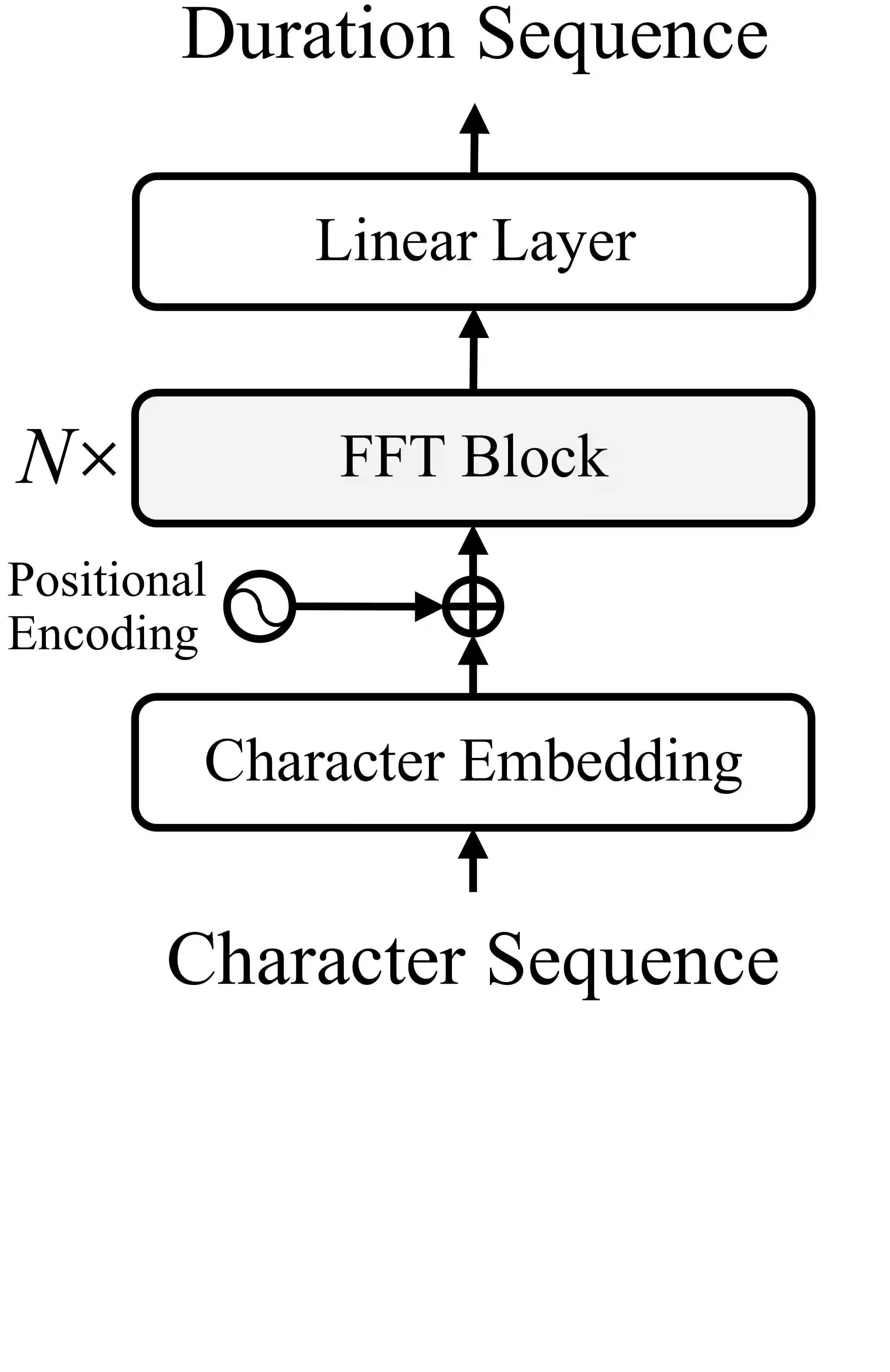
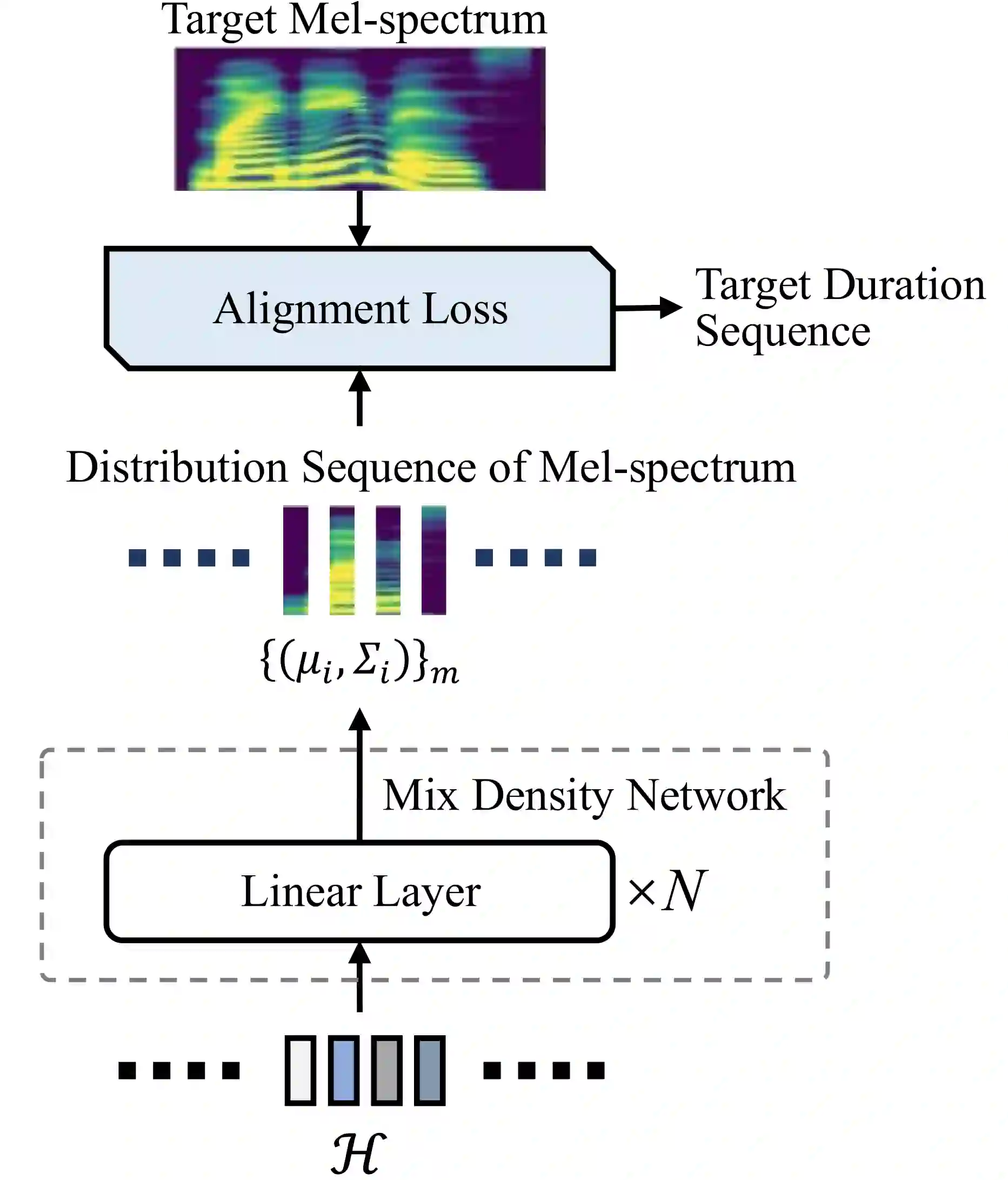
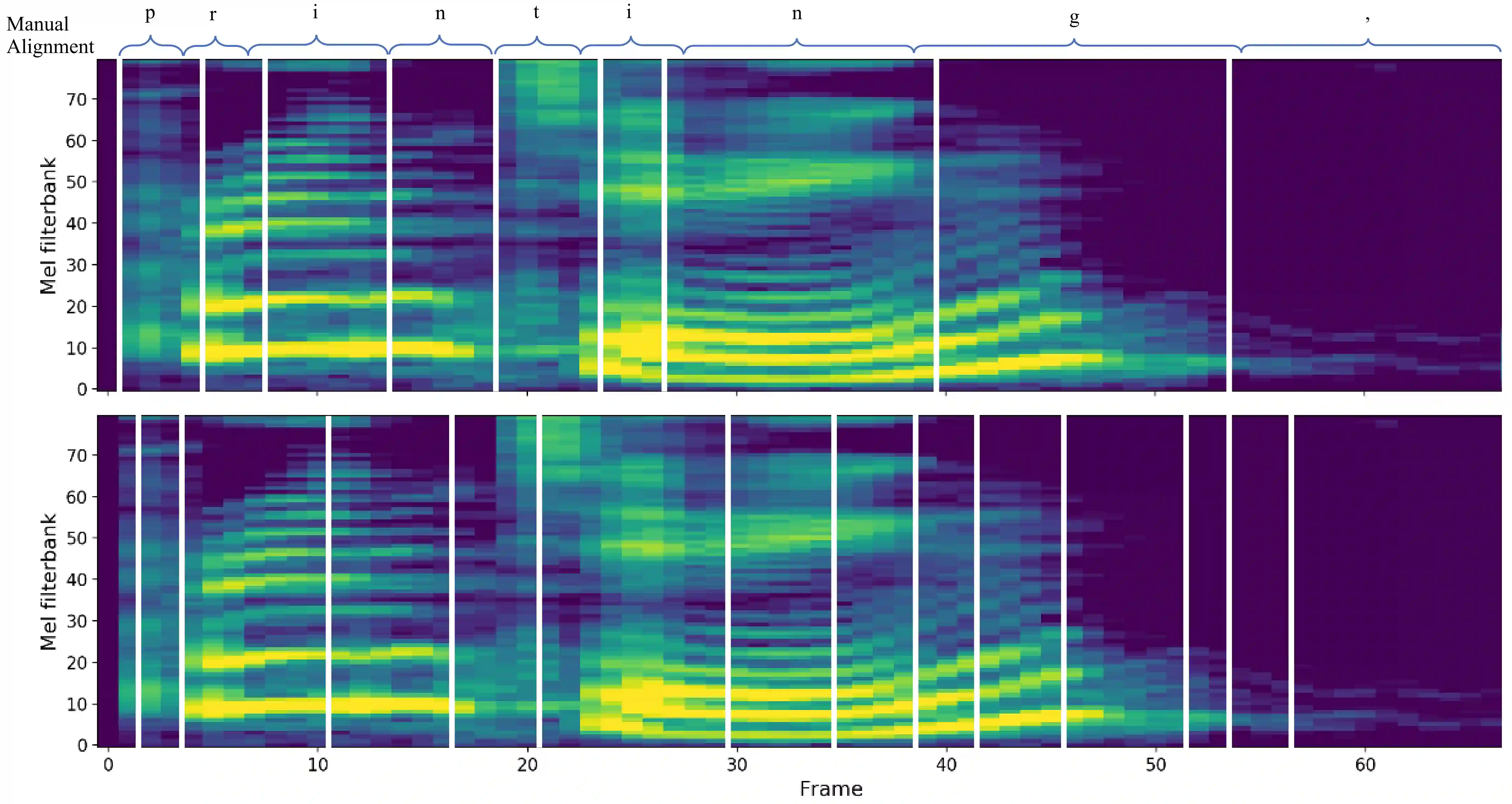
Targeting at both high efficiency and performance, we propose AlignTTS to predict the mel-spectrum in parallel. AlignTTS is based on a Feed-Forward Transformer which generates mel-spectrum from a sequence of characters, and the duration of each character is determined by a duration predictor.Instead of adopting the attention mechanism in Transformer TTS to align text to mel-spectrum, the alignment loss is presented to consider all possible alignments in training by use of dynamic programming. Experiments on the LJSpeech dataset show that our model achieves not only state-of-the-art performance which outperforms Transformer TTS by 0.03 in mean option score (MOS), but also a high efficiency which is more than 50 times faster than real-time.
翻译:以高效率和高性能为目标, 我们建议 AliignTTS 同步预测中位谱。 AliignTTS 以一个Feed- Forward 变换器为基础, 该变换器从字符序列中产生中位谱, 每个字符的持续时间由时间预测器决定 。 变换 TTS 的注意机制是将文本与中位谱相匹配, 而不是通过使用动态编程来考虑培训中的所有可能的匹配。 LJSpeech 数据集的实验显示, 我们的模型不仅取得了最新性能, 在平均选项分数上比变换 TTS 0. 3 高出0. 3, 而且效率也很高, 比实时速度快50倍以上 。