
【导读】计算机视觉顶会CVPR 2020在不久前公布了论文接收列表。本届CVPR共收到了6656篇有效投稿,接收1470篇,其接受率在逐年下降,今年接受率仅为22%。几周前专知小编整理了CVPR 2020 图神经网络(GNN)相关的比较有意思的值得阅读的,这期小编继续为大家奉上CVPR 2020五篇GNN相关论文供参考——视频文本检索、人体解析、图像描述生成、人脸重构、Human-Object Interaction。
CVPR2020GNN_Part1、WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
- Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning
作者:Shizhe Chen, Yida Zhao, Qin Jin and Qi Wu
摘要:随着视频在网络上的迅速涌现,视频和文本之间的跨模态检索越来越受到人们的关注。目前解决这一问题的主流方法是学习联合嵌入空间来度量跨模态相似性。然而,简单的联合嵌入不足以表示复杂的视觉和文本细节,例如场景、对象、动作及他们的组成。为了提高细粒度的视频文本检索,我们提出了一种分层图推理(HGR)模型,将视频文本匹配分解为全局到局部层次。具体地说,该模型将文本分解成层次化的语义图,包括事件、动作、实体这三个层次和这些层次之间的关系。利用基于属性的图推理生成层次化的文本嵌入,以指导多样化、层次化的视频表示学习。HGR模型聚合来自不同视频-文本级别的匹配,以捕捉全局和局部细节。在三个视频文本数据集上的实验结果表明了该模型的优越性。这种分层分解还可以更好地跨数据集进行泛化,并提高区分细粒度语义差异的能力。

网址:https://arxiv.org/abs/2003.00392
- Hierarchical Human Parsing with Typed Part-Relation Reasoning
作者:Wenguan Wang, Hailong Zhu, Jifeng Dai, Yanwei Pang, Jianbing Shen and Ling Shao
摘要:人体解析(Human parsing)是为了像素级的人类语义理解。由于人体是具有层次结构的,因此如何对人体结构进行建模是这个任务的中心主题。围绕这一点,我们试图同时探索深度图网络的表示能力和层次化的人类结构。在本文中,我们有以下两个贡献。首先,首次用三个不同的关系网络完整而精确地描述了分解、组合和依赖这三种部件关系。这与以前的解析方式形成了鲜明的对比,之前的解析器只关注关系的一部分,并采用类型不可知(type-agnostic)的关系建模策略。通过在关系网络中显式地施加参数来满足不同关系的具体特性,可以捕捉到更具表现力的关系信息。其次,以前的解析器在很大程度上忽略了循环的人类层次结构上的近似算法的需求,而我们则通过将具有边类型的通用信息传递网络与卷积网络同化来解决迭代推理过程。通过这些努力,我们的解析器为更复杂、更灵活的人际关系推理模式奠定了基础。在五个数据集上的综合实验表明,我们的解析器在每个数据集上都具有最好的表现。

网址:https://arxiv.org/abs/2003.04845
- Say As You Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
作者:Shizhe Chen, Qin Jin, Peng Wang and Qi Wu
摘要:人类能够随心所欲地用粗略到精细的细节来描述图像内容。然而,大多数图像描述生成模型都是忽略意图(intention-agnostic)的,不能根据不同的用户意图主动生成不同的描述。在这项工作中,我们提出了抽象场景图(ASG)结构来在细粒度层次上表示用户意图,并控制生成的描述应该是什么和有多详细。ASG是一个由三种类型的抽象节点(对象、属性、关系)组成的有向图,这些节点来自于图像,没有任何具体的语义标签。因此,啊他们通过手动或自动生成都很容易获得。在ASG的基础上,我们提出了一种新颖的ASG2图像描述生成模型,该模型能够识别用户在图中的意图和语义,从而根据图的结构生成想要的字幕。与在VisualGenome和MSCOCO数据集上的其它的基线模型相比,我们的模型在ASG上具有更好的可控性条件。它还通过自动采样不同的ASG作为控制信号,显著提高了caption的多样性。
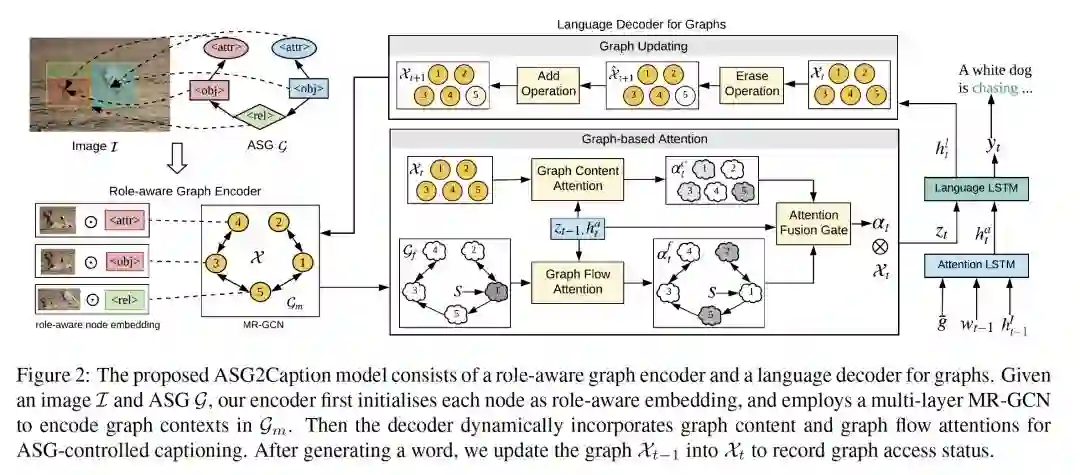
网址:https://arxiv.org/abs/2003.00387
- Towards High-Fidelity 3D Face Reconstruction from In-the-Wild Images Using Graph Convolutional Networks
作者:Jiangke Lin, Yi Yuan, Tianjia Shao and Kun Zhou
摘要:基于三维形变模型(3DMM)的方法在从单视图图像中恢复三维人脸形状方面取得了很大的成功。然而,用这种方法恢复的面部纹理缺乏像输入图像中表现出的逼真度。最近的工作采用生成网络来恢复高质量的面部纹理,这些网络是从一个大规模的高分辨率脸部纹理UV图数据库中训练出来的,这些数据库很难准备的,也不能公开使用。本文介绍了一种在无约束条件下捕获(in-the-wild)的单视图像中重建具有高保真纹理的三维人脸形状的方法,该方法不需要获取大规模的人脸纹理数据库。为此,我们提出使用图卷积网络来重建网格顶点的细节颜色来代替重建UV地图。实验表明,我们的方法可以产生高质量的结果,并且在定性和定量比较方面都优于最先进的方法。

网址:https://arxiv.org/abs/2003.05653
- VSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
作者:Oytun Ulutan, A S M Iftekhar and B. S. Manjunath
摘要:全面的视觉理解要求检测框架能够在单独分析物体的同时有效地学习和利用物体交互。这是人类-物体交互(Human-Object Interaction,HOI)任务的主要目标。特别是,物体之间的相对空间推理和结构联系是分析交互的基本线索,文中提出的视觉-空间-图网络(VSGNet)体系结构可以解决这一问题。VSGNet从人类-物体对中提取视觉特征,利用人类-物体对的空间构型对特征进行细化,并通过图卷积利用人类-物体对之间的结构联系。我们使用COCO(V-COCO)和HICO-Det数据集中的动词对VSGNet的性能进行了全面评估。实验结果表明,VSGNet在V-COCO和HICO-DET中的性能分别比现有解决方案高出8%或4MAP和16%或3MAP。



