谷歌提出 RNN 版 Transformer,或为长文本建模的当前最优解

文 | 小轶
今天给大家介绍一篇谷歌的最新工作,解决的是 Transformer 的长文本处理问题。在原生 Transformer 中,attention 的复杂度是输入序列长度的平方级别,因此限制了它处理长文本的能力。简单来说,本文提出的解决方案就是把 Transformer当做 RNN 中的循环单元来用。
和传统 RNN 的区别只在于:传统 RNN encoder 每个循环单元负责编码一个 token,而本文中每个循环单元负责编码一段长度为 的文本片段,且每个循环单元都由构造相同的 Transformer Block 来实现。如此一来,每个片段在编码时,都能用类似 RNN 的方式,同时考虑之前文本中的信息了。
想法很简单,但具体实现起来还是有一些难点。接下来,我们展开介绍一下本文所提出的 Block-Recurrent Transformer。
论文标题:
BLOCK-RECURRENT TRANSFORMERS
论文链接:
https://arxiv.org/pdf/2203.07852.pdf
滑动注意力机制
先来看一下每个 block 的 attention 范围。本文采用的是一种滑动窗口注意力机制,一种专门针对长文档场景的技术。由于文本过长,让每个 token 都 attend 到整个文本中的所有 token 难以实现。在滑动窗口注意力机制中:每个 token 只需要 attend 到它的前 个 token。在本文中,滑动窗口长度 与每个循环单元所需处理的文本长度 相等,即 。
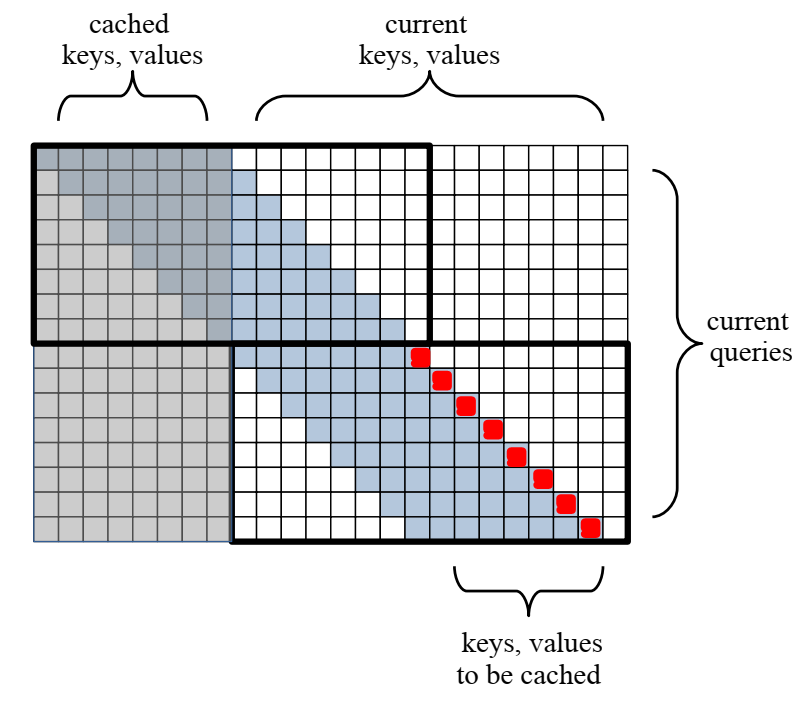
上图示例中,假设窗口长度为 8;相应地,输入文本也被分为长度为 8 的片段,交由 Transformer blocks 分别处理。图中浅蓝色区域表示了 attention 范围。
图中两个黑框分别对应了两个 Transformer block 。8个红色标记点,代表右下角那个 block 所需要处理的 8 个 token。可以看到,每个 block 的 attention 矩阵大小为 。因此,对于长度为 N 的输入来说,整个模型的 attention 复杂度为 O(N)。
循环单元
接下来,我们就往每个 Transformer block 内部看看,究竟是如何实现循环的。
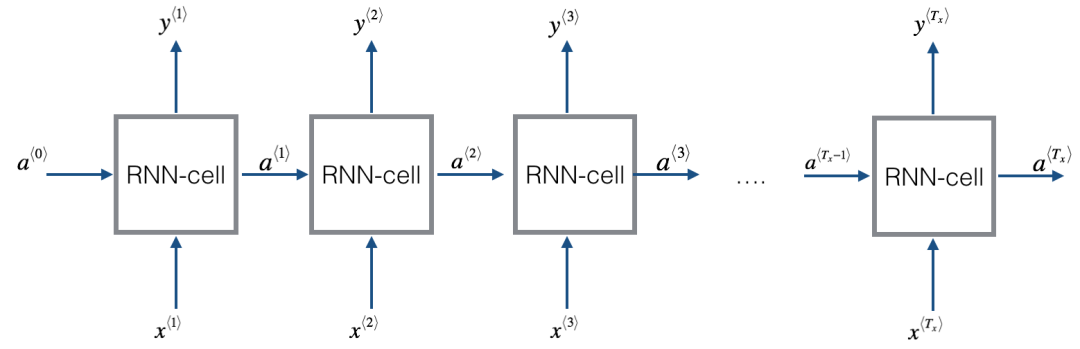
类似传统 RNN,每个循环单元:
-
输入是input embeddings 和 current state -
输出是 output embeddings 和 next state
所以,我们这里所需要理解的两个核心问题也就是:在 Block-Recurrent Transformer 中,这两个输出分别是如何得到的?
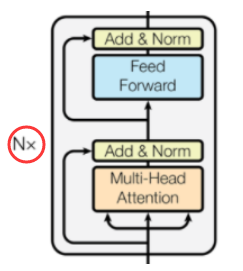
垂直方向:如何得到 output embeddings?
下图展示了得到 output embeddings 的过程。
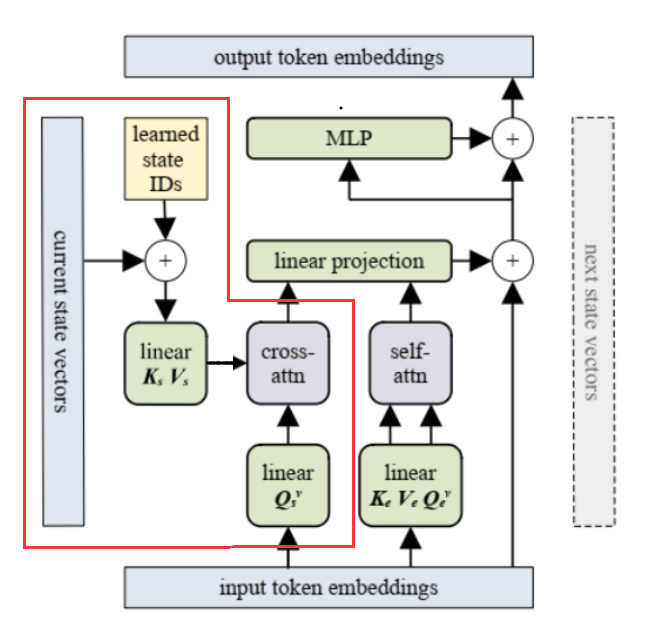
和传统的 Transformer layer 非常相像,差别只集中在红框标识出来的部分。在这一部分中,为了融合上一个循环单元给的 current state 信息,他们将 input embeddings 和 current state vectors 做了一个 cross attention。另一方面,input embeddings 自身也会过一个 self-attention 层。这两部分拼接后,通过线性层融合在了一起。
水平方向:如何得到 next state?
下图展示了得到 next state 的过程。
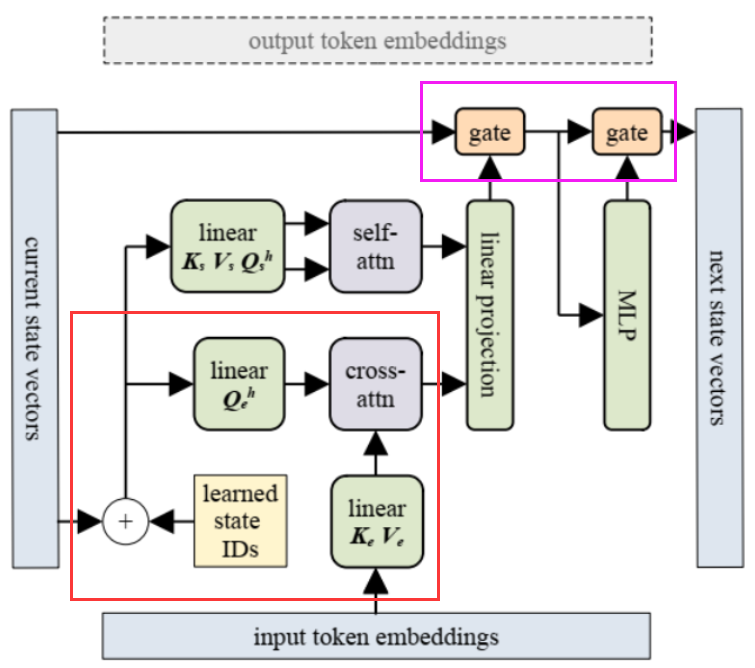
与传统 Transformer 不同的地方,用红色和粉色框标识了。红色部分,同样是用 cross attention 将 input embeddings 和 current state vectors 融合。粉色部分则是用两个 gate 替代了原本 Transformer 中的残差层。这两个 gate 的作用与 LSTM 中的遗忘门类似,控制了对前一个 state 信息的保留程度。
垂直方向如何多层叠加?
最后还有一个问题。我们都知道,传统 Transformer Encoder 通常是由多个 Transformer Layer 叠加起来的。也就是下图中那个 的意义。那么,在 Block-Recurrent Transformer 中,如何实现垂直方向上的多层叠加呢?
文中讨论了两种方式,Single Recurrent Layer 和 Feedback。
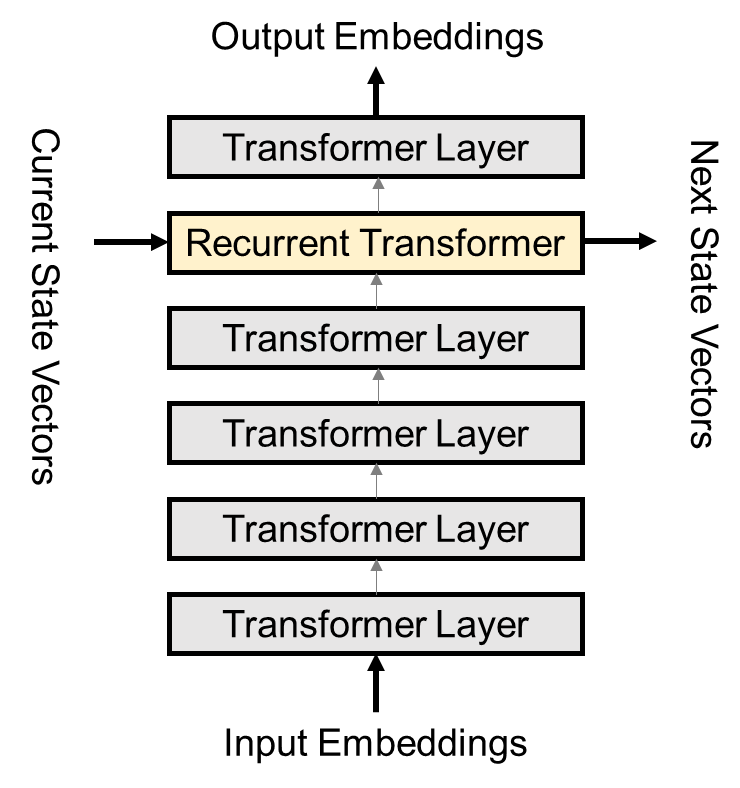
Single Recurrent Layer (SRL) 的实现比较简单。我简单花了张示意图,大致如上图所示。垂直方向上叠加的多个层:大多数都是普通的 Transformer Layer;只有其中的一层,在水平方向上接收了 current state,做了循环操作。这种方式的运算复杂度也比较低,只相当于在普通的 Transformer 基础上多加了一层 layer 的运算量。也就是说,如果垂直叠加了 12 层,相当于普通 Transformer 叠加 13 层的运算量。
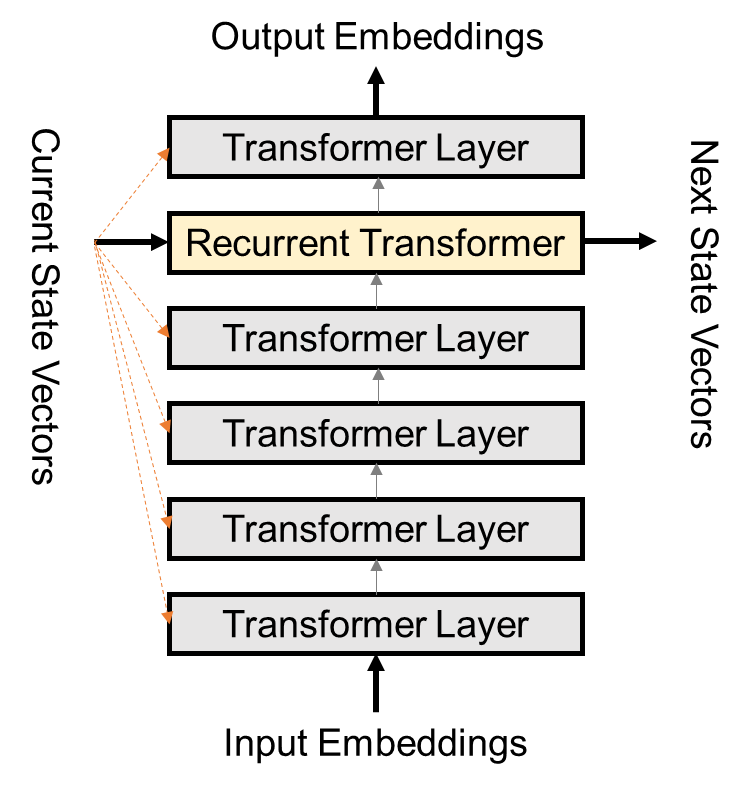
Feedback 在 SRL 的基础上,current state 还会广播给其他 Transformer Layer。这些层会用 cross attention 的方式,将 current state 的信息融合。实验中,Feedback 比 SRL 性能有小幅提升,不过它的模型参数更多,训练时长也要陡增 35~40%。
实验
实验在三个长文本数据集上进行,分别是 PG19,arxiv 和 Github。评测任务是自回归语言建模,指标为 perplexity。结果如下图所示。
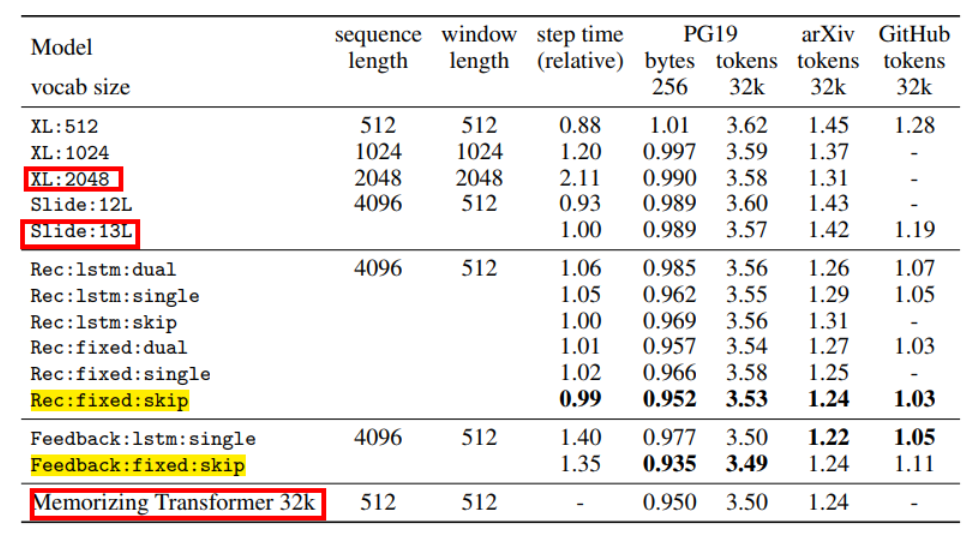
其中,黄色高亮的是本文所提出方法的两个变种,获得了 SOTA 的效果。
红色框出的是三个比较重要的 baseline。其中,上面两个 baseline 是此前经典的长文档处理模型 Transformer-XL 的两个变种。可以看到本文方法的性能要比他们好不少。
最后一行的 Memorizing Transformer 同样是谷歌的工作,刚刚被 ICLR'2022 录用。其基本思想是:编码长文本时,模型一边往下读,一边把之前见过的所有 token 保存在一个数据库中;在读当前片段时,会用 kNN 的方式找到数据库中相似的内容,然后和当前内容同时交互编码。
可以看到,这个模型的效果其实和本文方法相差不大,但复杂度要高很多,运算时延也要长[1]。虽然...但是,本文并没有把 Memorizing Transformer 的 step time 明确写在表格中。个人感觉有些不妥。
小结
本文的想法其实很简单:把 Transformer 作为 RNN 的循环单元,解决长文本问题。我相信想到过类似 idea 的应该早有人在。我确实也看到了类似的 previous works,不过它们的模型复杂度和性能效果都逊于本文。
就本文来说,只是拥有一个 idea 肯定是不够的,还要解决很多问题,包括:
-
相邻的 block 之间如何以适配 Transformer 的方式传递信息 -
模型设计的时候还要同时考虑到将运算复杂度的降到最低,能并行运算的绝不搞串行 -
还有最后工程实现上的一些问题。比如说,模型训练的时候是否会像传统 RNN 一样遇到梯度消失的问题?如果有,该如何解决?我在本篇推送中,没有涵盖这方面的讨论。原文确实提了一些方法来提高模型训练的稳定性。
从一个宏观的 idea 到真正落实,还是有很长距离的。所以还是不能轻易地说一篇论文的 idea “too simple”。
往期回顾
-
《Longformer:超越RoBERTa,为长文档而生的预训练模型》 -
《告别自注意力,谷歌为Transformer打造新内核Synthesizer》 -
《Google综述:细数Transformer模型的17大高效变种》
萌屋作者:小轶
是小轶,不是小秩!更不要叫小铁!高冷的形象是需要大家共同维护的!作为成熟的大人,正在勤俭节约、兢兢业业,为成为一名合格的(但是仍然发量充足的)PhD而努力着。日常沉迷对话系统。说不定,正在和你对话的,并不是不是真正的小轶哦(!?)
“高冷?那是站在冰箱顶端的意思啦。” ——白鹡鸰
作品推荐:
 萌屋作者:小轶
萌屋作者:小轶
后台回复关键词【入群】
加入卖萌屋NLP、CV与搜推广求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Memorizing Transformers https://arxiv.org/abs/2203.08913
 后台回复关键词【
后台回复关键词【





