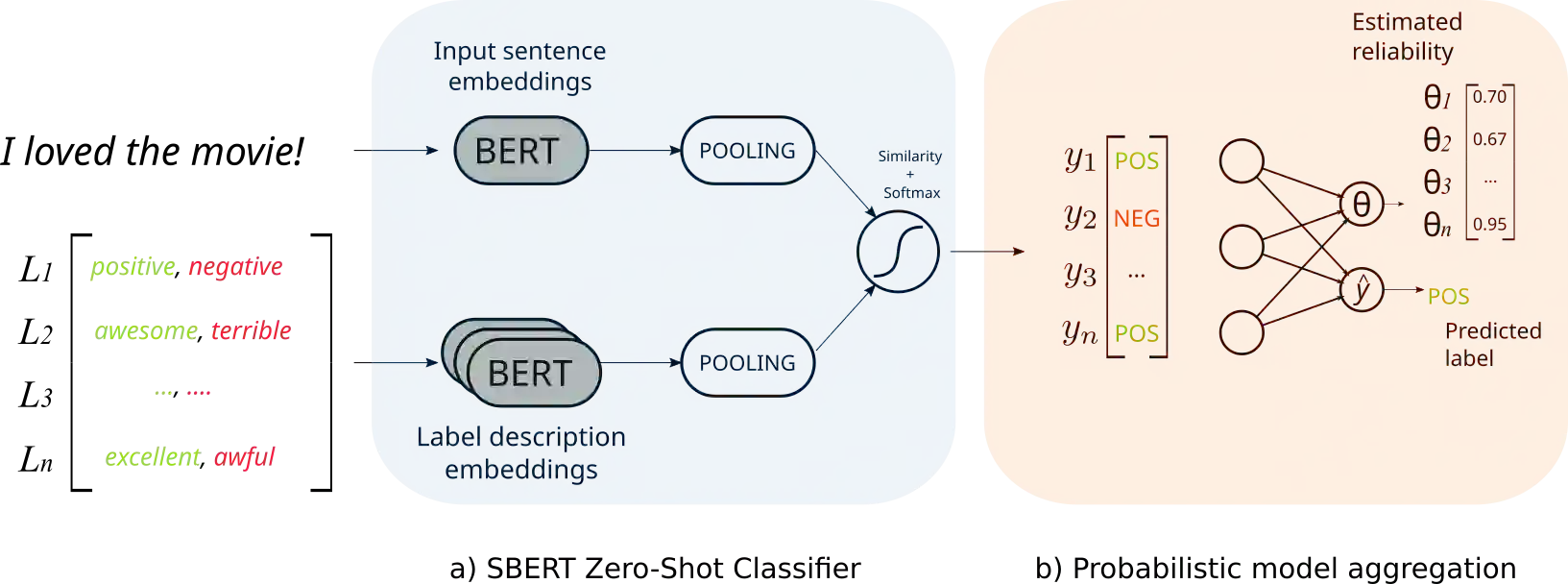
Zero-shot text classifiers based on label descriptions embed an input text and a set of labels into the same space: measures such as cosine similarity can then be used to select the most similar label description to the input text as the predicted label. In a true zero-shot setup, designing good label descriptions is challenging because no development set is available. Inspired by the literature on Learning with Disagreements, we look at how probabilistic models of repeated rating analysis can be used for selecting the best label descriptions in an unsupervised fashion. We evaluate our method on a set of diverse datasets and tasks (sentiment, topic and stance). Furthermore, we show that multiple, noisy label descriptions can be aggregated to boost the performance.
翻译:基于标签说明的零光文本分类基于将输入文本和一组标签嵌入同一空间的标签说明的零光文本分类:随后,可使用诸如粘贴相似性等措施选择与输入文本最相似的标签说明作为预测的标签。在真正的零点设置中,设计良好的标签说明具有挑战性,因为没有开发集。根据关于学习和分歧的文献,我们研究如何使用反复评级分析的概率模型,以不受监督的方式选择最佳的标签说明。我们评估了一套不同的数据集和任务(提示、主题和姿态)的方法。此外,我们显示,可以将多个、吵闹的标签说明汇总起来,以提升性能。