谷歌NIPS论文Transformer模型解读:只要Attention就够了

作者 | Sherwin Chen
译者 | Major,编辑 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
导读:在 NIPS 2017 上,谷歌的 Vaswani 等人提出了 Transformer 模型。它利用自我注意(self-attention)来计算其输入和输出的表示,而不使用序列对齐 RNN。通过这种方式,它减少了将两个任意位置的信号关联到一个常数所需的操作数量,并实现了明显更好的并行化。在本文中,我们将重点讨论 Transformer 模型的主要架构和 Attention 的中心思想。
简介
循环神经网络(RNN),特别是长短记忆(LSTM)和门控循环单元(GRU),已经作为最先进的序列建模和转导方法被牢固地建立起来。这些模型通常依赖于隐藏状态来保存历史信息。它们的好处在于允许模型根据隐藏状态下提取的有用历史信息进行预测。
另一方面,由于内存大小限制了跨样例的批处理,因此这种固有的顺序性排除了并行化。而并行化在较长的序列长度下变得至关重要。此外,在这些模型中,将来自两个任意输入或输出位置的信号关联起来所需的操作数量随着位置之间距离的增加而增多,这使得学习较远位置之间的依赖性变得更加困难。
有一点应当记住,我们在这里介绍的 Transformer 在一个样本中保存序列信息,就像 RNN 一样。这表明网络的输入是这种形式:[batch size, sequence length, embedding size]。
模型架构
遵循编码器解码器结构,对编码器和解码器都使用堆叠的自我和完全连接的层,如在下图的左半部分和右半部分所示。
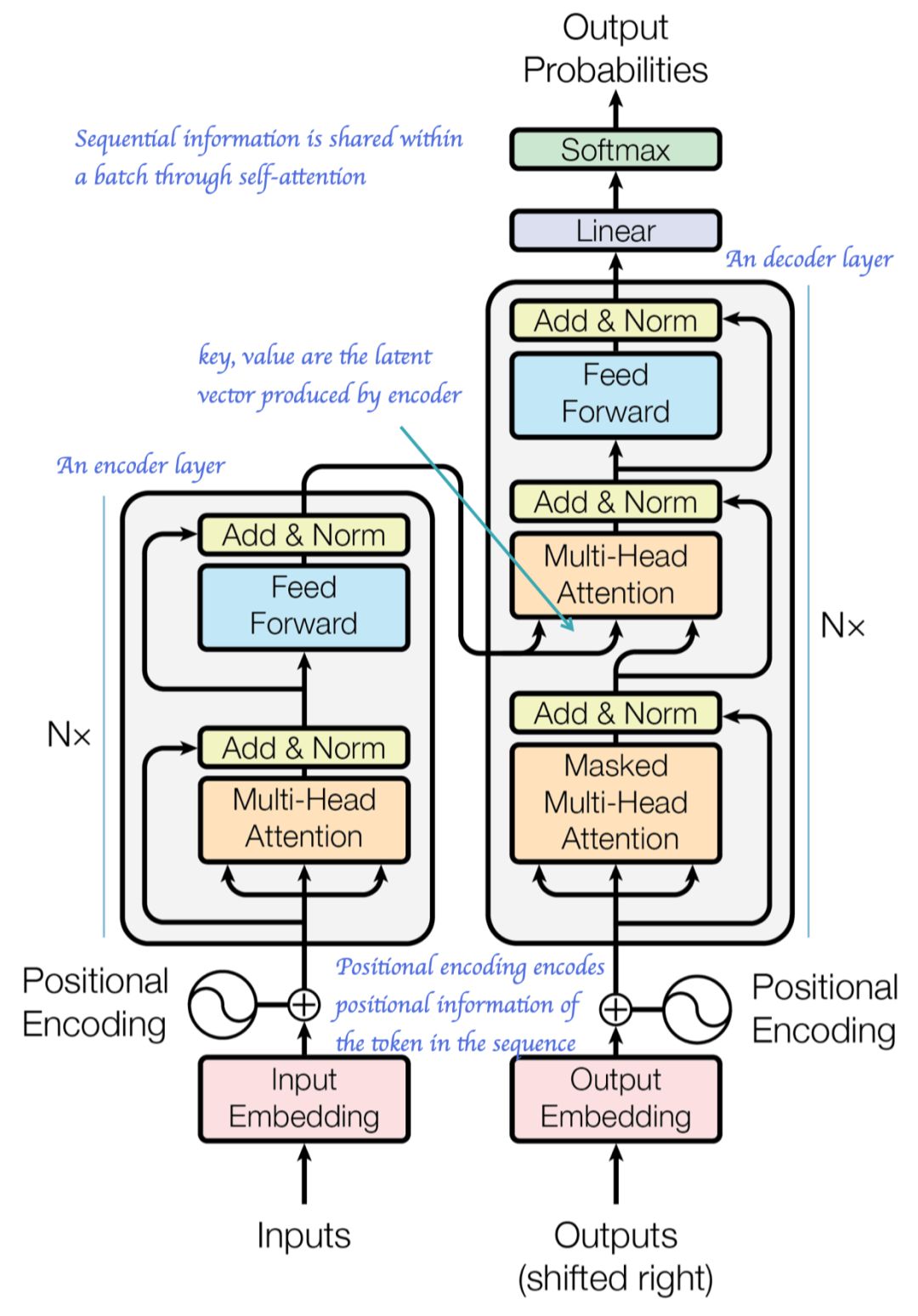
模型架构 (引自论文 Attention is All You Need)
位置编码
在本文中,我们使用不同频率的正弦和余弦函数来编码位置信息:
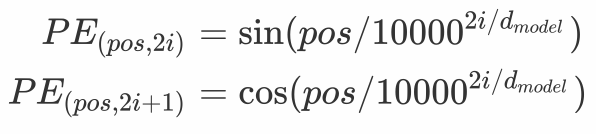
此处,pos 是位置,i 是维度。也就是说,位置编码的每个维度都对应一个正弦曲线。这些波长形成从 2π 到 10000⋅2π 的几何级数。作者之所以选择这个函数,是因为他们假设它可以让模型很容易地学习到相对位置的 Attention,因为对于任何固定的偏移 k,PE_{pos+k} 都可以表示为PE_{pos} 的线性函数。
编码器和解码器堆栈
编码器
编码器由N=6个相同的层堆栈组成。每层有两个子层。第一个是一个多头的自我Attention机制(我们很快就会讨论),第二个是一个简单的完全连接的前馈网络。两个子层的每一层都使用了Residual 连接,并且在这两个子层之间应用了层规范化。
也就是说,每个子层的输出是 x+Sublayer(LayerNorm(x)) (这与由[2]采用的子层输出,略有不同,但遵循[3]中何恺明推荐的模式,其中Sublayer(x) 是子层本身的函数。
解码器
解码器也由N=6个相同的层组成。除了编码器层中的两个子层外,解码器还插入第三个子层,该子层在编码器堆栈的输出上执行多头Attention(即,我们将编码器的输出作为键和值)。解码器中的子层遵循与编码器中相同的方式。
遮罩
编码器和解码器的自我注意层在SoftMax之前使用遮罩,以防止对序列错误位置的不必要注意。此外,与一般遮罩结合,在解码器堆栈中的自注意子层中使用额外的遮罩,以排除后续位置的Attention。这种遮罩形式如下:

在实践中,解码器中的两个遮罩可以通过逐位加操作进行混合。
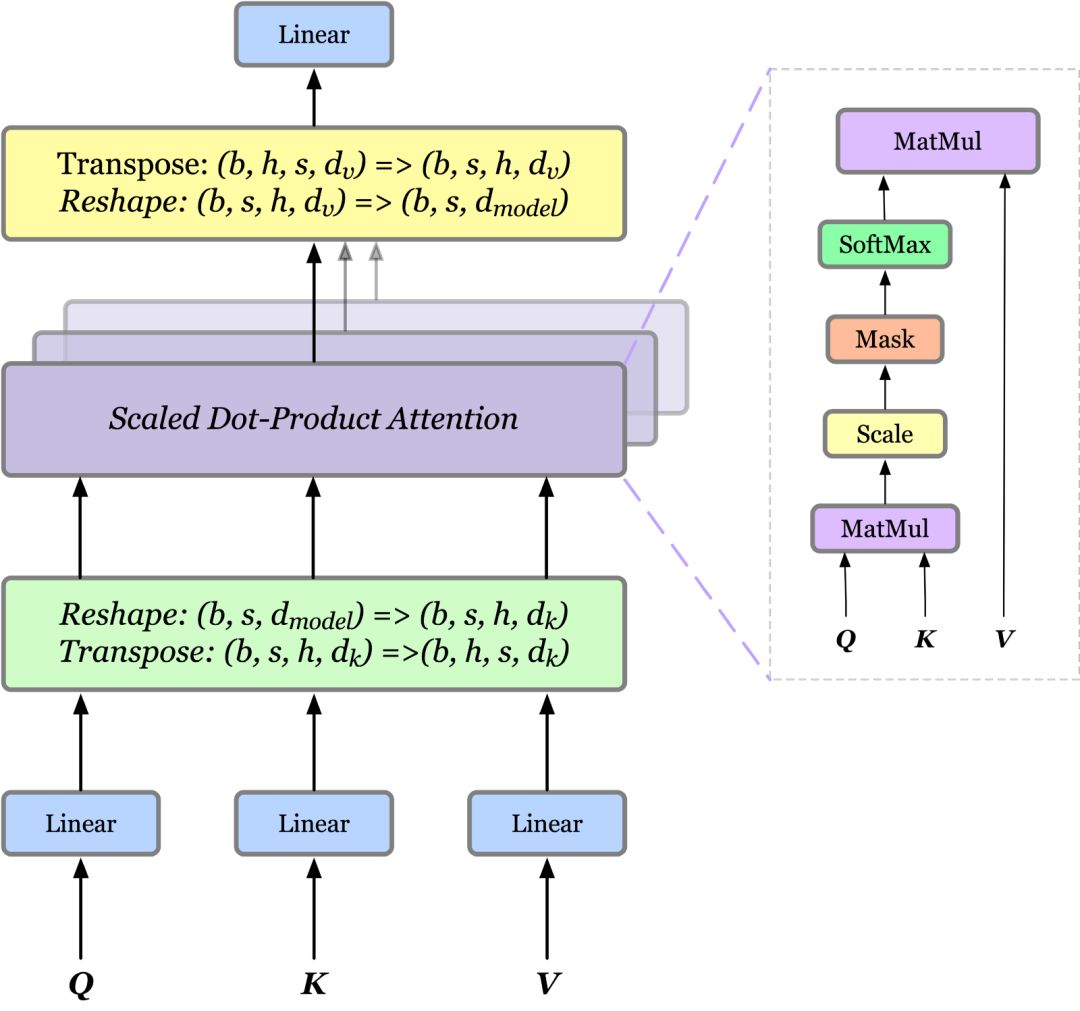
Attention
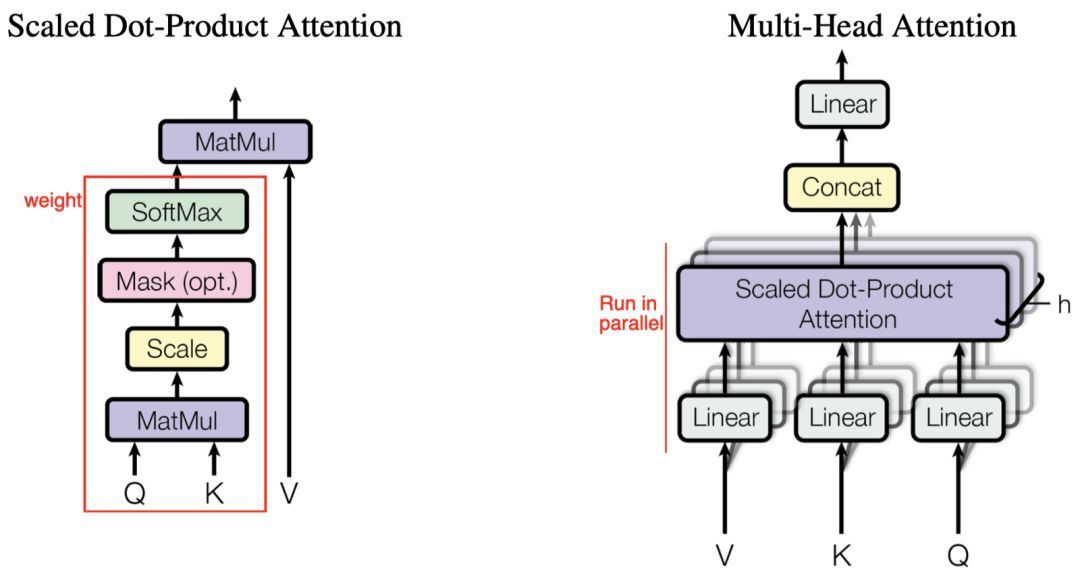
(左)缩放点积Attention。(右)多头Attention由几个并行运行的Attention层组成。
缩放点积Attention
Attention 函数可以描述为从查询和一组键值对到输出的映射,其中查询、键、值和输出都是向量。输出是以值的加权和计算的,其中分配给每个值的权重是通过查询的兼容函数和相应的键计算的。
更严格地说,输出按下列方式计算:
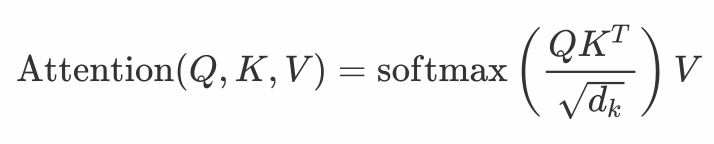
其中Q、K、V 分别是查询、键和值;是键的维度;兼容性函数(SoftMax部分)计算一行中分配给每个值的权重。按1/

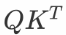
一些启示:在数学上,Attention仅仅集中在Q和K 余弦相似的空间上,Q和K余弦相似的空间中,因为它们具有相同的量级((QK^T)_{i,j}=|Q_i||K_j|cosθ)。一个极端的思想练习是Q 和 K都是热编码的情况。
多头 Attention

单注意头对注意加权位置进行平均,降低了有效分辨率。为了解决这一问题,提出了多头Attention,关注来自不同位置的不同表示子空间的信息。
其中映射是如下的参数矩阵:
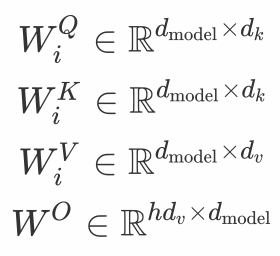
对于每个头部,我们首先应用一个完全连接的层来减小维度,然后将结果传递给一个 Attention函数。最后,将所有头连接起来,再次映射,得到最终值。由于所有的头部都是并行运行的,并且每个头部的维度都是预先减小的,因此总的计算成本与单头Attention的全维度计算成本相似。
在实践中,如果我们有h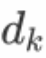
Tensorflow代码
现在,我们提供了用于多头Attention的TensorFlow代码。为了简单起见,我们进一步假设Q、K、V均为X。

代码源于:
https://github.com/deepmind/sonnet/blob/56c917e156d84db2bcc1f027ccbeae3cb1192cf/sonnet/python/modules/relational_memory.py l120。为消除不需要的依赖性进行了删减。
结语
作者希望你已经对 Transformer 有了基本的认识。要查看包含代码的完整示例,你可以进一步参考(http://nlp.seas.harvard.edu/2018/04/03/attention.html?source=post_page---------------------------#attention)
原文链接:
https://medium.com/towards-artificial-intelligence/attention-is-all-you-need-transformer-4c34aa78308f
(*本文为AI科技大本营编译文章,转载请联系微信 1092722531)
推荐阅读
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
AI ProCon圆满落幕,五大技术专场精彩瞬间不容错过
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
我的一年AI算法工程师成长记
开源sk-dist,超参数调优仅需3.4秒,sk-learn训练速度提升100倍
如何打造高质量的机器学习数据集?
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句

登录查看更多
相关内容

Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
专知会员服务
37+阅读 · 2020年1月12日
相关主题





相关VIP内容
专知会员服务
37+阅读 · 2020年1月12日
相关资讯
相关论文