【论文导读】2022年论文导读第二期


论文导读
2022年论文导读第二期(总第四十二期)
目 录
|
1 |
Multi-view 3D Smooth Human Pose Estimation based on Heatmap Filtering and Spatio-temporal Information |
|
2 |
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection |
|
3 |
Self-supervised Multi-view Multi-Human Association and Tracking |
|
4 |
Q-Art Code: Generating Scanning-robust Art-style QR Codes by Deformable Convolution |
|
5 |
Weakly-Supervised Video Object Grounding via Stable Context Learning |
|
6 |
Long-Range Feature Propagating for Natural Image Matting |
01
Multi-view 3D Smooth Human Pose Estimation based on Heatmap Filtering and Spatio-temporal Information
一种基于热力图过滤及时空信息的多视角三维流畅人体姿态估计方法
作者:牛泽海1 吕科1 薛健1 马海峰1 魏润辰1
单位:1中国科学院大学
邮箱:
niuzehai18@mails.ucas.ac.cn;
luk@ucas.ac.cn;
xuejian@ucas.ac.cn;
mahaifeng19@mails.ucas.ac.cn;
weirunchen20@mails.ucas.ac.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475185
视频:
https://dl.acm.org/action/downloadSupplement?doi=10.1145%2F3474085.3475185&file=MM21-fp0156.mp4
从时间同步的、经过校准的多视角视频中估计三维人体姿态通常包括两个步骤:(1)通过每一帧的热力图定位关节的二维坐标点位置;(2)使用迭代空间划分模型(3DPS)或三角化方法(Triangulation)等后处理方法获得三维坐标点。然而,大多数现有的方法只基于单帧。它们没有利用视频序列本身的时间特征,必须依赖后处理算法。还容易受到人的自遮挡影响,而且生成的序列存在着明显的抖动。
我们从传统的标记式光学人体动作捕捉系统中获取了灵感,提出了一个包含空间和时间特征的网络模型,在一定程度上克服了长期以来在多视角情况下容易产生的骨架抖动问题,确保了三维姿态序列的平滑和稳定。
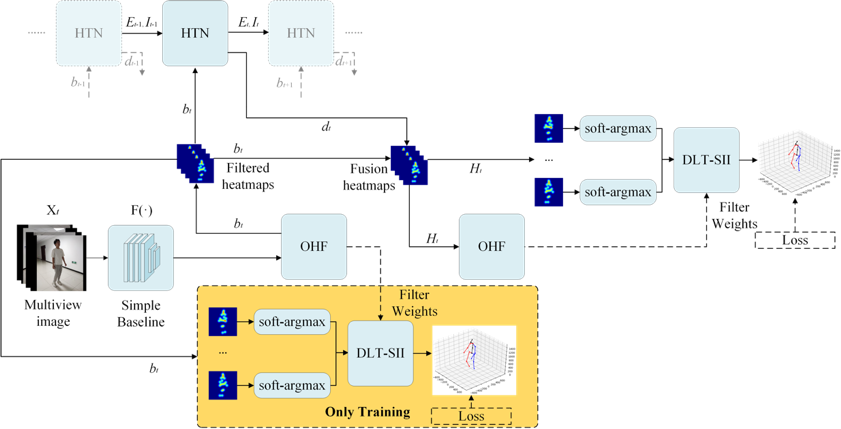
图1 基于热力图过滤及时空信息的多视角三维流畅人体姿态估计方法框图
如图1所示,该方法在热力图层面进行了时序上的增强,提出了一种基于LSTM的热力图时序网络。一般而言,被遮挡的热力图峰值响应较弱,在没有遮挡标签的情况下,使用端到端的方式,将初始的空间热力图馈入遮挡过滤模块,得到过滤后的空间热力图,将过滤后的空间热力图馈入热力图时序网络中,得到时序热力图,之后将过滤后的空间热力图及时序热力图融合,将融合后的热力图进行第二次遮挡过滤,使用过滤后的权重对可微分的三角化过程进行动态的控制,从而使得网络根据空间信息及时间信息判断热力图的被遮挡程度。该模型的学习过程分为多个训练阶段,为了使时间信息及空间信息更好地融合,我们使用了中间监督的方式进行训练,并采用由粗到精的模式,实现网络从空间信息到时空信息的渐进式学习。
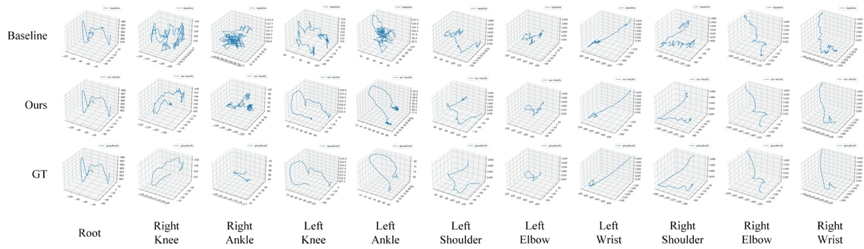
图2 Human3.6M S11序列中容易被遮挡的关节轨迹流畅性可视化比较
我们在Human3.6M上将该方法与当前先进算法进行了对比,并进行了消融实验,图2展示了S11序列中容易被遮挡的关节轨迹的流畅性可视化结果。顶部是基线结果,中间是我们方法的结果,底部是由动作捕捉设备捕获的真实值。我们的方法有效地提高了三维人体姿态估计的平滑性和准确性,并确保了结果与真实情况尽可能接近。实验结果表明该方法在尽量保证动作序列流畅的情况下进一步提升了精度,并且在面临大面积遮挡和极端姿态等情况时仍能获得准确的人体姿态估计结果。图3展示了有遮挡情况下的热力图可视化结果。从图3可以看出本方法在面临多个视角遮挡情况不一时所产生的热力图响应对被遮挡关节进行了较好的抑制,同时对未被遮挡的关节进行了有效的增强。
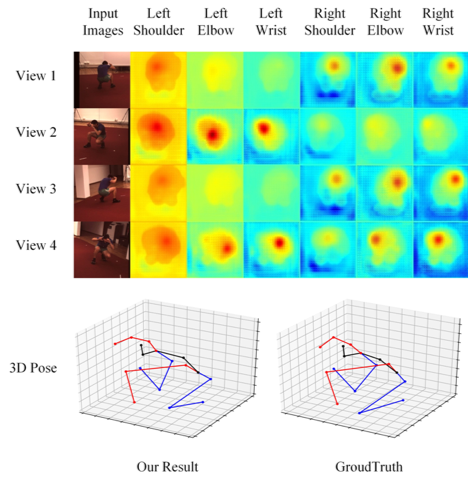
图3 有遮挡情况下的热力图可视化结果

02
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection
用于风景图片动画化的细粒度运动信息学习
作者:秦绪功1,2,周宇1,2,*,过友辉1,2,吴大衍1,田志宏3,蒋宁4,王洪斌4,王伟平1
单位:1中国科学院信息工程研究所,2中国科学院大学网络空间安全学院,3广州大学,4马上消费金融
邮箱:
qinxugong@iie.ac.cn;
zhouyu@iie.ac.cn;
guoyouhui@iie.ac.cn;
wudayan@iie.ac.cn;
tianzhihong@gzhu.edu.cn;
ning.jiang02@msxf.com;
Hongbin.wang02@msxf.com;
wangweiping@iie.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475178
*通讯作者
由于在目标检测和实例分割上取得的巨大成功,Mask R-CNN受到了众多关注,并被广泛用作任意形状场景文本检测及端到端识别的基线方法。然而,基于该框架的方法还有两个问题有待解决。第一个是密集文本场景,在现实中普遍存在,却经常被忽视,在一个候选框中可能存在多个实例,这使得掩码分支难以区分不同的实例并引起性能降低。在这项工作中,我们认为该现象是由于Mask分支中的“学习混淆”问题造成的。我们提出在掩码分支中使用MLP解码器而不是“反卷积-卷积”解码器,这可以缓解该“学习混淆”问题并显著提高检测器的鲁棒性。第二个问题是,由于尺度和长宽比的巨大变化,RPN需要复杂的锚定设置,因此很难在不同的数据集之间进行维护和迁移。为了解决这个问题,我们提出了一种自适应标签分配方法,该方法为所有实例,尤其是那些具有极端长宽比的实例在训练中匹配足够多的锚框。
图1是所提出MAYOR模型的整体框架。区别于之前的方法采用“反卷积-卷积”解码器,在MAYOR中我们采用MLP结构的掩码解码器,可以极大的减少Mask分支中的学习混淆问题,以达到区别不同文字实例的目的;同时,我们提出适应性的样本分配策略,根据损失来选择高质量的锚框作为正样本,在减少了锚框数量的同时提高了性能。学习混淆问题如图2所示,面对密集文本时,临近像素向量特征相似,却分配了完全相反的标签。而全卷积的解码器由于局部连接及权重共享,进一步放大了学习混淆问题。我们还提出了实例感知的掩码学习方式(IAML)作为消除学习混淆问题的尝试。
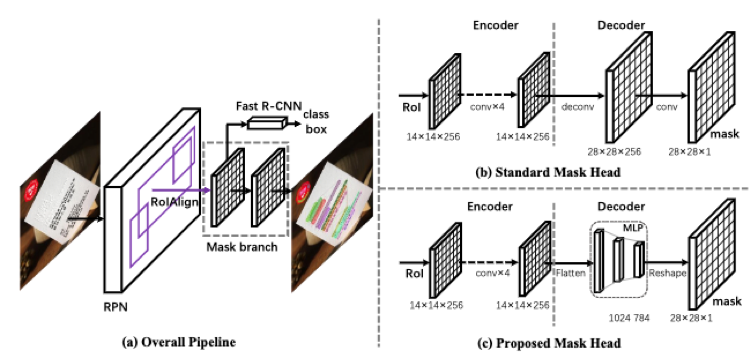
图1 MAYOR模型整体框架
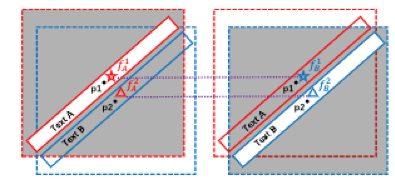
图2 在检测密集文字时Mask分支中的学习混淆问题
MAYOR在多个广泛使用的数据集(DAST1500、ICDAR2015、CTW500、Total-Text等)上进行了实验。如表1所示,它相较于基准方法获得了显著的提升。由表2的实验结果表明,与其他方法比较,MAYOR在多个场景文字数据集上取得最好的性能。图3展示了MAYOR方法在经典通用目标数据集COCO上的泛化性实验结果,结果表明,MAYOR可以得到更全局、更紧凑及更具有实例辨别性的实例分割结果。
表1 MAYOR与已有方法在密集文字数据集DAST1500上的比较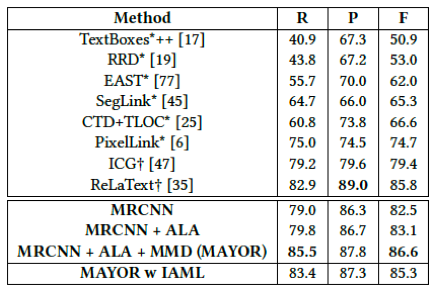
表2 MAYOR与已有方法在ICDAR2015、CTW1500和Total-Text数据集上的比较


图3 在通用目标数据集COCO上实例分割的定性比较
03
Self-supervised Multi-view Multi-Human Association and Tracking
作者:甘夷洋 韩瑞泽 阴立强 冯伟 王松
单位:天津大学
邮箱:
realgump@tju.edu.cn
han_ruize@tju.edu.cn
yinliqiang@tju.edu.cn
wfeng@tju.edu.cn
songwang@cec.sc.edu
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475177
代码:
https://github.com/realgump/MvMHAT
近年来,随着监控安防需求的提升,多目标跟踪(MOT),尤其是多行人跟踪,已经成为了多媒体分析的一个重要的研究领域。现有的多行人跟踪算法存在两个重要的局限:首先,现有方法往往利用单一视角,在行人互相遮挡的情形下容易造成目标丢失,其次,现有的基于深度学习的算法需要大量的人工标注数据进行模型训练。针对上述问题,本文提出了自监督的多视角多行人关联跟踪(MvMHAT)方法。其中,多视角可以缓解行人遮挡问题,而自监督可以避免大量的数据标注。不同于现有的多目标跟踪任务和多目标跨相机跟踪任务只考虑行人跨时间帧的关联,如图1所示,多视角多行人关联跟踪任务可以同时跨视角和跨时间地将行人关联起来,在多人场景下的视频监控具有重大的意义。

图1 多视角多行人关联跟踪任务示意图
本文提出了一个自监督学习网络框架来解决MvMHAT问题。具体地说,给定几个不同视角多人场景视频,我们首先对来自不同视角和时间的帧进行采样,并应用卷积神经网络(CNN)来提取每个行人的深度特征。在训练阶段,如图2所示,我们提出了一个时空关联网络来模拟跨时间关联和跨视角关联,该网络构造了一个相似度匹配矩阵,并且可以通过对称相似(SSIM)和传递相似 (TSIM)损失作为损失函数进行自监督训练。在推理阶段,如算法1所示,我们采用一种新的时空关联跟踪联合优化方法来解决MvMHAT任务。
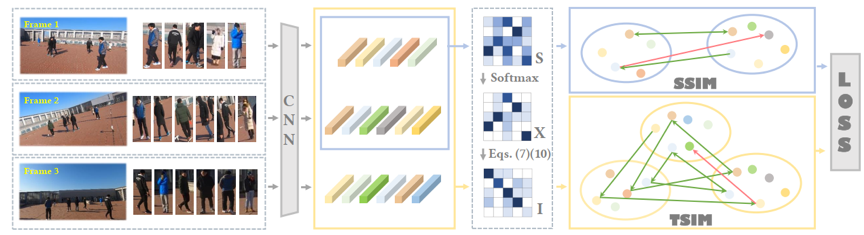
图2 时空关联网络框架示意图
算法1 时空关联跟踪联合优化算法
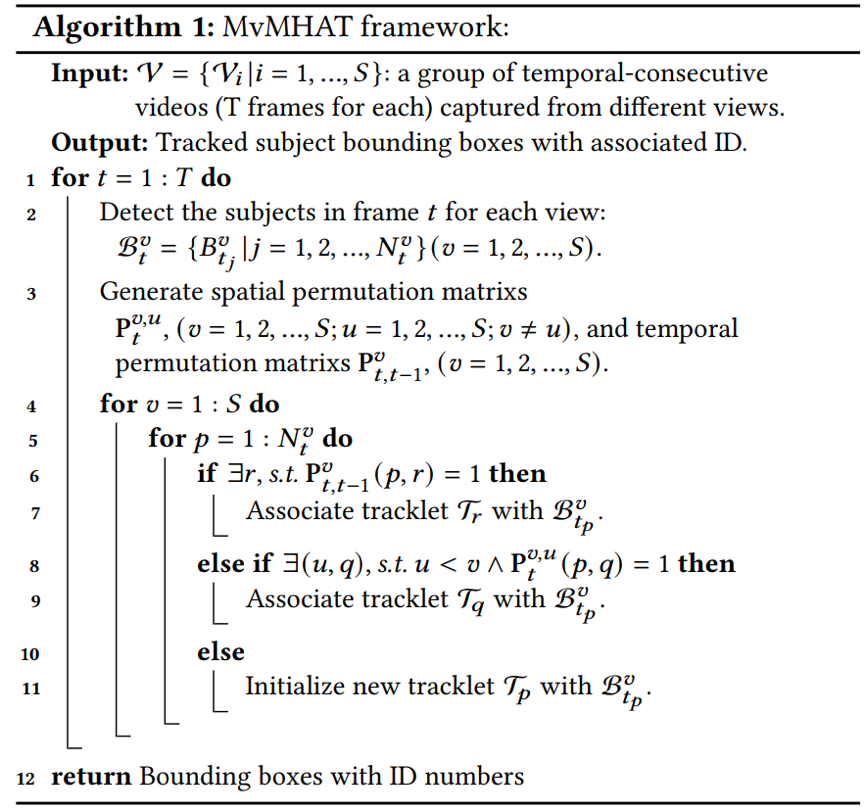
针对目前对MvMHAT的研究还受到缺乏合适的公共数据集的限制,我们构建了一个新的基准数据集,用于MvMHAT算法的训练和测试。表1和图3给出了本文提出方法在数据集上的定量实验结果和定性实验结果,验证了方法的有效性。
表1 与其他相关方法的定量比较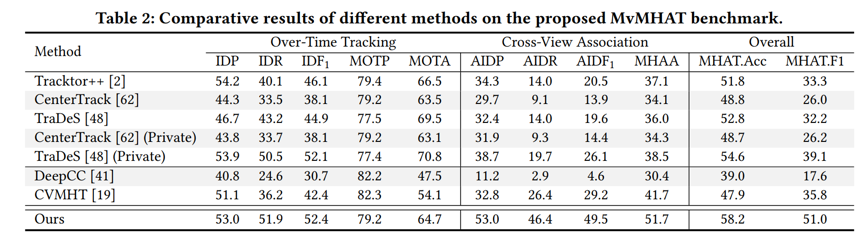

图3 与其他方法的定性比较(a为对比方法, b为本文方法)
04
Q-Art Code: Generating Scanning-robust Art-style QR Codes by Deformable Convolution
作者:苏昊1、牛建伟1,2,3、刘雪峰1、李青锋1、万季1、徐明亮3
单位:1北京航空航天大学-计算机学院-VR国家重点实验室, 2郑州大学-信息工程学院-产业技术研究院, 3北京航空航天大学-杭州创新研究
邮箱:
niujianwei@buaa.edu.cn
liu_xuefeng@buaa.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475239
快速响应(QR)码是世界上应用最广泛的二维码之一,其被广泛应用于社交网络、移动支付、广告宣传等场景。然而,传统QR码的外观为的黑白色方形模块,其视觉单调且无意义。如图1所示,在本文中,我们提出了Q-Art Code,这是一种艺术风格QR码,可以更好地匹配载体的整体风格,从而提高视觉质量和吸引力。

图1 本文提出的艺术风格二维码Q-Art Code,其融合了输入风格目标的艺术特征和QR码的功能性。
为赋予Q-Art Code艺术元素,本文利用了神经风格迁移技术,其可通过卷积神经网络(CNN)将风格目标的风格转移到另一图像。然而,与风格化普通图像不同,对QR码进行风格化的一大挑战是在变换颜色和纹理后必须保持扫描鲁棒性。为解决这些问题,我们在生成方法中提出了一种基于模块的可变形卷积机制(MDCM)和一种动态目标机制(DTM)。如图2所示,MDCM可以分别提取二维码的黑白模块特征,然后将提取的特征反馈给DTM,以平衡扫描鲁棒性和样式表示。MDCM受可变形卷积网络的启发,其对CNN的采样网格进行变形,以分别提取黑白模块的特征。具体地说,我们将QR码的每个方形模块视为采样网格,并计算偏移贴图以按照模块分布变形CNN的采样网格。然后,将QR码的所有黑色(或白色)模块提取到一个特征图,网络将约束特征图为由DTM自适应计算的较暗(或较亮)目标色调,以保证每个模块的鲁棒性。
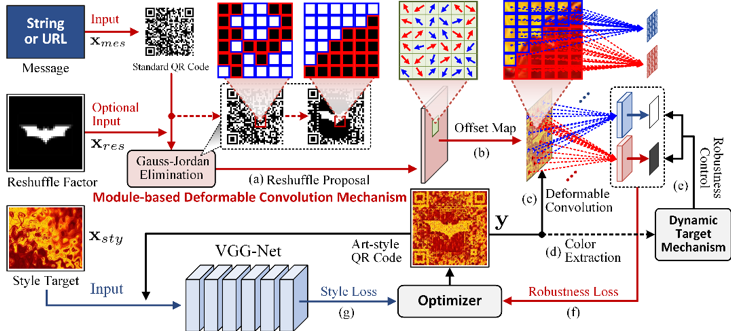
图2 整体流程图。(a)-(c) 基于模块的可变形卷积机制。(d)(e) 动态目标机制。(f)(g) 优化器采用样式损失和鲁棒性损失来约束输出QR码的艺术风格和扫描鲁棒性。
大量主观和客观实验证明,我们的方法在视觉质量和扫描鲁棒性方面都达到了世界先进水平。此外,Q-Art Code有潜力在一些场景下取代现实应用中的标准QR代码。
05
Weakly-Supervised Video Object Grounding via Stable Context Learning
作者:王威,高君宇,徐常胜
单位:中国科学院自动化研究所,中国科学院大学人工智能学院,鹏城实验室
邮箱:
wangwei2018@ia.ac.cn
junyu.gao@nlpr.ia.ac.cn
csxu@nlpr.ia.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475245
根据自然语言描述在视频中对目标物体区域进行定位是一项在诸多下游任务中都需要的能力。如图1所示,由于在视频中进行细粒度的物体标注十分昂贵,因此目前大多数方法都聚焦于弱监督的训练设定,即只有视频和对应的自然语言描述语句标注。虽然该任务近期取得了许多进展,但是它们都没有充分挖掘自然语言描述在跨模态匹配中的潜力。一方面,大多数方法仅从自然语言描述中简单的提取物体文本并用固定的词向量对其进行表示,而忽视了该物体文本丰富的上下文句子内容。另一方面,一些方法尝试了利用上下文来丰富物体文本表示,但这导致了不稳定的跨模态对齐训练,从而大幅降低了性能。其原因在于,在弱监督设定下缺乏对物体区域和对应文本的直接监督信号,多样的物体文本表示会导致跨模态匹配噪声很大,而稳定的物体文本表示则可以在匹配空间中为物体区域提供稳定的聚类中心。

图1 全监督和弱监督的视频物体定位
基于上述观察,我们提出了一个稳定上下文学习的框架(如图2所示),其同时具备稳定训练和丰富上下文信息的优势。我们旨在学习一个稳定的物体概念表示,其对于在不同上下文句子中的同一物体文本而言,具有特征不变性和上下文泛化性。为此,我们设计了上下文感知的物体稳定器模块和跨模态对齐知识迁移模块。这两个模块可以相互配合,在文本模态中将丰富的上下文信息注入到稳定的物体概念中,同时在跨模态对齐中迁移上下文的丰富知识信息。具体地,对于上下文感知的物体稳定器模块,我们利用语言模型(如:BERT)提取同一物体文本在不同句子中的上下文信息,然后利用对比学习的策略将其注入到对应的稳定物体概念表示中。对于跨模态对齐知识迁移模块,我们从物体文本的上下文信息中提取与该物体概念表示相关的部分知识,然后将这一部分知识通过在跨模态对齐的时空相似度分数层面进行迁移,从而帮助学习稳定的物体概念表示。最后,整个模型在一个帧级别的多实例学习框架下进
行优化训练。
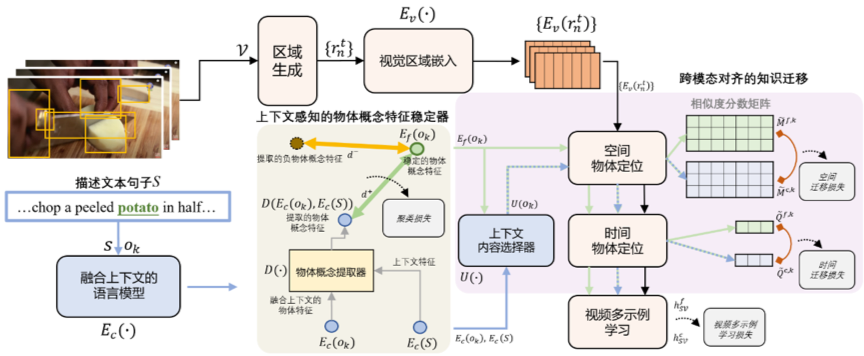
图2 本文中的稳定上下文学习框架
实验结果表明,我们的方法通过充分利用丰富的上下文信息和稳定的训练过程,可以显著提高现有的弱监督视频物体定位的性能,并在多个数据集上均超越了当前最好的方法。图3展示了我们的方法在标准的弱监督视频物体定位数据集YouCook2-BB上的实验结果。

图3 在YouCook2-BB数据集上的结果
06
Long-Range Feature Propagating for Natural Image Matting
作者:柳青林1,谢浩哲1,张盛平1*, 钟必能2, 纪荣嵘3
单位:1哈尔滨工业大学, 2广西师范大学,3厦门大学
邮箱:
qinglin.liu@outlook.com;
hzxie@hit.edu.cn;
s.zhang@hit.edu.cn;
bnzhong@gxnu.edu.cn;
rrji@xmu.edu.cn
论文:
https://dl.acm.org/doi/epdf/10.1145/3474085.3475203
代码:
https://github.com/QLYoo/LFPNet
*通讯作者
在自然图像抠图任务中,估计未知区域的透明度遮罩依赖于已知前景、背景区域的信息。然而在处理高分辨率图像时,传统的卷积神经网络受限于较小的有效感受野,无法捕获长距离关联和利用空间结构信息,无法取得令人满意的效果。通过观察图1中的数据和统计,我们可以明显看出抠图任务中捕获长距离特征的重要性。此外大部分抠图方法需要以完整图像作为输入,因此在处理高分辨率图像时会因为显存限制而无法在GPU设备上执行。
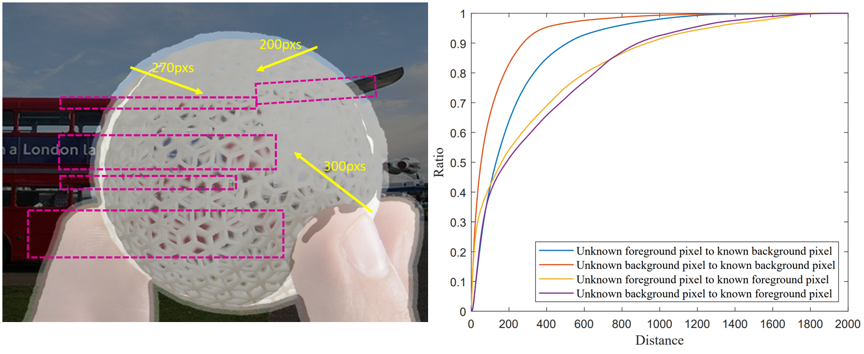
图1 Adobe Composite-1K抠图数据集展示与数据统计。左图:抠图图像展示,分辨未知区域内的前景与背景需要长距离外的已知区域信息;右图:抠图数据统计,在Adobe抠图数据集中与位置区域关联的最邻近已知区域超越了传统CNN网络感受野。
为了解决以上问题,我们提出了进行长距离特征传播的抠图网络LFPNet。LFPNet架构如图2所示,网络采取了一个基于块的推断方式,在图像上依滑窗的方式提取中心图块和环绕着中心图块的上下文图块,然后输入网络抠图模块和传播模块处理。上下文图块在降采样后使用传播模块进行长距离特征传播,为了将上下文图块的信息传播到中心区域,我们设计了一个中心周围金字塔池化模块,如图3所示,通过在更大范围内进行多尺度块级池化和孔洞卷积平滑显式地完成了长距离特征传播。传播模块提取的特征与抠图模块的局部特征结合后直接可以预测高精度的透明度遮罩。
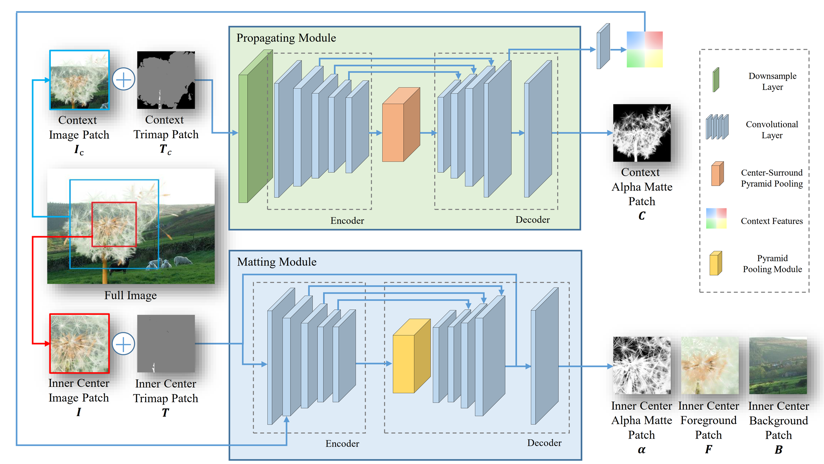
图 2 LFPNet模型结构图
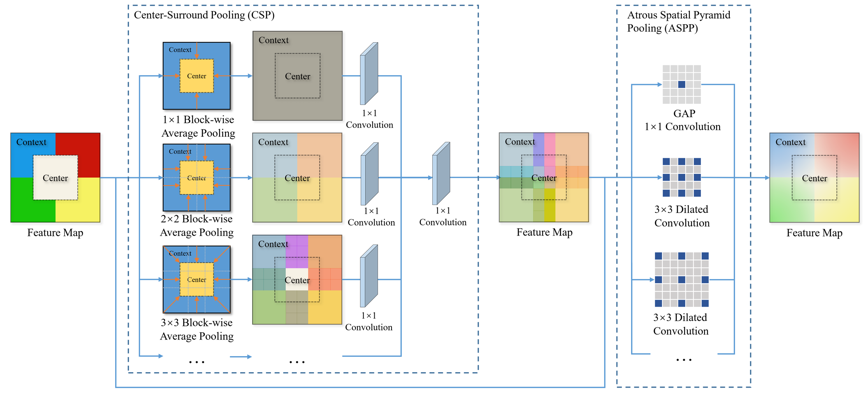
图3 中心周围金字塔池化
论文在多组数据上进行了评估,如图4,5,6为提出的方法在AlphaMatting,Adobe Composite-1K和真实世界高分辨率图像上测试的定性结果。提出的方法有更好的视觉观感,在网状区域可以利用长距离特征将背景分出来,在大块未知区域的情况下能够更加稳定的预测出前景目标的透明度遮罩。如表1为提出的方法在AlphaMatting,Adobe Composite-1K图像上的定量结果,提出的方法取得了较好的指标。定性与定量实验证明了本文提出的方法在抠图任务上的有效性。
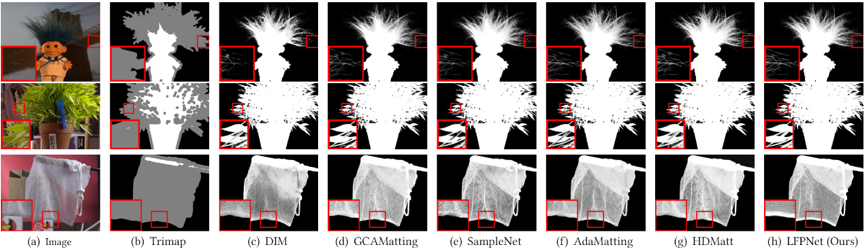
图4 AlphaMatting图像定性结果
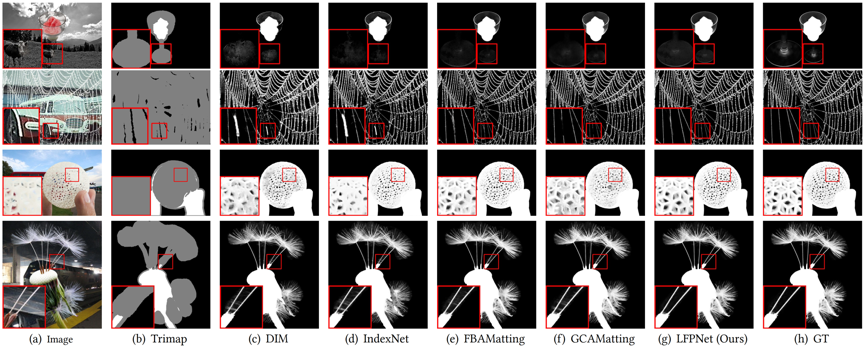
图5 Adobe Composite-1K图像定性结果

图6 真实世界高分辨率图像定性结果

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜

