【论文导读】2022年论文导读第五期


论文导读
2022年论文导读第五期(总第四十五期)
目 录
|
1 |
Differentiated Learning for Multi-Modal Domain Adaptation |
|
2 |
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory |
|
3 |
Attribute-specific Control Units in StyleGAN for Fine-grained Image Manipulation |
|
4 |
Semantic-Guided Relation Propagation Network for Few-shot Action Recognition |
|
5 |
Learning What and When to Drop: Adaptive Multimodal and Contextual Dynamics for Emotion Recognition in Conversation |
|
6 |
Searching Motion Graphs for Human Motion Synthesis |
01
Differentiated Learning for Multi-Modal Domain Adaptation
作者:吕建明,刘凯杰,何盛烽
单位:华南理工大学
邮箱:
jmlv@scut.edu.cn
cskaijieliu@gmail.com
shengfenghe7@gmail.com
论文:
https://dl.acm.org/doi/10.1145/3474085.3475660
代码:
https://github.com/KaijieL/DLMM
1. 引言
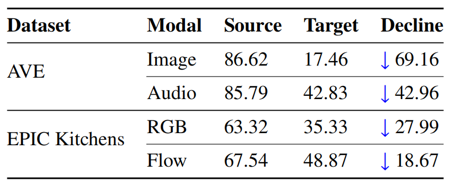
近年来,多模态数据挖掘受到越来越广泛的关注,尤其是与传统的单模态数据有监督学习不同,利用海量无标记数据的无监督多模态数据学习更接近人类学习的真实案例。由于域漂移(Domain Shift)的存在,将预训练的多模态模型直接迁移到新的场景下通常存在性能下降的问题。为了应对这一挑战,当前的主要技术路线是多模态域适应(Multi-modal Domain Adaptation),简称MDA。现有的MDA方法大致分为两类,一类以对抗学习为基础(如MM-SADA、MDANN等),另一类以协同学习为基础(如Co-Training、UMCT等),然而现有方法均未考虑到不同模态之间的差异性,而是将不同模态数据的模型平等化对待。实际上,我们发现不同模态的域漂移程度通常是不同的,如图1 (a) 所示,直观上可以观察到AVE数据集中图像模态的域漂移程度明显要大于音频模态,表1中的结果则进一步证实了跨域后图像模态的性能下降幅度要远大于音频模态。因此,这启发我们利用模态间的差异性来设计一种新的多模态域适应方案:首先通过衡量各个模态决策的可靠性以产生更为准确的伪标签,之后根据每个模态的自身的学习能力分别按照由易到难的顺序进行课程学习,最终通过基于可靠性感知的融合方案做出最终决策。
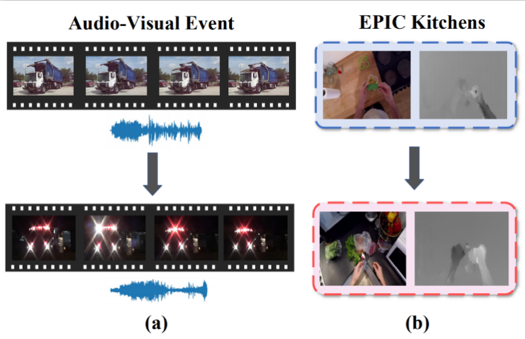
图1 多模态数据跨域场景下的域漂移示例。(a) AVE数据集的域漂移;(b) EPIC Kitchens数据集的域漂移。
表1 AVE数据集上不同模态数据的模型跨域后的准确率比较
2. 方法概述
如图2所示,本文所提出的差异化学习多模态域适应框架DLMM分为四个阶段:1)预训练阶段,各个模态的模型分别在源域数据上进行特征提取器、分类器和原型网络的预训练;2)伪标签可靠性评估阶段,各个模态模型分别在原型空间中衡量目标域样本和源域上的类原型的距离,并以此作为对于目标域样本决策的可靠性,最终选取可靠性最高的模型预测作为所有模型的共同伪标签;3)异步学习阶段,各个模型根据自身的能力从共同的伪标签中按照由易到难的顺序选取增量学习样本,由于各个模型对于目标域伪标签的学习顺序是不同的,故称之为异步学习;4)可靠性感知的融合决策阶段,在对目标域样本进行预测时,利用各个模型的可靠性来加权融合所有模型的决策,从而获取更准确的预测结果。
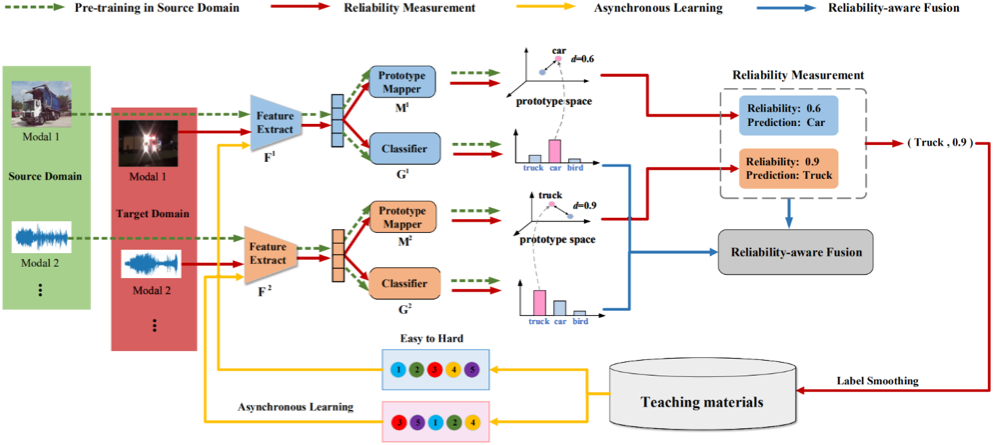
图2 本文所提出的DLMM框架图
3. 实验结果
本文提出的方法DLMM在三个多模态跨域数据集上与现有的多模态域适应方法和单模态域适应方法的比较如表2、表3和表4所示,本文方法相较于其他先进方法取得了更好的跨域效果。图3展现了AVE数据集上的特征可视化效果,可以看到相比于其他方法,本文方法DLMM能够更好地减少源域和目标域的域漂移。
表2 不同方法在AVE数据集上的准确率比较
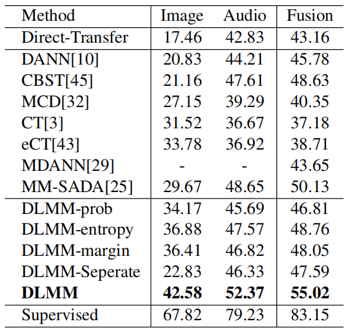
表3 不同方法在CogBeacon数据集上的准确率比较
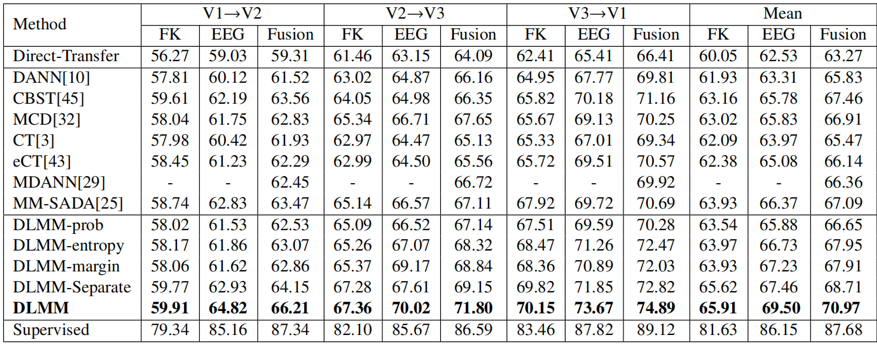
表4 不同方法在EPIC Kitchens数据集上的准确率比较
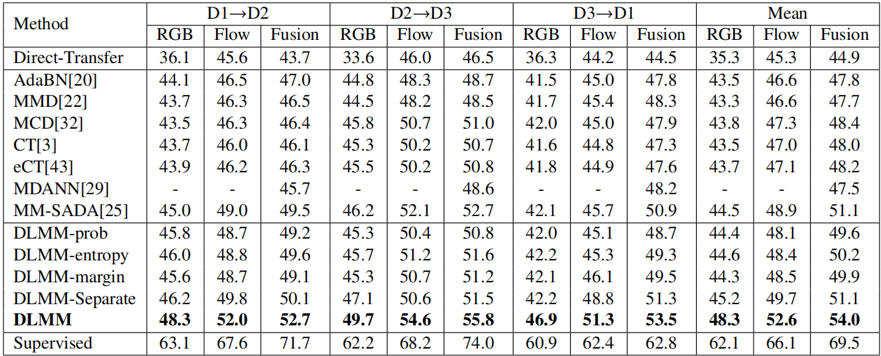
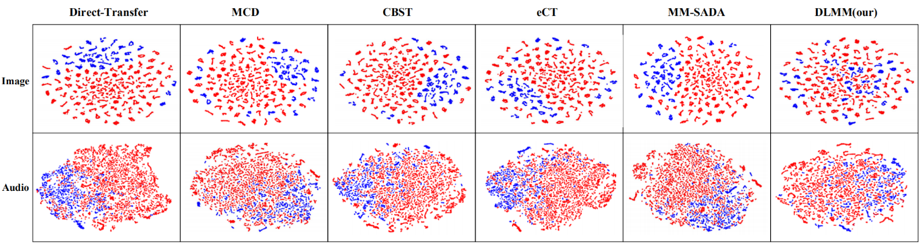
图3 不同方法在AVE数据集上生成的图像模态和音频模态的t-SNE可视化展示

02
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory
注意力引导自适应记忆的实时唇语识别
作者:林志杰1+,赵洲1*,李昊沅1+,刘静林1,张檬2、曾幸山2、何晓飞1
单位:1浙江大学、2华为诺亚方舟实验室
邮箱:
linzhijie@zju.edu.cn
zhaozhou@zju.edu.cn
lihaoyuan@zju.edu.cn
liujinglin@zju.edu.cn
zhangmeng92@huawei.com
zxshamson@gmail.com
xiaofei_h@qq.com
论文:
https://dl.acm.org/doi/10.1145/3474085.3475220
代码:
https://github.com/NYElegance/SimulLR
*通讯作者,+相同贡献
一、背景
唇语识别是一种不依赖于音频,根据给定的唇动视频来识别口语句子的任务,这在多种场景下有应用价值,如嘈杂环境的听写、为听力不佳的人群提供帮助等。因此,其引起人们的极大兴趣。尽管之前研究唇读的作品已经取得了显著的成就,但它们都是以非同时的方式进行训练的,在这种情况下,识别唇语是需要读取完整的视频才能产生的。为了突破这一限制,我们研究了实时唇语识别的任务。
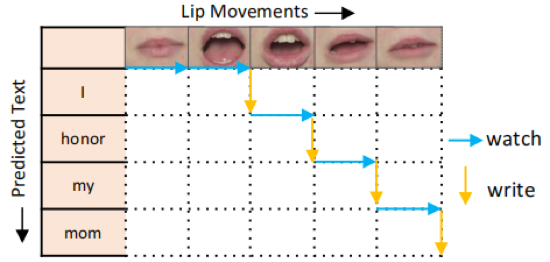
图1 SimulLR可在读取部分视频段便预测文字,而无需读取整个视频
二、方法
我们研究了实时唇语识别的任务,并从三个方面设计了具有注意力引导自适应记忆的唇语识别器SimulLR:(1)为了解决同时设置下生成的句子单调对齐的问题,同时考虑其句法结构,我们建立了一个基于传感器的模型,并设计了有效的训练策略,包括CTC预训练、模型预热和课程学习,来促进唇读传感器的训练。(2)为了更好地学习同步编码器的时空表示,我们构造了一个截断的3D卷积和限时的自注意力层,在固定帧数的视频片段中进行帧与帧的交互。(3)在实时场景下,特别是在海量视频数据的情况下,历史信息往往会被大量存储。因此,我们设计了一种新的注意引导自适应记忆方法来组织历史片段的语义信息,并在可接受的计算延迟的情况下增强视觉表示。
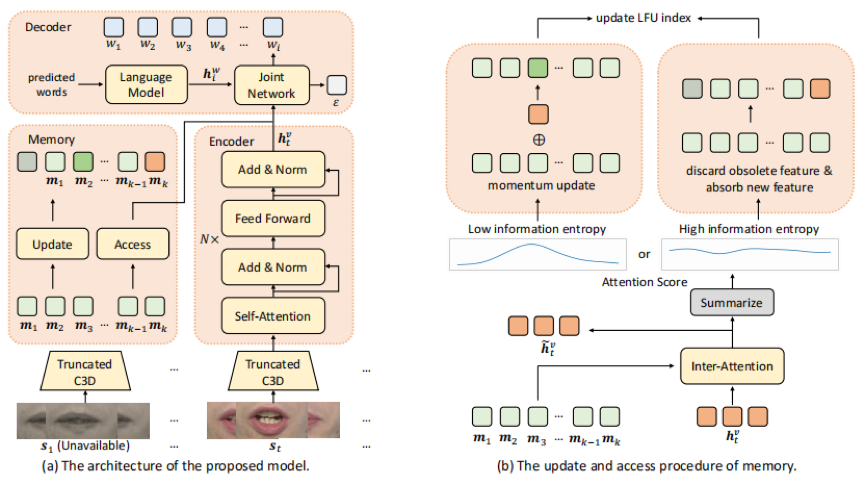
图2 模型框架图
三、实验结果
我们首先与最先进的非实时模型在性能与时延上进行对比。
表1 与先进非实时模型的性能对比
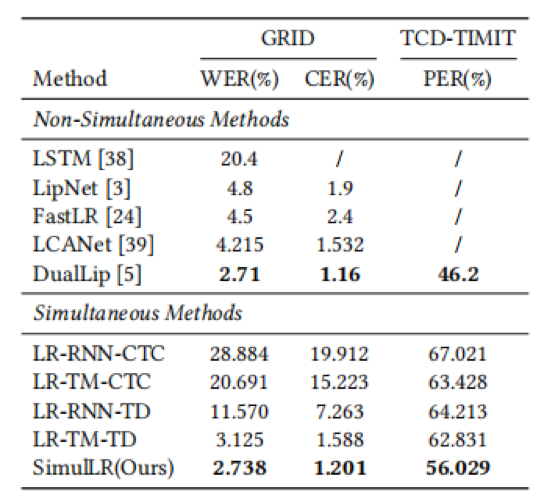
表2 与先进非实时模型的性能与时延对比
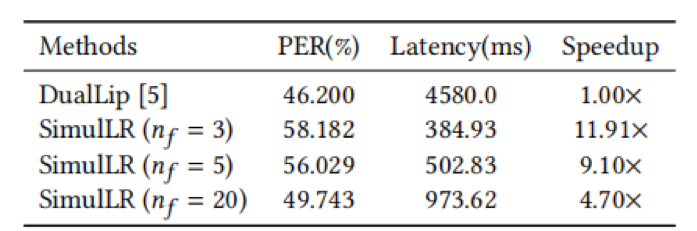
实验结果表明,与目前最先进的非同步方法相比,在每段帧数为5的情况下,SimulLR的识别速度提高了9.10倍,并取得了具有竞争力的结果,表明了本文方法的有效性。
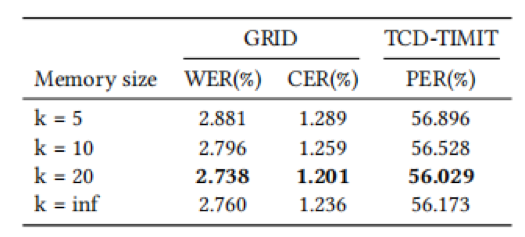
此外,我们探究了不同的训练策略、记忆块更新策略,以及记忆块尺寸的影响。
表3 不同训练策略的的影响
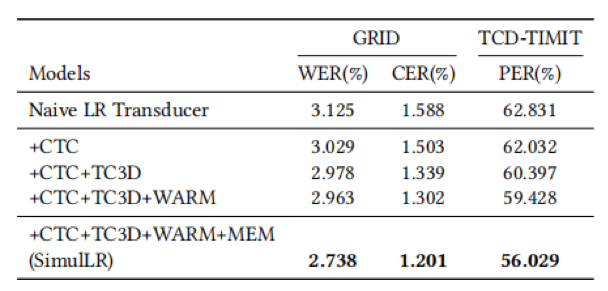
表4 不同记忆块更新策略的影响
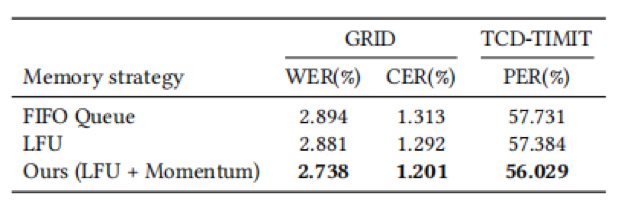
表5 不同记忆块尺寸的影响
最后,我们对模型相关结果进行可视化。
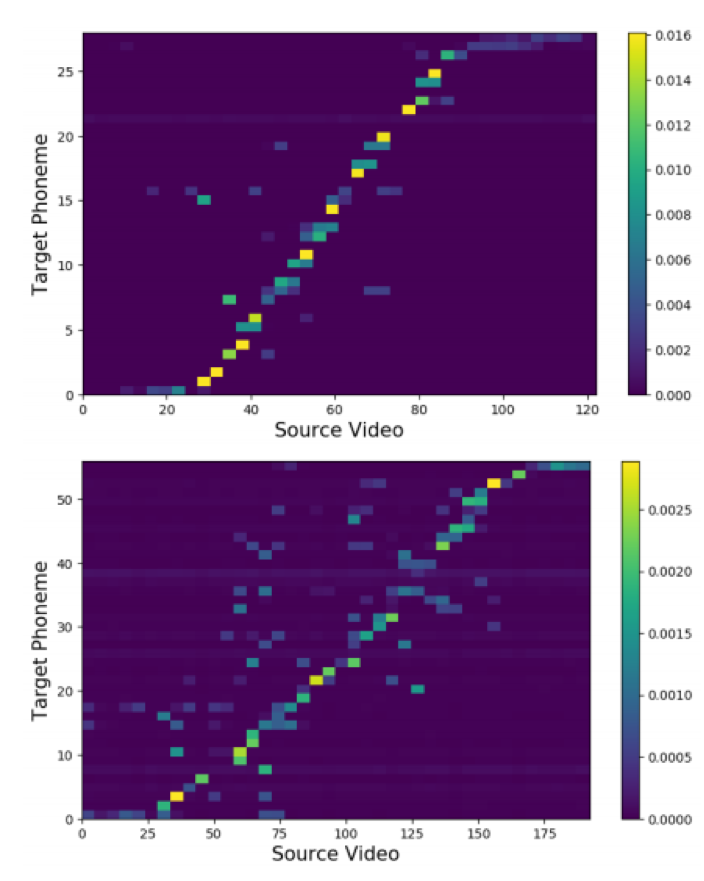
图3 视频帧与目标词序列的单调对齐的可视化结果
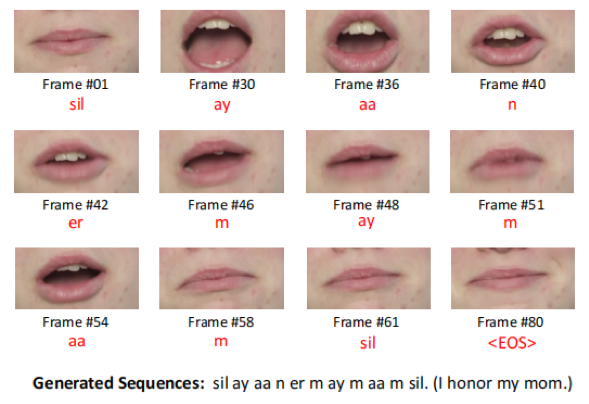
图4 实时唇语识别样例
03
Attribute-specific Control Units in StyleGAN for Fine-grained Image Manipulation
基于StyleGAN属性特定控制单元的精确图片编辑
作者:王锐1,陈健2,俞刚2,孙力3,余昌黔1,高常鑫1,桑农1
单位:1华中科技大学人工智能与自动化学院、2腾讯 3华东师范大学
邮箱:
autowangrui@hust.edu.cn
urichen@tencent.com
skicy@outlook.com
sunli@ee.ecnu.edu.cn
changqian_yu@hust.edu.cn
cgao@hust.edu.cn
nsang@hust.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475274
项目主页:
https://wrong.wang/x/Control-Units-in-StyleGAN2/
代码:
https://github.com/budui/Control-Units-in-StyleGAN2
针对预训练的StyleGAN生成器,通过分析控制其多个语义隐空间的图片编辑方法近年来取得了巨大的成功。然而由于这些隐空间的语义和空间的操作精度有限,现有的语义编辑方法在局部属性编辑任务上表现欠佳。为了解决这一问题,我们分析发现StyleGAN2生成器中存在着属性特定的、由多个通道特征图和调制参数组成的控制单元。通过协同修改控制单元中的调制参数和特征图,能够实现对生成图片空间和语义解耦的精确属性编辑。
StyleGAN2中的中间特征图具有明显的局部激活特性。如图1所示,对应于不同生成图片的中间特征图在相同的人脸语义区域持续激活。基于此,我们设计了一种基于梯度反向传播的特征图高激活区域判定方法,能够简单有效地定量衡量特征图及其对应的调制参数的区域相关性。根据每个通道不同的区域激活特性,能将生成器中间特征和调制参数的不同通道划分为多组。
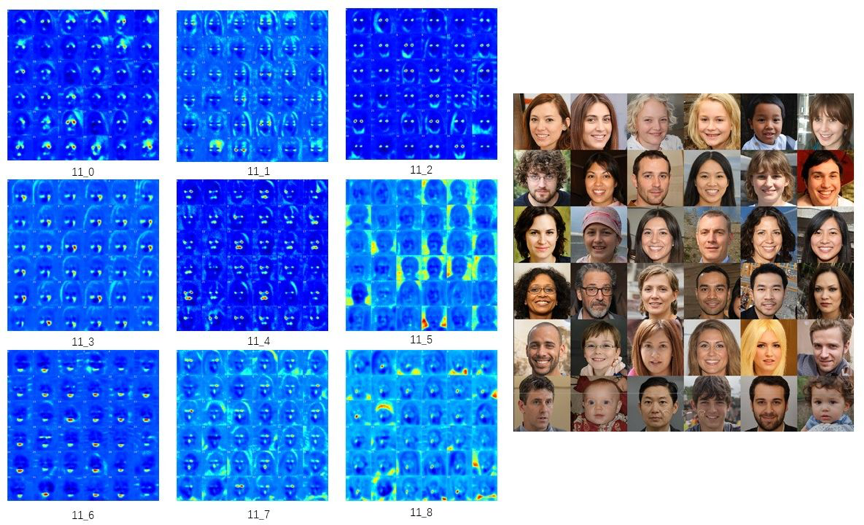
图1 第11层卷积输入特征的前9个通道
如图2所示,选择两个正负样本,计算这两个样本对应的调制参数之差,然后保留不同层的不同区域相关的调制参数之差,可以构造多个稀疏的语义编辑向量。沿着这些语义编辑向量移动调制参数,可以实现多种语义编辑效果。

图2 不同稀疏语义向量的编辑效果
但是,仅依靠这些稀疏的方向向量实现的语义编辑效果面临目标区域变化不足和无关区域耦合严重的问题。如图3所示,无论是变化不足还是耦合问题,图片编辑前后的差别图和被修改调制参数通道对应的特征图的空间分布十分相似。深入分析StyleGAN2的合成机制后,我们认为同之前的文章类似地只修改调制参数不足以实现精确的局部属性编辑,而应当协同操纵调制参数及其对应的特征图。我们把这些对应于不同局部属性编辑任务的调制参数及其调制的特征图合称为控制单元。

图3 稀疏方向向量编辑存在的问题
对控制单元的修改包含一个调制参数方向向量∆Sl和一个优化得到的调制参数\hat{S}^{l-1}。如图4所示,第l层卷积的输入特征的Fl一部分通道FlUa由优化得到的\hat{S}^{l-1}作为上一层调制参数调控生成;第l层卷积的调制参数则沿着稀疏的方向向量∆Sl移动。
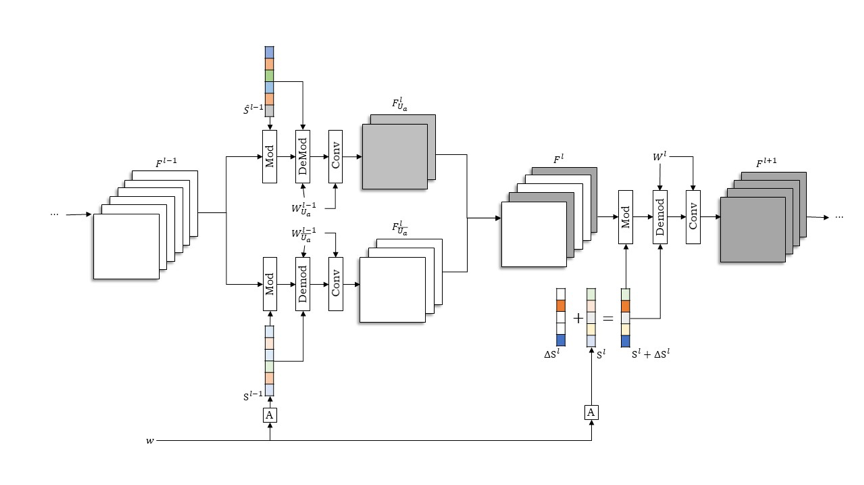
图4 操纵控制单元的流程图

图5 针对不同区域的不同属性编辑任务
如图5所示,本文所提出的方法能够编辑各种语义区域的多种属性,同时无论是空间还是语义层面,解耦程度都很高。图6和图7则进一步通过可视化说明了本文所提方法的有效性。
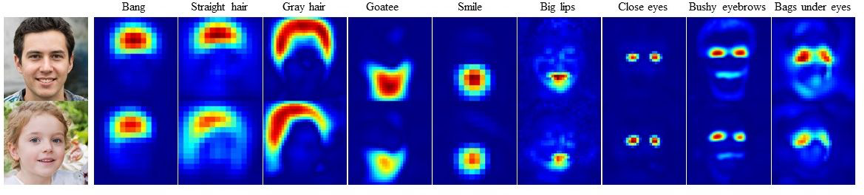
图6 不同控制单元中特征图的可视化

图7 对特征图的修改能大幅度提升编辑效果
04
Semantic-Guided Relation Propagation Network for Few-shot Action Recognition
基于语义引导的关系传播网络的小样本行为识别
作者:王晓1,叶伟荣1,祁仲昂2,赵珣2,王光格1,单瀛2,王菡子1,*
单位:1厦门大学福建省智慧城市感知与计算重点实验室,2腾讯PCG应用研究中心(ARC)
邮箱:
xiaowang@stu.xmu.edu.cn;
weirongye@stu.xmu.edu.cn;
zhongangqi@tencent.com;
emmaxunzhao@tencent.com;
guanggew@stu.xmu.edu.cn;
yingsshan@tencent.com;
wang.hanzi@gmail.com
论文:
https://dl.acm.org/doi/pdf/10.1145/3474085.3475253
*通讯作者
1. 引言
行为识别是指给定一段视频序列,判定其所属行为动作的类别。随着近几年深度学习的迅猛发展,为行为识别提供了新的解决思路。然而在标记样本缺乏的情况下,传统的深度学习方法容易遭受过拟合和泛化性差等问题,因此小样本行为识别受到了越来越多的关注。已有的小样本行为识别方法,研究者更多地关注如何从视频中获取更加有用的信息。但由于这些方法的输入仅有视频本身,忽略了视频标签中蕴含的语义信息。对于样本较少的行为类别来说,很难通过少量的训练样本得到较为鲁棒的模型。然而人类在识别行为类别的过程中,往往通过少量样本,就能识别出新类别。由于标记样本需耗费大量的人力物力,因此现实生活中训练样本较少。本文结合了小样本学习和行为识别,通过利用少量的样本进行训练,就能识别出新的行为类别,更符合现实需求。
2. 方法概述
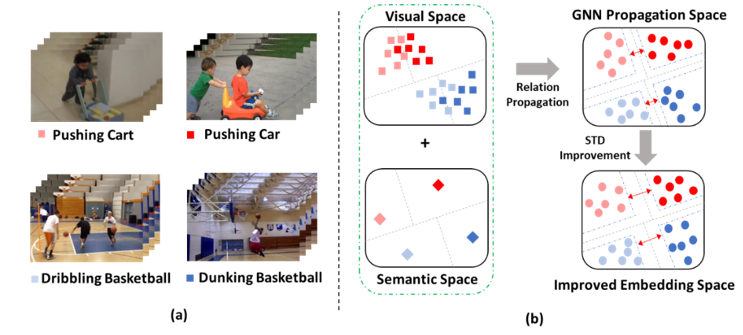
图1 语义引导的关系传播网络示意图
图1展示的是语义引导的关系传播网络示意图。首先,研究者发现当训练样本较少时,仅仅利用视频中的视觉特征是不能够得到较好的分类。然而样本中不仅包含视频信息,还包含语义信息。为了能够让视觉特征更加具有判别力,该研究同时利用样本中的视觉信息和语义信息,使得视觉特征更加具有判别力。同时,单纯的依赖语义信息去增加视觉特征的判别力是不够的,该研究又提出了时空差异性模块来提升对视频的视觉特征学习能力。该模型的优势在于能够利用跨模态信息为视频描述提供指导,从而增强视觉特征的判别力;同时,时空差异性模块也提升了网络对视频特征的学习能力。时空差异性模块是一个即插即用的模块,便于在其他领域进行模块内容的扩展。
整体流程如下图2所示:
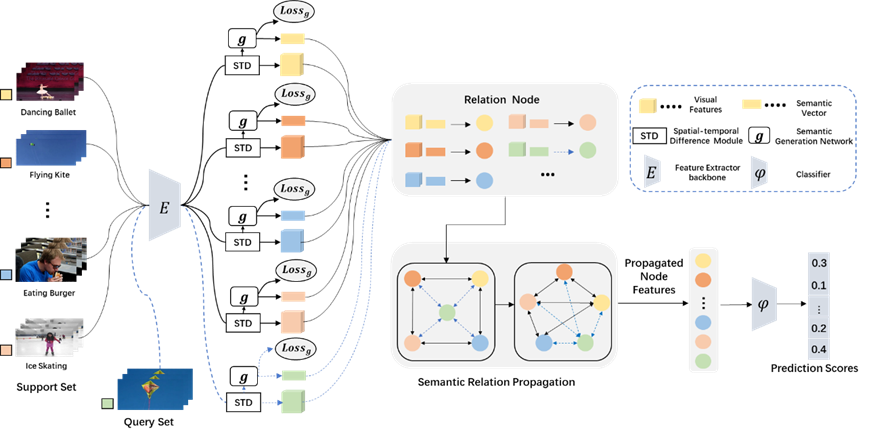
图2 语义引导的关系传播网络框架图
时空差异模块(STD):将视频映射到视觉空间当中,时空差异模块通过获取特征级别上的运动信息和探索在细粒度级别上的空间信息来提升视觉特征的表征能力。
语义生成网络 (g):把时空差异模块生成的视觉特征转化成相应行为类的语义特征。主要是利用语义生成损失使得语义生成网络生成的语义信息更接近真实的标签信息。
图卷积神经网络:把语义信息和视觉信息融合后输入到图卷积网络进行关系传播,得到的特征进行最后的分类。
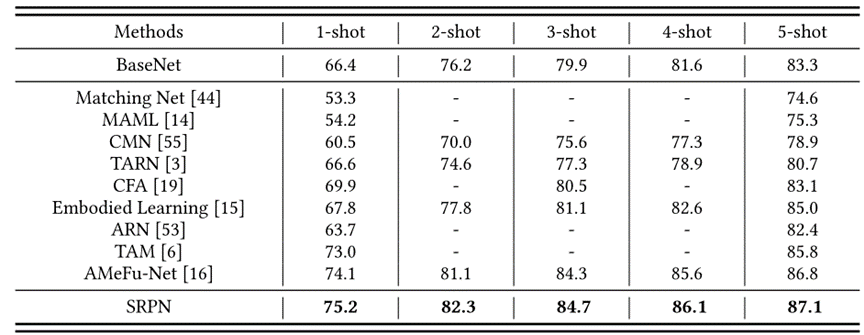
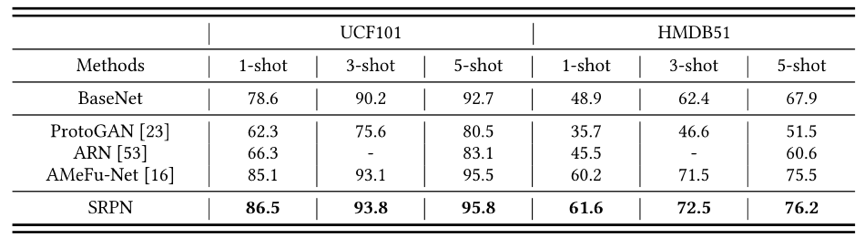
3. 实验结果
本文在三个常用的数据集MiniKinetics,UCF101和HMDB51做了相关实验。实验结果可以看出该方法获得了较好的表现,并验证了其有效性。
05
Learning What and When to Drop: Adaptive Multimodal and Contextual Dynamics for Emotion Recognition in Conversation
作者:陈飞宇1,孙政霄1,欧阳德强2,刘学亮3,邵杰1*
单位:1电子科技大学,2重庆大学,3合肥工业大学
邮箱:
chenfeiyu@std.uestc.edu.cn,
shaojie@uestc.edu.cn
论文:
https://doi.org/10.1145/3474085.3475661
*通讯作者
在情绪识别任务中,多模态感知较单模态数据包含更丰富的信息,然而在某些情况下,某些模态可能会包含模棱两可的信息或与其它模态冲突的极性。因此,如何确定在每种模态中保留或丢弃哪些信息,以提高情绪识别的准确性,同时保持对多感官数据类型增加的可扩展性,是一个关键的挑战。目前对于多模态动力学进行建模的方法主要有两类。大多数传统方法采用基于聚合的模态融合,即多个单模态分支通过拼接、注意力机制或张量积等方式聚合成单个网络,如图1(a)所示。然而这类方法中的多模态动力学严重依赖于手动设计,存在大量可能的聚合结构,增加了寻求最佳策略的难度与额外的工程开销。近年来,研究人员转向一种更先进的模态均衡探索方法,通过使用额外的模态特定和模态共享网络以捕捉丰富的模态内和模态间关系, 如图1(b)所示。尽管这种范式有效,但它对于快速增长的新模态的可扩展性很弱。
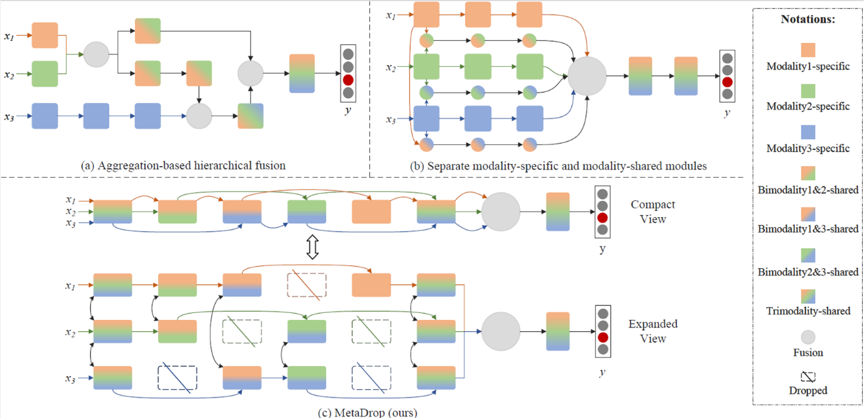
图1 总体框架
本工作寻求探索一种能以较小的成本有效适应多感官数据类型增加,同时实现充分的多模态信息交互的机制。我们提出了MetaDrop,在该框架中,模型可以自行学习以决定哪些模态里的哪些子模块由于干扰而丢弃,保留作为模态特定信息,或在跨模态中共享,且无需手动组合。如图1(c)所示,MetaDrop为每个模态中的每个子模块学习一个保留或丢弃的二元决策,自适应地选择执行或跳过哪些子模块,即决定哪些子模块被丢弃、被融合共享或被作为模态特定信息。由于学习到的策略值是离散且不可微的,我们使用了Gumbel-Softmax用于可微近似,因此可以通过标准反向传播对网络进行端到端训练。
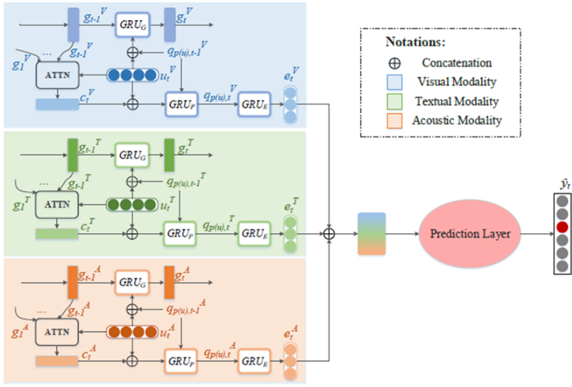
图2 网络结构
具体来说,我们为每个模态维护一个并行传播分支,其中子网络的结构相同,并且相应子模块的参数共享。每个子网络包含三个门控循环单元 (GRU),分别用于捕获上下文关系、说话者状态和情感动态(如图2所示)。在此基础上,应用了一种自适应策略确定哪些子模块(即GRU)在哪些模态中被保留或丢弃。另外我们制定了两个额外的损失函数来捕捉这种平衡。所有子模块的学习策略不仅可以视为模态级别的决策,还可以视为上下文级别的决策。即,每个学习到的策略值不仅决定在某个对话轮次中保留或丢弃不同模态的哪些信息,而且还决定何时在某模态的对话流中传播或遗忘哪些信息。因此,MetaDrop能够通过学习丢弃什么和何时丢弃来同时模拟多模态和上下文动态。在两个主流的多模态数据集IEMOCAP和MELD上进行的实验表明,MetaDrop的表现优于以前的方法。
表1 实验结果
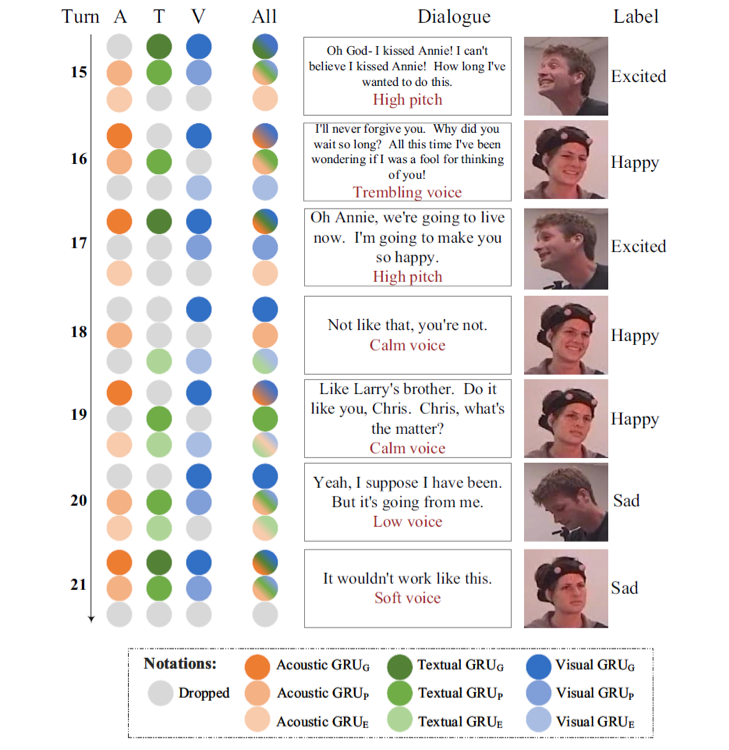
图3 策略可视化
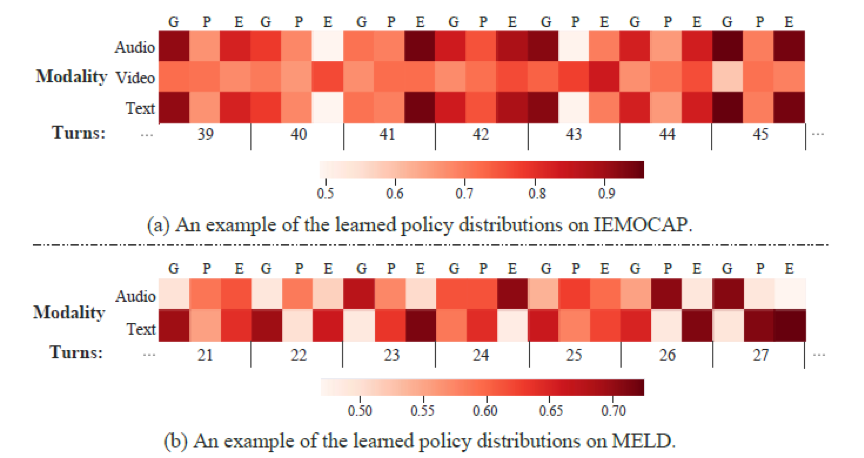
图4 决策概率可视化
06
Searching Motion Graphs for Human Motion Synthesis
作者:刘臣臣,穆亚东
单位:北京大学
邮箱:
liuchenchen@pku.edu.cn,
myd@pku.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475264
人体运动序列合成任务作为虚拟现实的关键技术之一,可以驱动人体骨骼模型,赋予虚拟智能体真实的人体运动效果,它可以用来辅助以人为中心的视频合成。人体运动序列合成,是指给定一段时间区间内三维空间中人体关节点的运动情况,合成未知的人体运动序列。现有的人体运动序列合成方法主要可以分为数据驱动运动图模型和生成模型两种。
我们提出了一种基于运动图(motion graph)和生成模型的统一运动序列合成框架,可以同时用于人体运动序列的前向预测以及补全。该框架的主要结果如图1所示,主要包括三个阶段:运动图的构建、过渡序列的生成以及运动序列的预测和补全。第一阶段从训练集中构建运动图,运动图中的节点对应于人体姿态,图中的边对应于人体运动序列。边的种类包括两种:同一序列内相邻节点的连接边以及不同序列节点之间的过渡转移边。该运动图能够编码同一序列内人体的运动状态以及不同序列之间的平滑转移。第二阶段是过渡转移序列的生成,在该阶段我们使用生成模型DCT-GCN来完成运动图中过渡转移边对应的运行信息生成。第三阶段做的是运动序列的预测和补全结果生成,我们设计了一种启发式的近似搜索算法,来进行运动图中任意两个节点之间的可行路径搜索,从路径中恢复出人体运动序列的补全或预测结果。
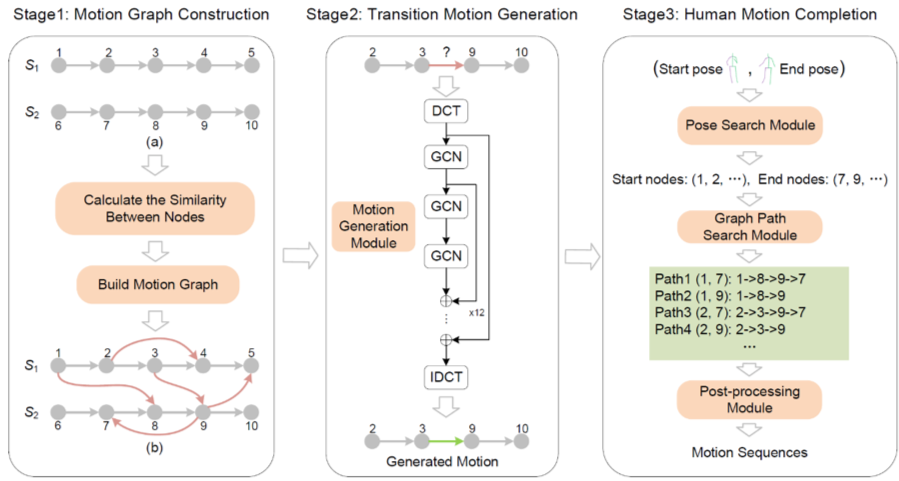
图1 人体运动序列合成任务的流程图
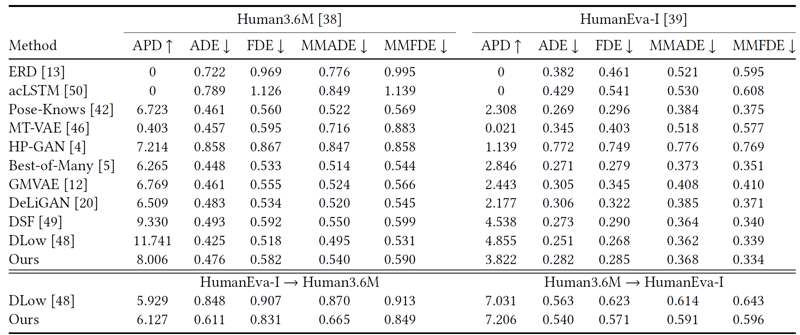
如表1和表2所示,我们在人体运动序列预测和运动序列补全两个任务上进行了实验评估。表1中显示了我们的方法在序列预测任务上达到了与当前效果最好工作相当的性能,在跨场景迁移的设定下,我们方法具有更强的泛化效果。表2中的结果显示我们方法在运动序列补全任务上的效果也要优于基线模型。
表1 人体运动序列预测结果
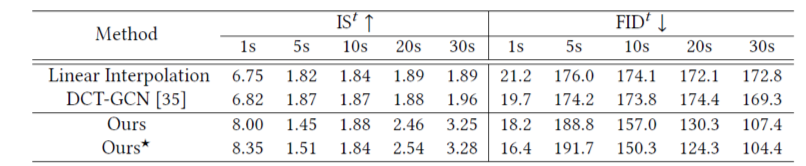
表2 人体运动序列补全实验结果

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜


