【论文导读】2022年论文导读第六期


论文导读
2022年论文导读第六期(总第四十六期)
目 录
|
1 |
Imitating Arbitrary Talking Style for Realistic Audio-Driven Talking Face Synthesis |
|
2 |
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification |
|
3 |
Towards a Unified Middle Modality Learning for Visible-Infrared Person Re-Identification |
|
4 |
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition |
|
5 |
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation |
|
6 |
Former-DFER: Dynamic Facial Expression Recognition Transformer |
01
Imitating Arbitrary Talking Style for Realistic Audio-Driven Talking Face Synthesis
基于单张图像的多风格说话人合成
作者:吴昊哲1,贾珈1,王浩宇1,窦义顺2,段超2,邓清珊2
单位:1清华大学,2华为
邮箱:
wuhz19@mails.tsinghua.edu.cn,
jjia@tsinghua.edu.cn,
wang-hy18@mails.tsinghua.edu.cn,
douyishun@hisilicon.com,
duanchao15@hisilicon.com,
dengqingshan@hisilicon.com
论文:
https://arxiv.org/abs/2111.00203
代码:
https://github.com/wuhaozhe/style_avatar
demo视频:
https://hcsi.cs.tsinghua.edu.cn/demo/MM21-HAOZHEWU.mp4
说话人合成任务旨在根据输入的音频以及目标人物的脸像,合成形象的面部动作与逼真的视频。该任务主要存在两个困难: (1) 如何建模多风格的、形象的音频到面部动作映射。(2) 如何根据目标人物的图像渲染出逼真的视频。为了解决这两个问题,我们 (1) 定义了连续的风格空间编码,根据该编码合成音频同步的说话动作。(2) 实现了one-shot deferred neural render,给定单张人脸,不用任何fine-tune,即可控制该人脸的3D表情、姿态,并且渲染为真实2D图像。下面我们分别介绍这两部分的实现。
首先,来谈一谈多风格唇形合成。对于风格化的唇形合成,之前的方法往往是one-shot的,例如VOCA。然而,在现实中,显然一个人也有可能有多种不同的talking风格。如果在wild的数据中,我们对于每个人强制的用one-shot,就有可能导致最终合成的style被平滑掉。为了解决这一问题,我们用了图像风格迁移中类似gram matrix的思路,在一段面部动作序列(3DMM参数序列)中,寻找与风格强相关的连续性统计量,将这一连续性统计量fuse到音频到面部动作参数的预测模型中,达到风格控制的效果。通过这样的方式,我们甚至可以模仿任意的说话风格。那么接下来的问题就是,如何找到这样一个统计量?如何在audio2motion的模型中做fuse?
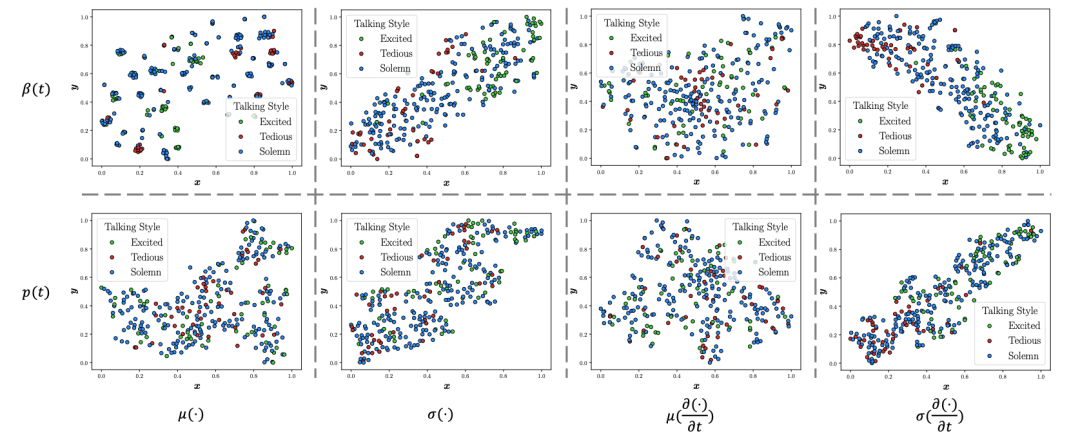
图1 针对说话风格的statistical study
为了找到这样一个统计量,我们做了大量的statistical study,发现风格与表情序列的方差、表情序列差分的方差,姿态序列差分的方差密切相关。因此我们将控制风格的连续性统计量定义如下:
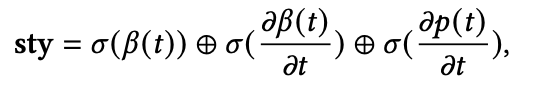
其中beta是表情,p是姿态,sigma是标准差。有了这样的sty code,接下来的问题就是怎么将style融入到audio2motion的模型中。我们尝试了很多方案,比如adain,但是方案都没有最简单的在resnet1D的中间层将隐层音频特征与sty融合效果好,因此最后采用了最简单的方案: 直接把隐层音频特征的每一帧和sty拼接,如下图所示。
通过这样的方式我们得到了风格化的唇形动作序列,接下来就是one-shot渲染的问题。
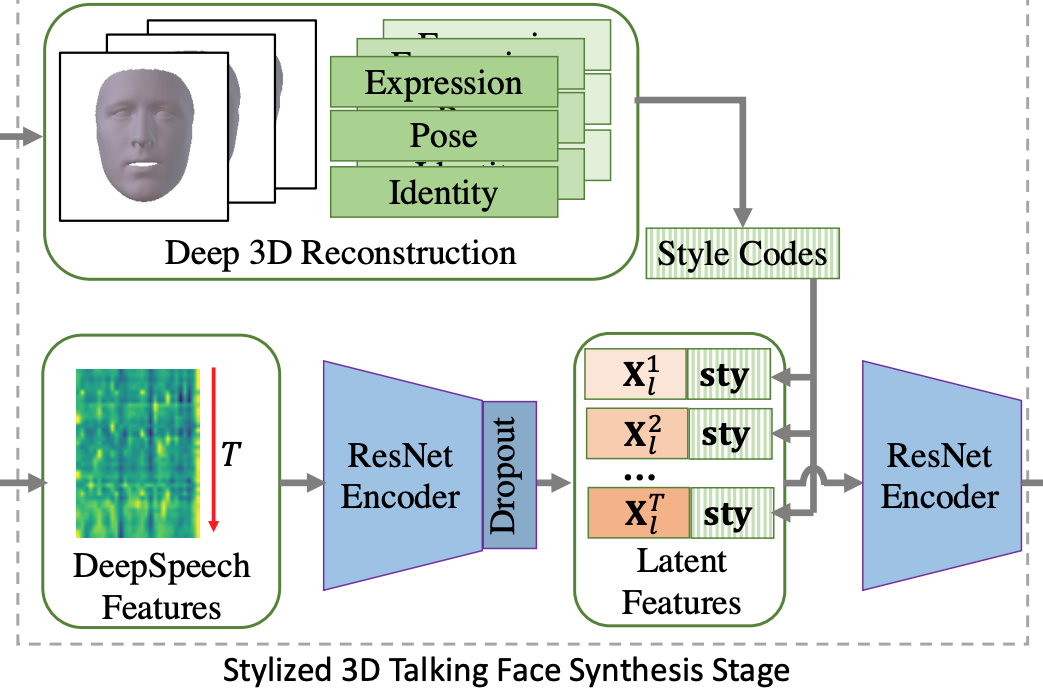
我们参考了neural voice puppetry中deferred neural render的方案,用神经纹理+UV纹理采样+图像迁移的方式做渲染。但是,deferred neural render需要2-3分钟的视频训练神经纹理,我们则训练了一个texture encoder从单张图片合成纹理。在具体实现中,我们从RGB图像以及单目的重建结果中unwrap出RGB纹理,随后用UNet从RGB纹理中合成神经纹理,再将神经纹理输入到后续神经渲染的流程中。通过这样的方式,我们在单张图像上实现了姿态、表情的控制。具体如下图:

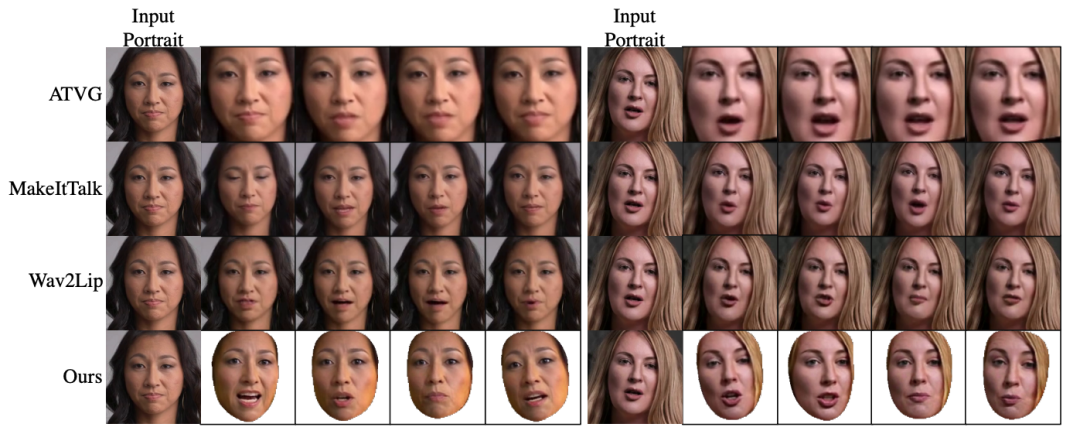
这一部分的训练是在LRW数据集上端到端训练的,对unseen的identity有很好的泛化能力,我们在开源的code中给出了一个one-shot合成的结果。这里也给了一些比较结果:

02
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
作者:吴一鸣,吴欣填,田健,李玺
单位:浙江大学
邮箱:
yimingwu0@gmail.com,
hsintien@zju.edu.cn,
xilizju@zju.edu.cn,
tianjian29@zju.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475296
代码:
https://github.com/weleen/MGH.pytorch
引言
由于标注大规模数据集的成本仍然较高,近年针对无监督行人重识别任务涌现了大量的工作。现有的工作主要关注于视觉信息,在智能监控网络中常见的时间、摄像头号等元信息通常被忽略,然而这些信息在实际应用中能够为重识别提供辅助。同时,为了更准确地建模摄像头网络中的复杂关系,本文使用超图结构表示摄像头所采集的样本与样本间关联关系。综上,本文提出了全新的基于元信息的超图模型(MGH)来解决 “如何建模复杂关联”这一问题。

图1 基于超图的聚类—微调框架
方法概述
如图1所示的算法框架,主要由超图构建、超图标签传播和基于Memory的Coarse-to-fine监督。本文在聚类—微调的训练框架下对特征提取网络进行反复训练直至收敛,首先,在超图构建阶段,通过预训练网络提取样本视觉特征,结合元信息与视觉特征构建超图;随后,在基于超图的标签传播阶段,进行两阶段的标签预测,使用聚类算法进行粗聚类,而后使用基于超图的标签传播算法进行标签修正;最后,在计算损失过程中,使用基于Memory的损失函数进行训练,分别从样本、摄像头两个层级构建损失。
实验结果
本方法在三个标准数据集上与现有方法进行了对比,对比结果如表1和表2所示,可以发现本方法在三个数据集上都达到的领先水平。此外,对本方法中使用的超图聚类方法以及损失函数进行了消融实验,实验结果如表3和图2所示,可以发现在选择超图聚类算法时,使用KNN(K=5)的情况下已经可以取得较好的结果,在结合DBSCAN能够有一定提升。
表1 与其他算法在Market1501和DukeMTMC上对比结果
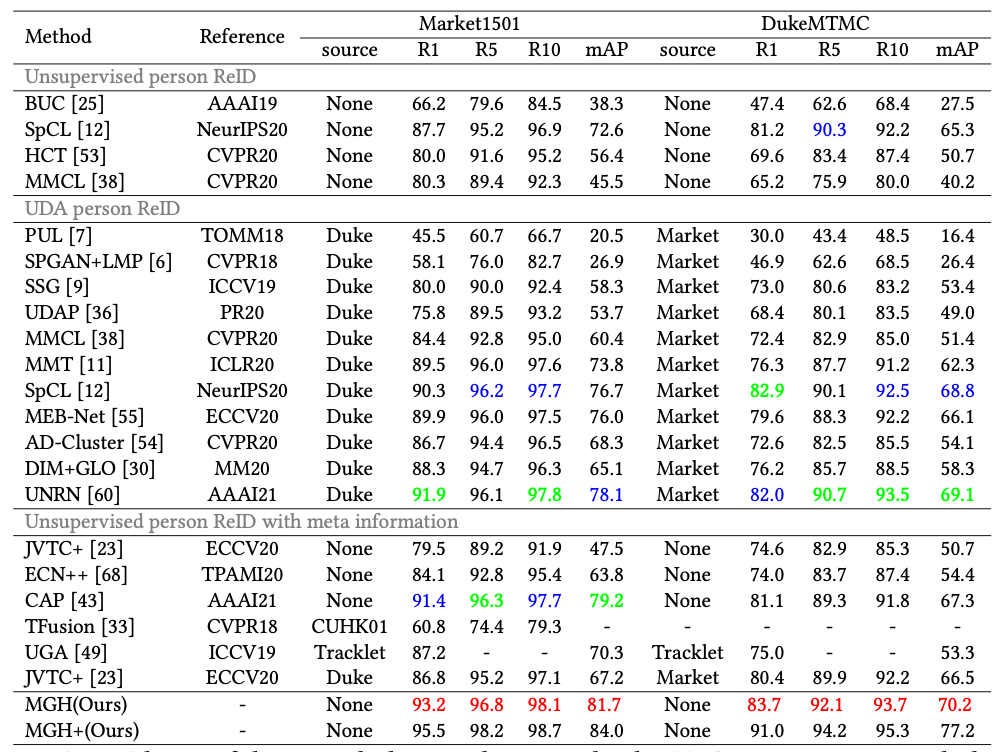
表2 与其他算法在MSMT17上对比结果

表3 针对损失函数以及超图模块的消融实验
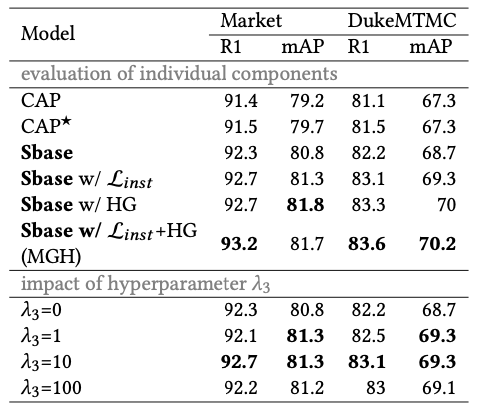
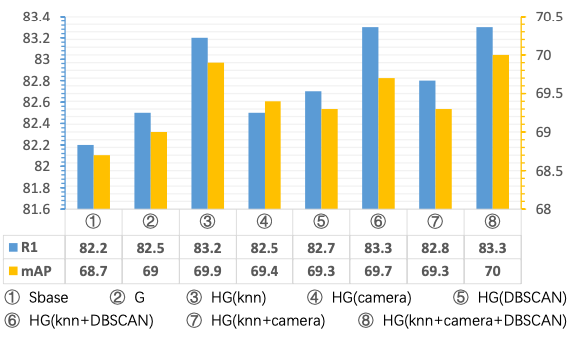
图2 针对超图构建方式的消融实验
03
Towards a Unified Middle Modality Learning for Visible-Infrared Person Re-Identification
作者:张玉康,严严,卢杨,王菡子*
单位:厦门大学,福建省智慧城市感知与计算重点实验室
邮箱:
zhangyk@stuxmu.edu.cn
yanyan@xmu.edu.cn
luyang@xmu.edu.cn
hanzi.wang@xmu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475250
1、引言
给定一个需要检索的行人和来自于不同模态的行人数据库,可见光-红外跨模态行人重识别的目的是从数据库中检索出该行人在不同模态下和不同摄像机下的该行人图像。跨模态行人重识别技术由于在安防领域中的重要作用,已成为学术界和行业界最受欢迎的研究方向之一。通常来讲,现有的跨模态行人重识别方法设计网络模型将可见光和红外图像映射到一个公共的嵌入空间中,这样,跨模态检索任务就可以归结为在我们所熟悉的欧式空间中的行人重识别检索任务。然而,由于可见光和红外图像之间的模态差异是高度非线性的,因此为跨模态行人重识别构建一个公共的特征空间是一个非常有挑战性的问题。本文从以下两个方面着手解决这个问题:(a):本文引入了一个非线性网络来缓解可见光和红外模态图像的非线性关系;(b):本文将可见光和红外图像转换成一个统一的中间模态图像空间,以减少它们之间的模态差异。

图1 跨模态行人重识别数据集部分图像示例
2、方法概述
图2为本文所提MMN算法的框架图。MMN的输入是成对的可见光-近红外图像。可见光-近红外图像对被输入所提出的MMG模块,以生成中间模态图像。生成中间模态图像与原始可见光-近红外图像对一起被输入到双流ResNet50网络中,以提取模态不变特征。其中,双流ResNet50网络中的第一个卷积块不同,用于学习特定模态图像的低水平特征表示,而中间和深层卷积块共享,用以学习模态共享的中间和高维特征表示。此外,为了拉近所得到的的中间模态图像之间的距离,本文提出了一个模态差异损失进一步的对齐了中间模态图像的数据分布。
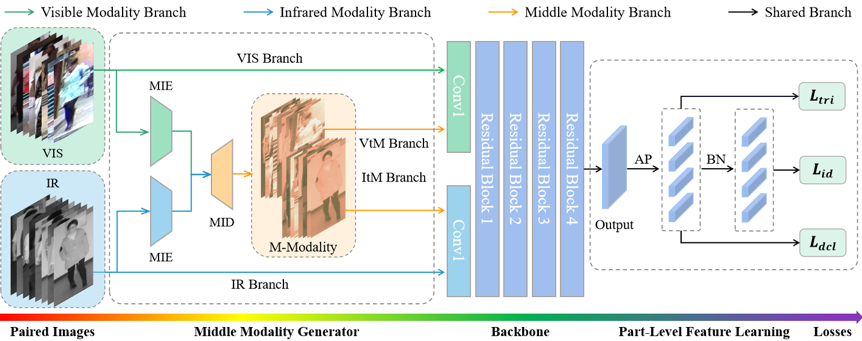
图2 统一中间模态算法框架
3、实验结果
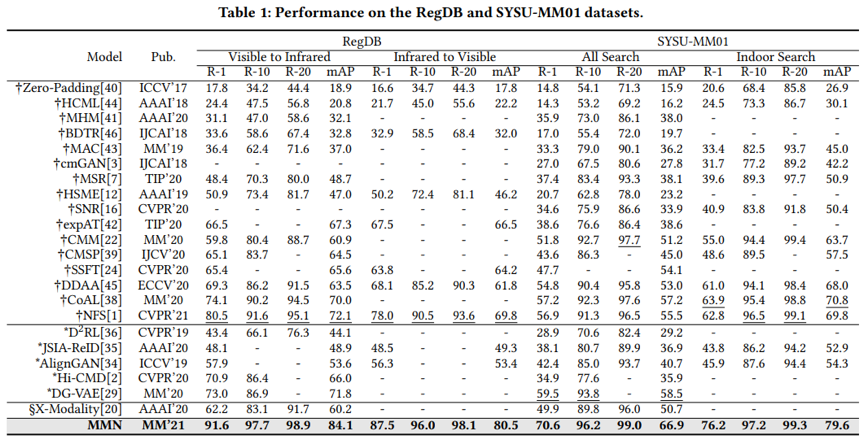
如表1所示,与现有方法相比,本文所提出的MMN在RegDB与SYSU-MM01两个数据集上,均达到了最高的结果,表明了本文所提方法的有效性。
表1 算法性能比较
4、可视化结果
为了验证本文所提方法的有效性,这里可视化了所生成的中间模态图像,如图3所示,图中四行从上到下分别表示原始可见光图像、原始近红外图像、由可见光图像所生成的中间模态图像与由近红外图像所生成的中间模态图像。可以看到,所生成的中间模态图像的模态差异得到了有效的降低,因此也表明了本文所提方法的有效性。

图3 所得中间模态图像示意图
04
Self-Supervised Regional and Temporal Auxiliary Tasks for Facial Action Unit Recognition
基于自监督区域和时序辅助任务的面部运动单元识别
作者:严经纬、王晶晶、李强、王春茂、浦世亮
单位:海康威视研究院
邮箱:
yanjingwei@hikvision.com
wangjingjing9@hikvision.com
liqiang23@hikvision.com
wangchunmao@hikvision.com
pushiliang.hri@hikvison.com
论文:
https://dl.acm.org/doi/10.1145/3474085.3475674
目前面部运动单元(Action Unit, AU)识别方向面临的一个主要问题是有可靠标签的数据量十分有限,如常用的基准数据集BP4D和DISFA均仅有不到50人的数据,这样稀少的有标签数据成为提升模型性能的一大掣肘。由于AU标定的门槛和难度较高,大规模AU数据库在短期内难以构建,因此近年来越来越多的研究人员将目光转向了利用海量无标签数据进行弱监督学习来提高识别性能。本文从区域性、关联性以及面部肌肉时序运动这些AU独有的特点出发,设计两种新的自监督辅助任务,并与AU识别任务结合起来,形成一个同时基于有标签和无标签数据的端到端的联合训练框架。
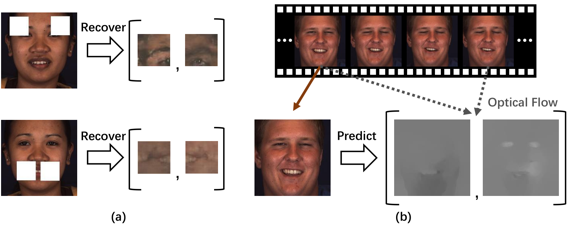
图1 两个AU相关的自监督辅助任务:(a) 关键区域补全,(b) 基于单帧的光流估计
我们基于AU区域学习和关联学习构造骨干网络,从CNN输出的全局特征图上切割得到每个AU对应位置上的特征,并使用卷积-池化层得到每个AU的区域特征后,再基于Transformer自适应学习AU关联并将其嵌入区域特征中,最后基于区域和全局特征的预测融合得到识别结果。考虑到AU的局部区域特性和AU之间的关联性,为了从无标签数据中更好地学习局部特征表达和建模AU相关性,本文设计了关键区域补全任务。如图1(a) 所示,首先在原始人脸图像上随机选择一个AU,将其对应的关键区域去掉并用白色填充,然后基于其他AU的区域特征和AU之间的相关性,通过关联建模得到被去掉区域的特征表达,最后利用GAN进行纹理生成。这里我们使用Transformer,利用自注意力机制自适应地从数据中学习AU关联并得到用于恢复的区域特征表达。通过在大量无标签数据上进行该任务,网络能够习得更具表达能力的区域特征以及更完备的AU关联信息。另外,考虑到AU本质上是面部肌肉的动态变化过程,与静态纹理相比,肌肉在时序上的变化信息更有助于判断AU是否出现,为了将这一动态信息嵌入全局特征表达中,本文设计了基于单帧图像的光流估计任务。如图1(b) 所示,首先计算两帧图像之间的TV-L1光流作为监督信息,然后从单帧图像的全局特征出发,通过光流预测网络进行推导,从而让网络从单帧图像中学习判断肌肉的运动趋势。

图2 RTATL的网络结构
将上述两个自监督任务与AU识别任务结合在一起,形成了区域和时序辅助任务学习(Regional and Temporal Auxiliary Task Learning, RTATL)框架。RTATL的网络结构如图2所示,其中蓝色和红色虚线内分别为区域补全和光流估计两个任务的对应网络模块,中间为骨干部分。可见在训练过程中基于有标签和无标签数据,所有模块同时被训练;而在测试时虚线内的网络模块被移除,仅使用骨干网络识别AU,因而并没有增加网络在部署时的耗时。
本文提出的方法可有效缓解AU识别模型在训练时对标签的依赖,从图3中的表可见,在加入了本文提出的区域补全和光流估计后,相比原始骨干网络和其他CV中常用的自监督任务,能更显著地提升识别性能。在BP4D和DISFA两个基准数据集上,RTATL均取得了SOTA性能,如图4所示。
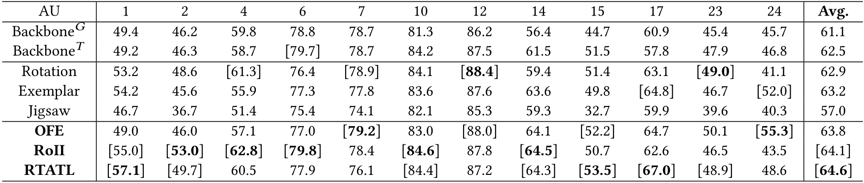
图3 加入自监督任务后在BP4D上的性能提升
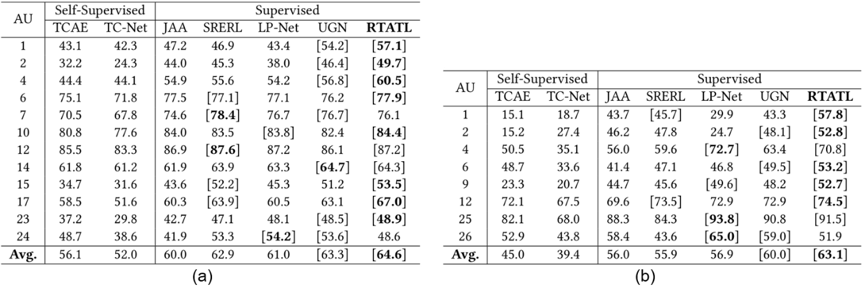
图4 (a) BP4D和(b) DISFA上的性能对比
05
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
VLAD-VSA: 基于词表分离和自适应的跨领域人脸欺诈检测
作者:王炯1、赵洲1、金韦克1、段新宇2、雷震3、怀宝兴2、吴益灵2、何晓飞1
单位:1浙江大学、 2华为云、 3中国科学院自动化研究所
邮箱:
liubinggunzu@zju.edu.cn
zhaozhou@zju.edu.cn
weikejin@zju.edu.cn
duanxinyu@huawei.com
zlei@nlpr.ia.ac.cn
huaibaoxing@huawei.com
wuyiling1@huawei.com
xiaofei_h@qq.com
论文:
https://dl.acm.org/doi/10.1145/3474085.3475284
代码:
https://github.com/Liubinggunzu/VLAD-VSA
人脸欺诈检测是一个图像/视频二分类问题,旨在正确分类真实人脸和欺诈人脸。本文研究的跨领域人脸欺诈检测考虑领域泛化场景,在三个源域(源数据集)上训练,一个目标域上测试。由于源域和目标域人脸的种族,捕获设备,场景以及欺诈手段的不同,造成该任务富有挑战性。
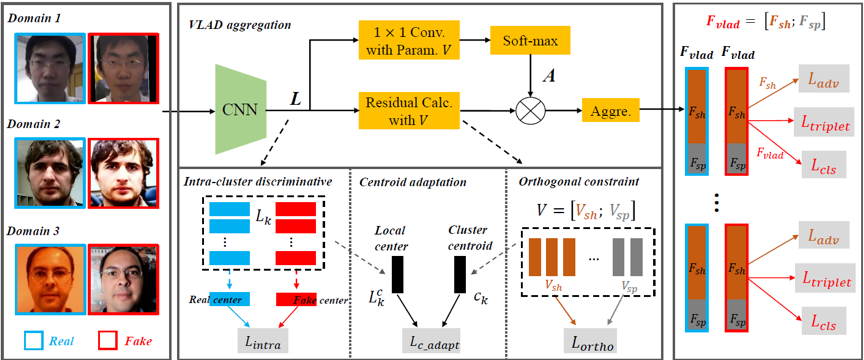
图1 VLAD-VSA 算法流程图
我们结合VLAD-VSA的流程图,来讲解模型流程并突出创新点:
1. 使用VLAD聚合方法代替传统的平均池化(GAP).
由于欺诈人脸的线索通常是细微、局部的,反映到feature map上则是占比较少。常用的GAP将欺诈线索特征和无线索特征求平均得到全局特征进行分类,导致欺诈特征的显著性被削弱。我们使用VLAD聚合方法,使用词表来量化局部特征,将欺诈特征和无线索局部特征分配到不同的视觉单词,再分别聚合,对应到VLAD特征的不同纬度,以保留局部特征的局部辨别能力。如图1所示,带有领域和真假标签的人脸被送入CNN网络中得到局部特征,在VLAD聚合模块中得到全局VLAD特征,然后被分类损失和三元组损失(Lcls, Ltriplet)优化。
2. 词表自适应(Vocabulary Adaptation),优化VLAD中词表的训练。
传统VLAD的词表是通过对局部特征进行聚类得到。K-Means的Expectation step将局部特征分配到视觉簇,maximization step平均簇内的特征求得视觉单词。而在VLAD层的训练过程中,词表作为卷积层的参数进行优化,只有E-step分配局部特征,却没有M-step重新求得词表。因此我们在训练中模拟M-step,约束词表中的视觉单词接近batch内所分配的局部特征的中心(Lc_adapt)。
3. 词表分离(Vocabulary Separation)。
由于领域之间的巨大差异,现有的一些领域泛化工作提出使用领域共享和领域特有的编码器或分类器。受此类方法启发,我们将词表划分为领域共享和领域特有单词,分别生成领域共享和特有特征。在训练中我们只对齐不同领域的领域共享特征的分布(Ladv),而不要求对齐领域特有特征。此外我们还对两种单词施加了正交约束(Lortho),使其可以学习到不同的信息表示。作为一个小的trick,我们还提出簇内区别损失(Lintra),拉大分配到簇内的真实图像的feature和欺诈图像的feature的距离。
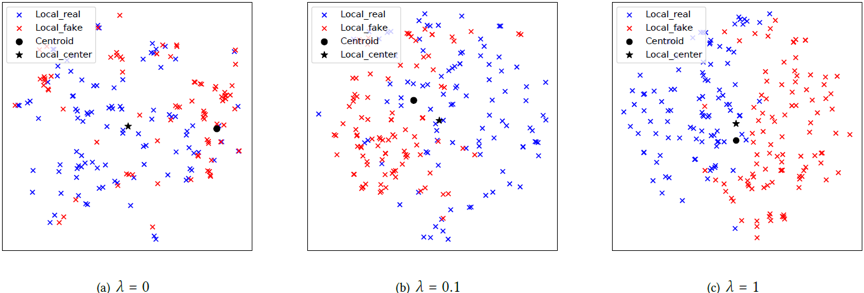
图2 领域自适应作用下的局部特征分布,λ代表损失权重
4. 实验结果
论文所提出的基于VLAD聚合方法的词表自适应,词表分离都可以有效提高欺诈检测效率,实验指标建议读者参阅论文。这里给出局部特征的T-SNE可视化结果如图2所示。可以看到不适用词表自适应的VLAD层中视觉单词远离簇中心,会导致特征不能被良好表示。随着损失权重增大,视觉单词接近簇中心,且簇内的真实特征和欺诈特征有较好的区分度。
06
Former-DFER: Dynamic Facial Expression Recognition Transformer
基于Transformer的动态人脸表情识别网络
作者:赵增群, 刘青山
单位:南京信息工程大学
邮箱:
zqzhao@nuist.edu.cn;
qsliu@nuist.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475292
代码:
https://github.com/zengqunzhao/Former-DFER
1. 引言
人脸表情识别旨在通过对面部行为的识别从而分析目标对象的情感状态,具体的任务是将一张人脸图片或者一段面部视频分类为七类基本情感之一,即,中性、高兴、悲伤、伤心、惊讶、害怕、厌恶、以及生气。由于面部表情本质上是面部动作变化,而其本身就是动态的,因此基于视频序列的面部动作变化可以更好地描述表情。相对于实验室场景下的动态表情识别,自然场景存在着遮挡、非正脸、和头部运动等问题,但更具有研究价值。基于此,本文提出了基于Transformer的识别网络用于自然场景下的动态人脸表情识别。
2. 基于Transformer的动态人脸表情识别网络
最近,研究表明Transformer网络具有强大的特征表达能力,在很多计算机视觉任务上表现出了非常好的性能。而对于动态人脸表情识别任务,从空间角度来看,人脸整体图像中分割出来的人脸局部块可以看作是视觉“单词”序列,从时间角度来看,面部视频片段是连续的,视频片段的每一帧也可以看作是一个视觉“单词”。此外,Transformer中的自注意力机制可以学习每一帧人脸局部特征之间的相关性和人脸视频序列之间的相关性,而这种相关性的学习能够很好地缓解自然场景下遮挡、非正脸、和头部运动等问题的影响。具体的网络结构如图1所示。
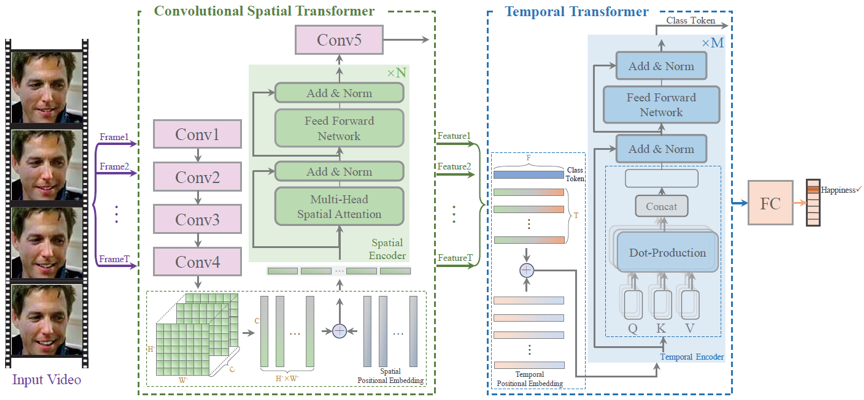
图1 Former-DFER结构图
3. 实验
为了检验Former-DFER对于动态人脸表情识别的有效性,我们在两个视频表情识别数据集上做了实验,表1和表2分别展示了Former-DFER在DFER和AFEW上的性能表现。
表1 Former-DFER与其他方法在DFEW数据集上的性能比较
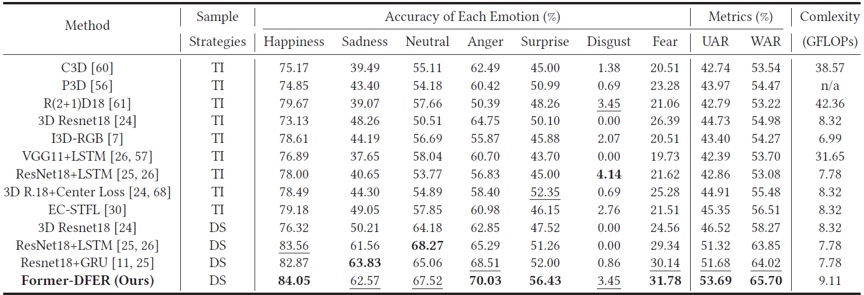
表2 Former-DFER与其他方法在AFEW数据集上的性能比较
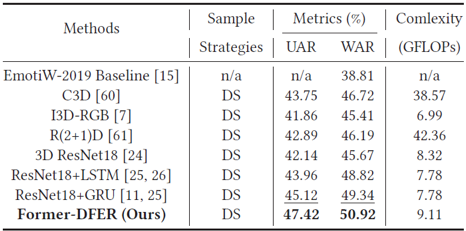
综合来看,相比以往动态人脸表情识别中的常用方法以及SOTA方法,Former-DFER在两个数据集上均带来了较大性能提升。
4. 可视化
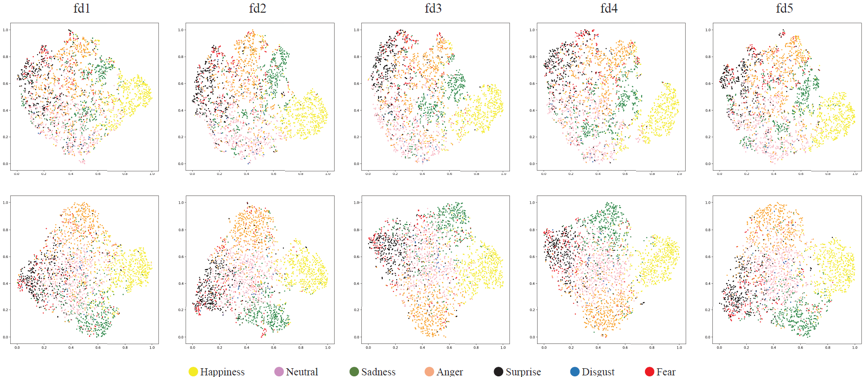
图2 网络学习到的人脸特征分布。相比基准网络(第一行), Former-DFER(第二行)能够学习到更具有判别性的人脸特征。

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜

