【论文笔记】基于LSTM的问答对排序
【导读】本篇论文使用时间门同步学习文本对之间的语义特征,在 Quasi Recurrent Neural Network (QRNN) 模型的基础上进行创新,提出新的模型Cross Temporal Recurrent Network (CTRN)。论文通过对问题和答案对的遗忘门和输出门的信息中获益,从而学习QA的联合序列对。
QRNN
通过结合LSTM和CNN的特征构成的QRNN,其结合了RNN和CNN的特征:
像CNN一样,基于时间步维度和minibatch维度上进行并行计算
像RNN一样,允许输出依赖之前的元素,即过去时间依赖性
与LSTM和CNN一样,QRNN可以分解为2个组件:卷积和池化
与LSTM相比,并行化提高了QRNN的速度,因此作者论文中提出的模型基于QRNN,因为门是预先学习的,它能够容易的在两个QRNN之间对齐时间门。而在LSTM中对齐时间门可能非常麻烦且低效。更重要的一点是QRNN的时间门具有关于整个序列的全局信息而LSTM不具有全局信息。
卷积
给一组长L的序列,每个向量的维度为m,QRNN的卷积内部结构遵循如下公式:

X表示维度为m,长度为L的序列,都是R^{k×n×m}的张量,*表示是以k为宽度的序列维度上的窗口滑动。
池化
Bradbury et al. 2016在论文中池化部分提到了3种方案:f-pooling(动态平均池化)、fo-pooling(基于动态平均池化)、ifo-pooling,本篇论文作者提到了fo-pooling(基于动态平均池化),具有一个独立的输入门和遗忘门:
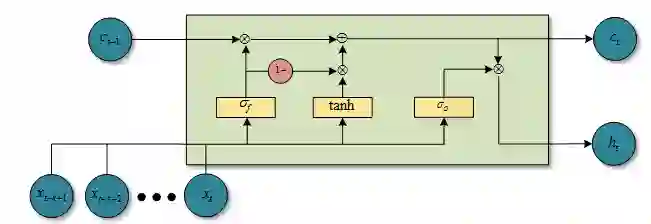
用公式表示:
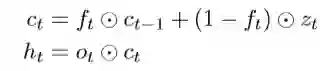
这里,c_t表示为神经元状态,h_t表示为隐藏状态,f_t,o_t分别表示为t时刻的遗忘门和输出门。
CTRN
作者在论文中提出的模型为 Cross Temporal Recurrent Network (CTRN)
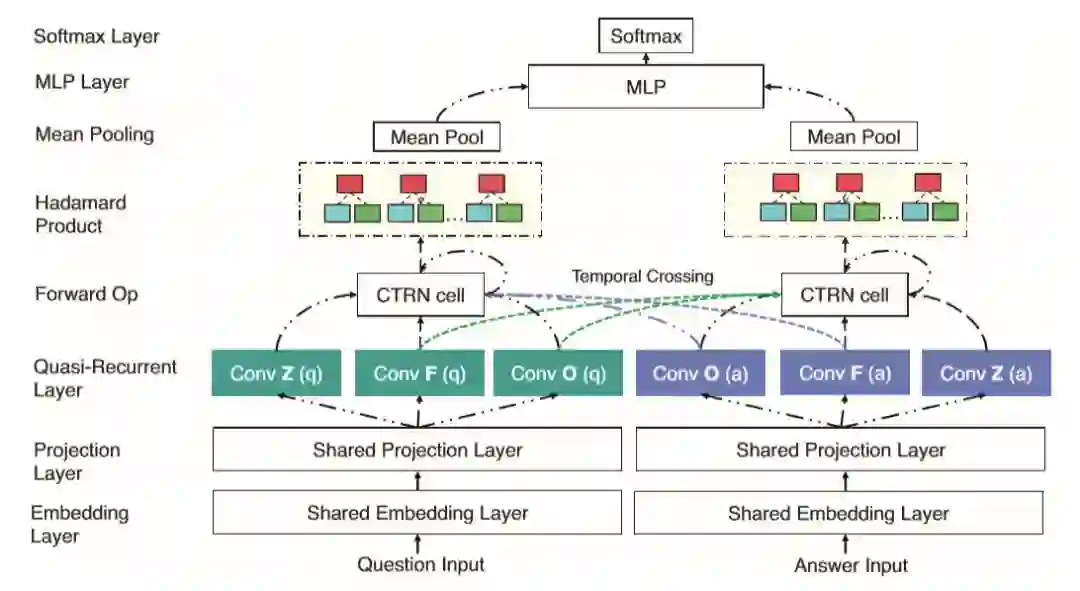
Embedding+Projection Layer
模型输入包括两部分(问题q和答案a对),通过embedding层输出一个n维向量,然后通过projection layer输出m维向量
Quasi-Recurrent Layer (即QRNN网络)
输入L个向量,并经过3个1D卷积运算获得矩阵Zs,Fs,Os,s={q,a}
Light weight Temporal Crossing(LTC)
LTC是作者模型的创新点,在QRNN的基础上进行延伸,在这一层中,有两个CTRN cell,分别是CTRN-Q,CTRN-A,分别代表问题和答案两个部分。从图中可以看出这层中CTRN cell的出入包括5部分,拿CTRN-Q来说,一部分来自自身卷积的输出zq,fq,oq,另一部分来自answer的卷积输出oa,f_a,具体情况如下所示:

这个CTRN-Q包括两步,首先在Zq上应用Fq,Oq,其次将Fa,Oa应用到Zq上,具体计算如下:
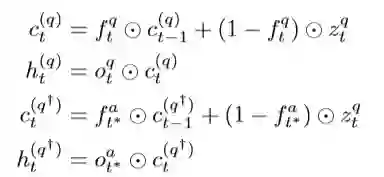
t∗ 在这里表示问题和答案的对齐时间,因为他们的序列长度可能不同,计算公式为:
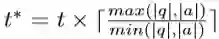
又因为CTRN-Q和CTRN-A是对称的,所以我们可以写出CTRN-A的计算公式:

然后,我们对得到的问题和答案用一个公式表达,对于每个t的隐藏状态进行点乘计算,即:
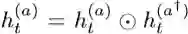
Temporal Mean Pooling Layer
CTRN的输出为一组隐藏状态[h1s,h2s…hLs],在这一层对 CTRN-Q和CTRN-A进行平均pooling计算
Softmax Layer and Optimization
最后,将上层的 输出进行二分类的softmax计算:

损失函数:

θ 包含所有的参数,优化器为Adam Optimizer。
实验
作者在3个数据集上进行对比:YahooQA、QatarLiving、 TrecQA

TrecQA 数据集有两种训练集:TRAIN、TRAIN-ALL。TRAIN-ALL中包含更多的QA对,同时也包含更多的不利因素。
评估指标
不同数据集采用不同的评估指标。对于YahooQA,采用 P@1 (Precision@1) 和 MRR (Mean Reciprocal Rank);对于QatarLiving,采用n P@1 和 MAP (Mean Average Precision);对于TrecQA,采用MAP和MRR。
实验细节
对于CTRN模型,将输出维度(filter的数量)调整为128的倍数,并且使用单层的CTRN和QRNN,MLP的层数从[1,3]中调整,学习率在{10−3,10−4,10−5},批量大小调整为{64,128,256,512},dropout设置为0.5,L2正则化设置为4×10−6。
实验结果
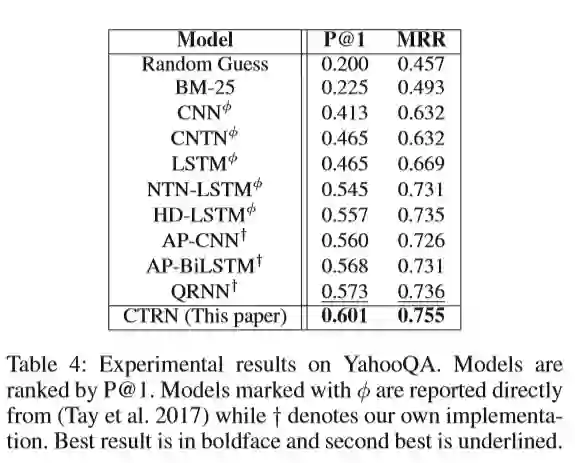
从上述表格我们可以看到:在这个数据集上,LTC机制比soft-attention更有效;这个评价指标更能看出CTRN与QRNN之间的差异。

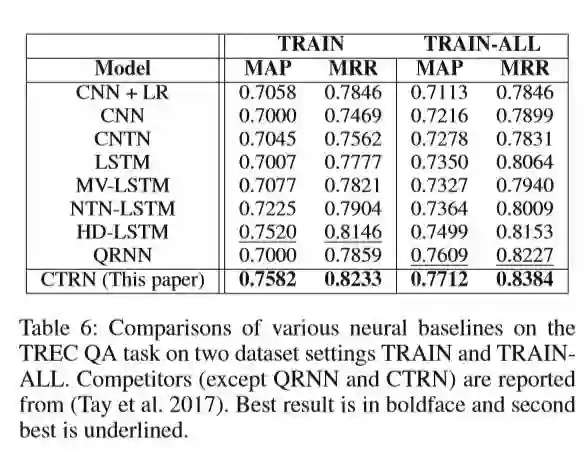
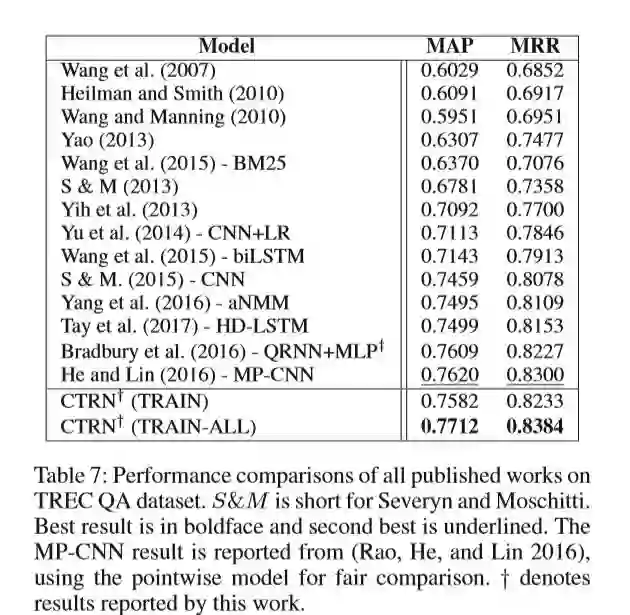
作者将CTRN模型与其他模型在数据集TRECQA进行比较,可以看出CTRN的效果更胜一筹。
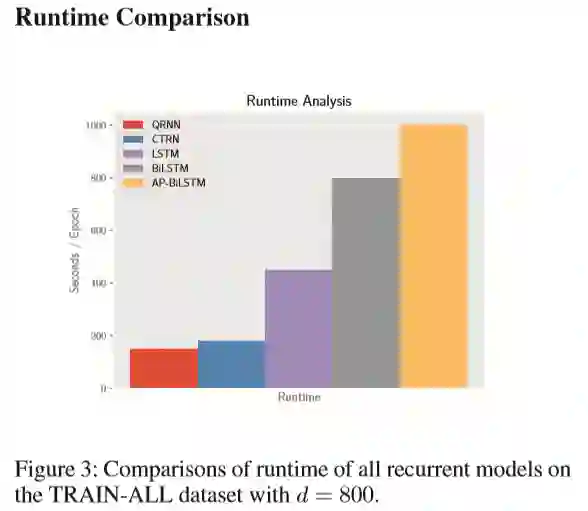
从时间上边看,完成一个epoch的训练时长相差甚远,QRNN与CTRN相差无几,其他三个模型的时长都相对来说较长。

-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



