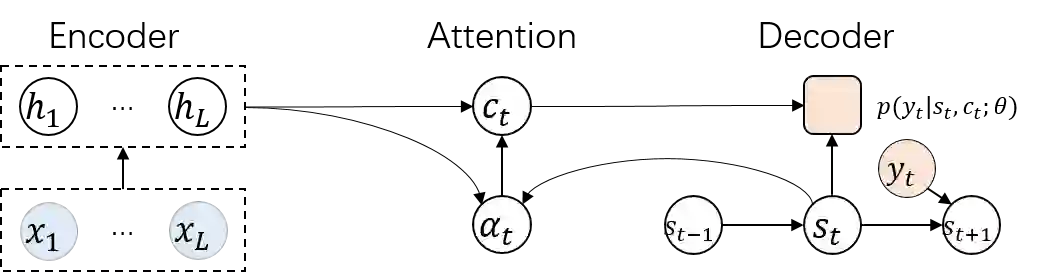
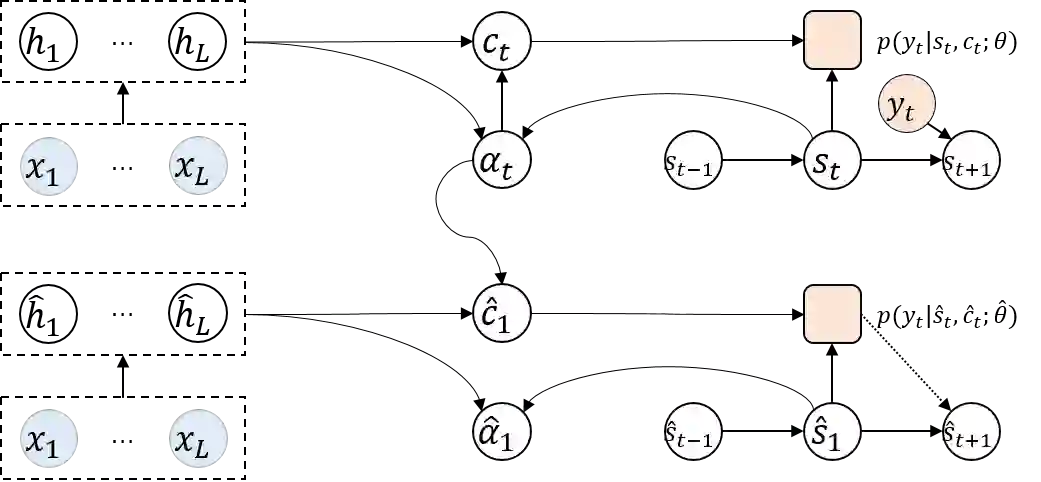
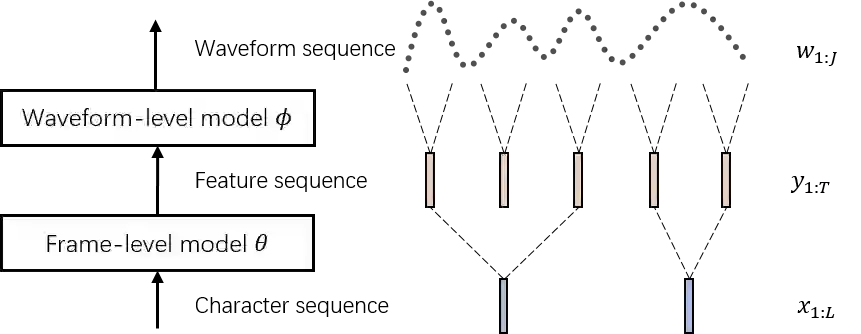
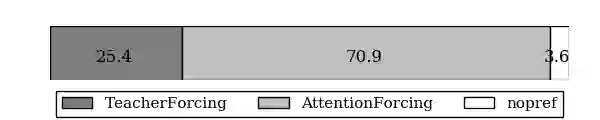
Auto-regressive sequence-to-sequence models with attention mechanism have achieved state-of-the-art performance in many tasks such as machine translation and speech synthesis. These models can be difficult to train. The standard approach, teacher forcing, guides a model with reference output history during training. The problem is that the model is unlikely to recover from its mistakes during inference, where the reference output is replaced by generated output. Several approaches deal with this problem, largely by guiding the model with generated output history. To make training stable, these approaches often require a heuristic schedule or an auxiliary classifier. This paper introduces attention forcing, which guides the model with generated output history and reference attention. This approach can train the model to recover from its mistakes, in a stable fashion, without the need for a schedule or a classifier. In addition, it allows the model to generate output sequences aligned with the references, which can be important for cascaded systems like many speech synthesis systems. Experiments on speech synthesis show that attention forcing yields significant performance gain. Experiments on machine translation show that for tasks where various re-orderings of the output are valid, guiding the model with generated output history is challenging, while guiding the model with reference attention is beneficial.
翻译:关注机制的自动递减序列到序列模型,在机器翻译和语音合成等许多任务中,这些模型可能难以培训。 标准方法, 教师强迫, 指导模型在培训期间的参考输出历史。 问题是模型不可能从推论过程中的错误中恢复过来, 参考输出被生成的输出所取代。 有几个方法处理这一问题, 主要是以生成输出历史来指导模型。 为使培训稳定, 这些方法往往需要超常的时间表或辅助分类器。 本文引入了关注力, 引导模型生成输出历史和参考关注。 这个方法可以以稳定的方式培训模型从错误中恢复, 不需要一个时间表或分类器。 此外, 它允许模型生成与引用相一致的输出序列, 这对像许多语音合成系统这样的升级系统可能很重要。 语音合成实验显示, 关注会带来显著的绩效增益。 机器翻译实验显示, 各种重新排序输出的参数是有效的, 指导模型与生成历史的模型具有挑战性能。