
说话人合成任务旨在根据输入的音频以及目标人物的脸像,合成形象的面部动作与逼真的视频。该任务主要存在两个困难: (1) 如何建模多风格的、形象的音频到面部动作映射。(2) 如何根据目标人物的图像渲染出逼真的视频。为了解决这两个问题,我们 (1) 定义了连续的风格空间编码,根据该编码合成音频同步的说话动作。(2) 实现了one-shot deferred neural render,给定单张人脸,不用任何fine-tune,即可控制该人脸的3D表情、姿态,并且渲染为真实2D图像。下面我们分别介绍这两部分的实现。
首先,来谈一谈多风格唇形合成。对于风格化的唇形合成,之前的方法往往是one-shot的,例如VOCA。然而,在现实中,显然一个人也有可能有多种不同的talking风格。如果在wild的数据中,我们对于每个人强制的用one-shot,就有可能导致最终合成的style被平滑掉。为了解决这一问题,我们用了图像风格迁移中类似gram matrix的思路,在一段面部动作序列(3DMM参数序列)中,寻找与风格强相关的连续性统计量,将这一连续性统计量fuse到音频到面部动作参数的预测模型中,达到风格控制的效果。通过这样的方式,我们甚至可以模仿任意的说话风格。那么接下来的问题就是,如何找到这样一个统计量?如何在audio2motion的模型中做fuse?
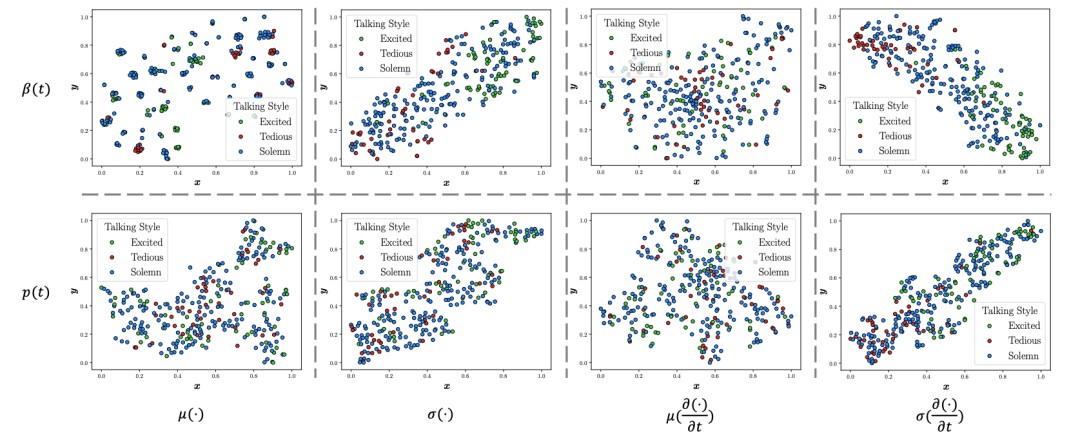
为了找到这样一个统计量,我们做了大量的statistical study,发现风格与表情序列的方差、表情序列差分的方差,姿态序列差分的方差密切相关。因此我们将控制风格的连续性统计量定义如下:
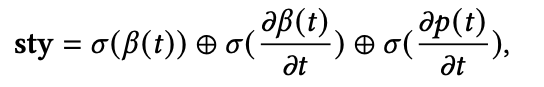
其中beta是表情,p是姿态,sigma是标准差。有了这样的sty code,接下来的问题就是怎么将style融入到audio2motion的模型中。我们尝试了很多方案,比如adain,但是方案都没有最简单的在resnet1D的中间层将隐层音频特征与sty融合效果好,因此最后采用了最简单的方案: 直接把隐层音频特征的每一帧和sty拼接,如下图所示。
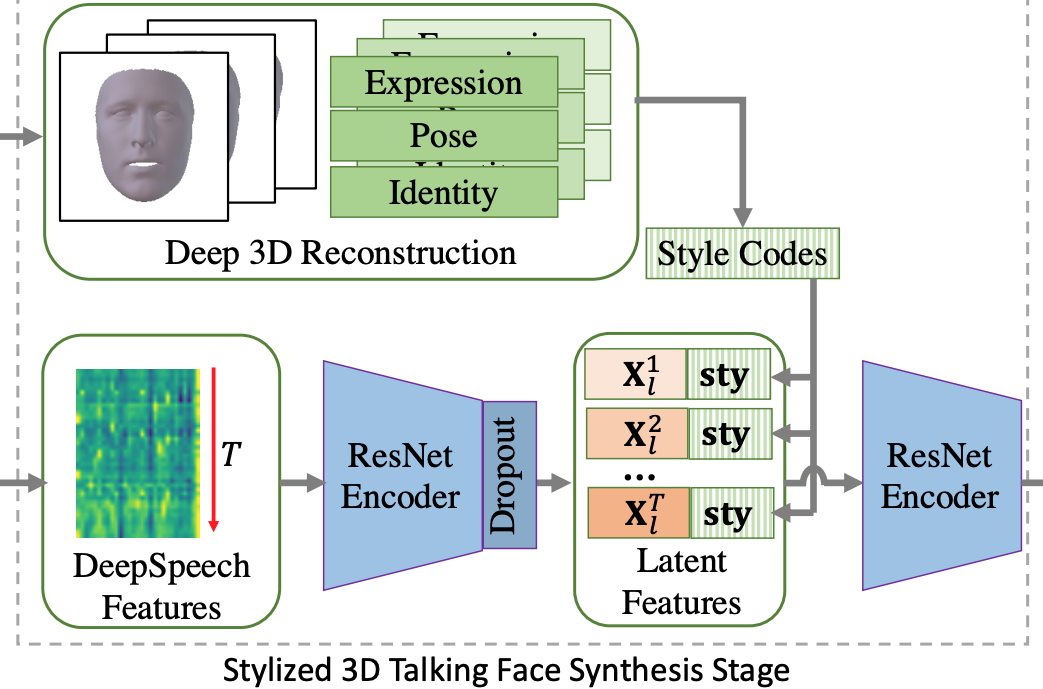
通过这样的方式我们得到了风格化的唇形动作序列,接下来就是one-shot渲染的问题。
我们参考了neural voice puppetry中deferred neural render的方案,用神经纹理+UV纹理采样+图像迁移的方式做渲染。但是,deferred neural render需要2-3分钟的视频训练神经纹理,我们则训练了一个texture encoder从单张图片合成纹理。在具体实现中,我们从RGB图像以及单目的重建结果中unwrap出RGB纹理,随后用UNet从RGB纹理中合成神经纹理,再将神经纹理输入到后续神经渲染的流程中。通过这样的方式,我们在单张图像上实现了姿态、表情的控制。具体如下图:
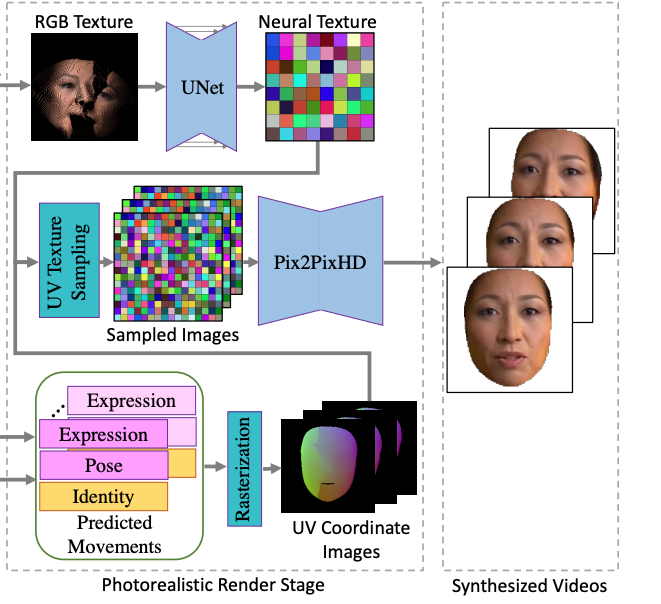
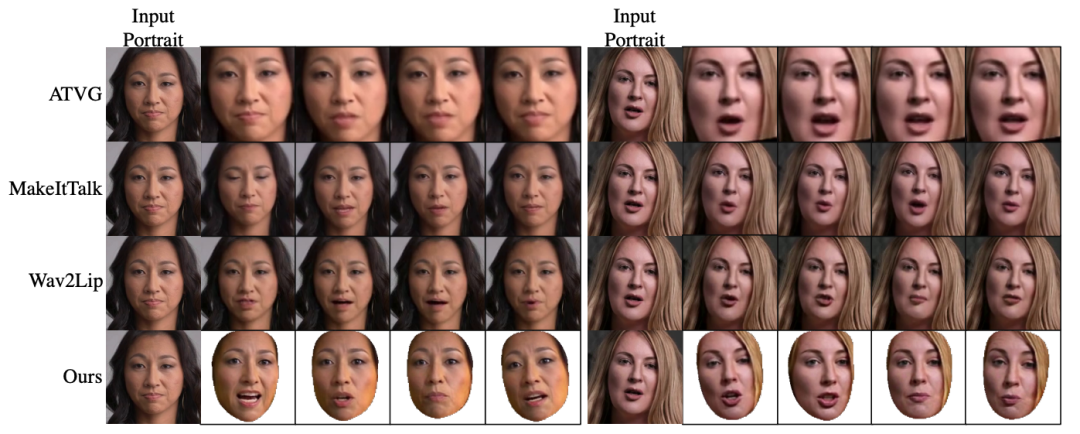
这一部分的训练是在LRW数据集上端到端训练的,对unseen的identity有很好的泛化能力,我们在开源的code中给出了一个one-shot合成的结果。这里也给了一些比较结果:
作者:吴昊哲1,贾珈1,王浩宇1,窦义顺2,段超2,邓清珊2
单位:1清华大学,2华为
邮箱:
wang-hy18@mails.tsinghua.edu.cn,
论文:
https://arxiv.org/abs/2111.00203
代码:
https://github.com/wuhaozhe/style_avatar
demo视频:

