【论文导读】2021年论文导读第二十四期


论文导读
2021年论文导读第二十四期(总第四十期)
目 录
|
1 |
Multi-Interactive Dual-Decoder for RGB-Thermal Salient Object Detection |
|
2 |
End-to-End Light Field Spatial Super-Resolution Network Using Multiple Epipolar Geometry |
|
3 |
Unsupervised Deep Image Stitching: Reconstructing Stitched Features to Images |
|
4 |
Structure-Aware Motion Deblurring Using Multi-Adversarial Optimized CycleGAN |
|
5 |
Reasoning Graph Networks for Kinship Verification: From Star-Shaped to Hierarchical |
|
6 |
COAST: COntrollable Arbitrary-Sampling NeTwork for Compressive Sensing |
|
7 |
Multi-view Face Synthesis via Progressive Face Flow |
|
8 |
SADRNet: Self-Aligned Dual Face Regression Networks for Robust 3D Dense Face Alignment and Reconstruction |
01
Multi-Interactive Dual-Decoder for RGB-Thermal Salient Object Detection
用于可见光-热红外显著目标检测的多交互式双解码器
作者:涂铮铮,李准,李成龙,郎洋,汤进
单位:多模态认知计算安徽省重点实验室(安徽大学),安徽大学计算机科学与技术学院
邮箱:
zhengzhengahu@163.com;
lizhun118@foxmail.com;
lcl1314@foxmail.com;
m13856258456@163.com;
tangjin@ahu.edu.cn.
论文:
https://ieeexplore.ieee.org/document/9454273
代码:
https://github.com/tzz-ahu/Multi-interactive-Dual-decoder
文中三个数据集链接:
VT821:https://pan.baidu.com/s/1ksuUr3cr6_-fZAsSUp0n0w [9yqv]
VT1000:https://pan.baidu.com/s/1i7gfrHoaaRuateMXBxvmMw [tb6l]
VT5000:https://pan.baidu.com/s/13_9tJXHDmWLNjqkbMNl1hw [likp]
可见光-热红外(RGBT)显著目标检测旨在检测出可见光-热红外图像对中的共同的显著目标。鲁棒的RGBT显著目标检测方法依赖于不同模态之间的信息互补以及单模态内有效信息的聚合。然而,已有的方法往往只专注于研究这两个解决方案之一,无法结合多类型线索推断共同的显著目标。本文提出一种多交互的双重解码器网络,在解码过程中实现多类型线索结合的显著目标检测,即通过多模态信息、多层级信息和全局信息之间的交互,以双重解码的方式实现了更精确的显著目标检测。
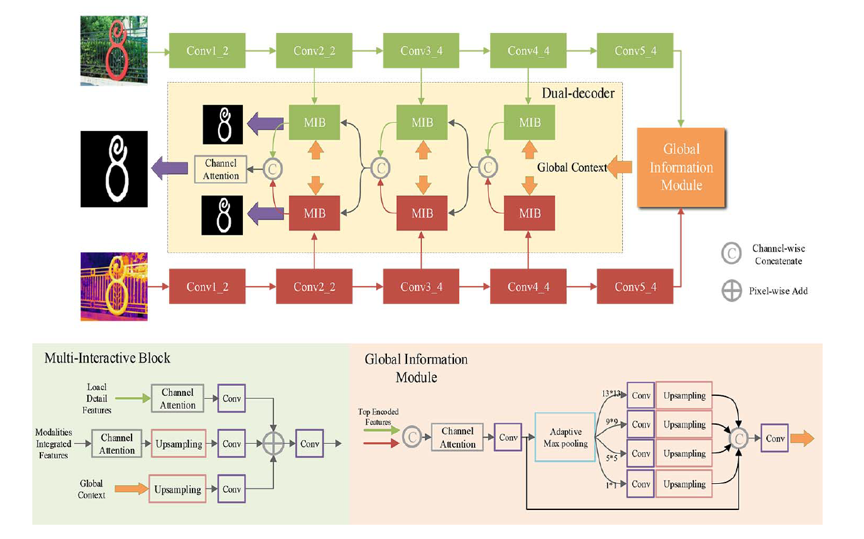
图1 网络框架
图1展示了本文的网络框架。首先,我们从编码器解码器架构入手,受现有多模态显著目标检测网络的启发,考虑到中期融合和后期融合策略各自的优势,我们结合这两种策略设计解码器,并使用两个独立的编码器编码,最大化地利用两个模态的信息。本文网络将两个模态信息的交互过程嵌入到解码流程中去,并结合全局上下文信息渐进式地加入多级编码特征,确保两个模态中的各种信息的交互都能被网络学习。其次,考虑到模态偏置的问题,本文中两个模态特定的解码器分别处理各自模态的信息,用这两个解码器各自的输出特征预测显著图,并使用相同的真值监督。受益于解码过程中的信息多交互和监督学习,多模态信息互补和模态显著性偏置的问题都能得到解决。
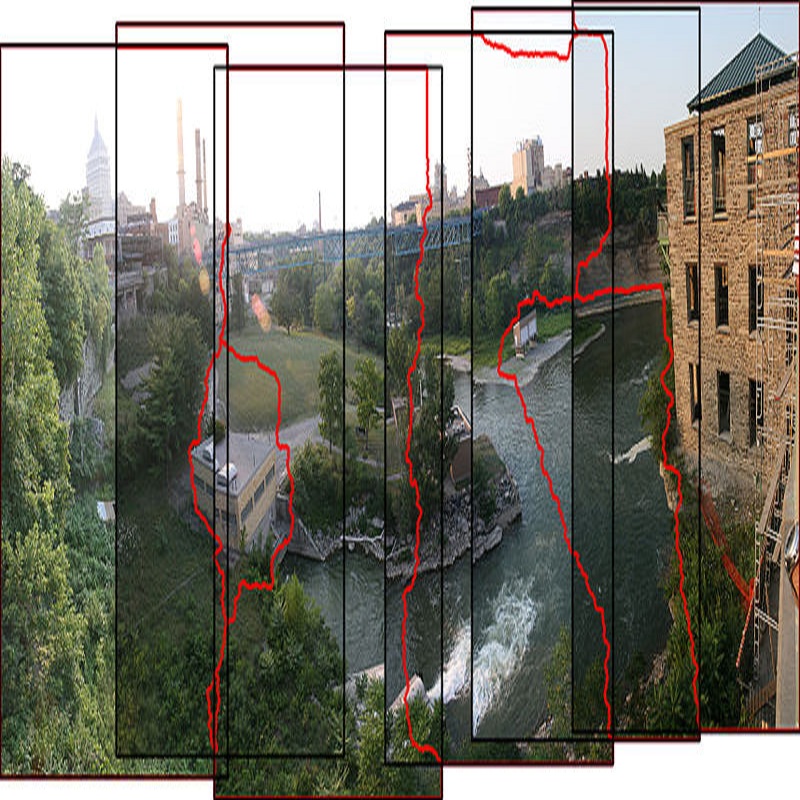
对某个模态失效或者含有太多噪声的情况,为了让本文的双重解码器更加鲁棒,我们提出了一种数据增强方案,即通过随机使用正态分布采样的噪声图或者零值图将一个模态替代,用这样一个有较多数据噪声的训练集训练本文的网络,所以若要获得优良的结果,网络就只能依赖双重解码器之间的多交互过程。通过这种方式,网络就能适应模态失效或包含大量噪声的情形,充分探索模态信息的互补并且抑制掉输入的无用信息。如图2所示(第一行是可见光图像,第二行是热红外图像,第三行是本文方法检测到的显著目标),可见,对于这些难度较大的样本,本文方法依然能够得到较为准确的结果。

图2 本文方法显著目标检测结果举例
表1是本文方法与12个对比方法在现有的三个数据集和五个评价指标上的性能表现,图3是PR曲线和F-measure曲线,实验结果表明,和其他先进的对比方法相比,总的来说,本文的方法取得了更好的效果。
表1 本文方法与12个对比方法在现有的三个数据集上的对比实验
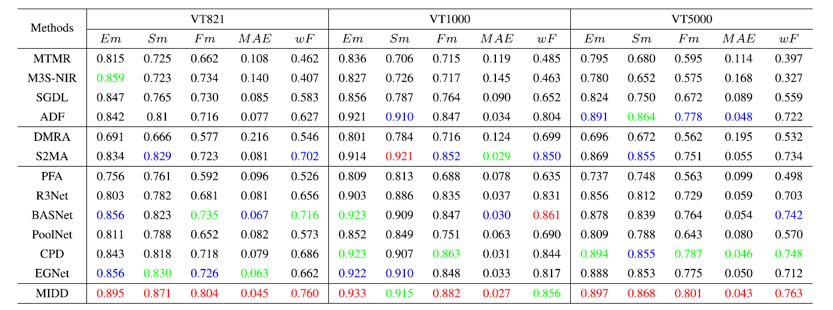
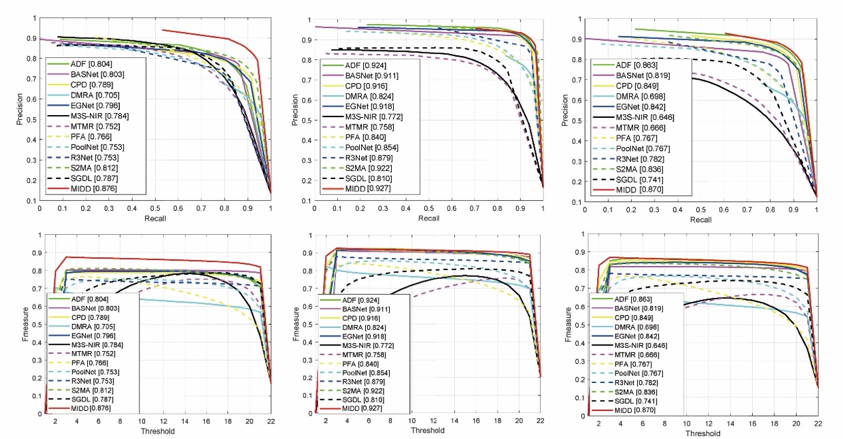
图3 PR曲线和F-measure曲线

02
End-to-End Light Field Spatial Super-Resolution Network Using Multiple Epipolar Geometry
基于多极线几何特征的端对端光场空间超分辨网络
作者:张硕、常松、林友芳
单位:北京交通大学 计算机与信息技术学院 交通数据分析与挖掘北京市重点实验室
邮箱:
zhangshuo@bjtu.edu.cn
changsong@bjtu.edu.cn
yflin@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9465683
代码:
https://github.com/shuozh/MEG-Net
由于光场相机可以同时捕获角度和空间信息,基于光场图像的应用越来越丰富。然而,有限的空间分辨率给相关应用的开发带来了很多困难,成为光场相机的主要瓶颈。在本文中,提出了一种端到端学习的方法,利用光场图像的对极几何特性,同时超分辨光场图像中所有的视角图像。

图1 深度学习模型的预测与输入图像的质量水平的关系
由于光场图像在角度域中的采样是稠密的,因此不同空间方向的亚像素细节能分别从相应的角度方向上获取。从极平面图像的角度可以直观的说明该原理。其中,任意一个像素点对应的极平面图像可以来自四个不同的角度方向。因此对于光场图像中的每个像素点,四个特定方向的极平面图像包含了四个方向的亚像素信息。
因此,本文设计了一个端到端的光场超分辨网络模型,如图2所示。一个光场图像中的视角图像首先被按照不同的方向进行堆叠,形成不同的图像堆栈,进一步采用不同的卷积神经网络分支以学习每个视角图像的在该方向上的亚像素细节信息。然后通过进一步整合来自不同方向的亚像素细节以生成全局高频残差细节,最终得到具有高空间分辨率的光场图像。
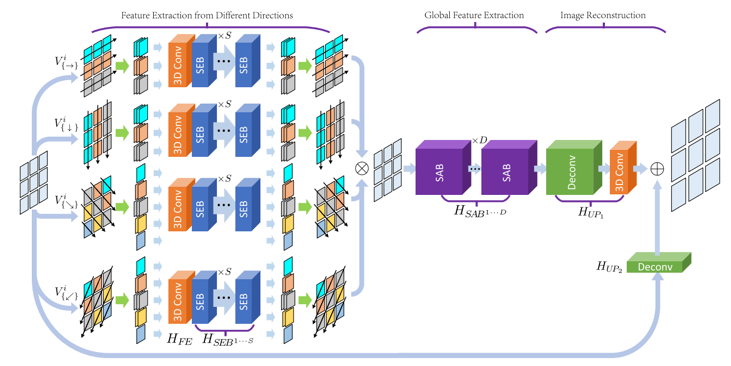
图2 网络模型结构
表 1 所提出的方法与其他方法的结果对比(7×7与3×3角分辨率,3倍与4倍上采样任务)
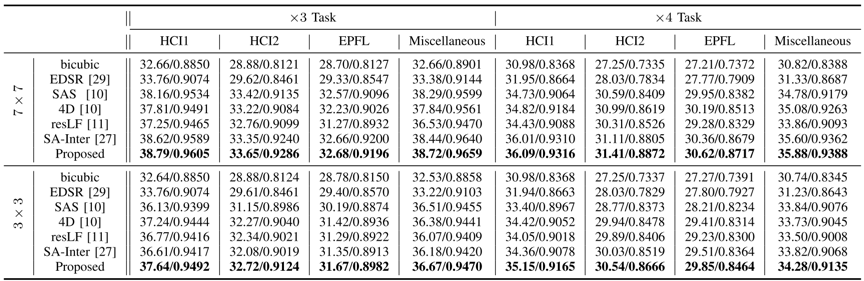
在合成和真实世界的光场图像数据集的实验结果表明,所提出的方法都优于其他最先进的方法,如表1所示。同时,该方法能够适应光场图像角度分辨率的变化,特别是对于角分辨率较小的光场图像,相比于其他方法取得了更好的结果。此外,该方法在保留光场图像固有的对极特性方面也表现出良好的性能。
03
Unsupervised Deep Image Stitching: Reconstructing Stitched Features to Images
首个无监督深度学习图像拼接工作
作者:聂浪1,林春雨1,廖康1,刘帅成2,赵耀1
单位:1信息科学研究所 北京交通大学, 2电子科技大学
邮箱:
nielang@bjtu.edu.cn,
cylin@bjtu.edu.cn,
kang_liao@bjtu.edu.cn,
liushuaicheng@uestc.edu.cn,
yzhao@bjtu.edu.cn
论文:
https://ieeexplore.ieee.org/document/9472883
代码及数据集:
https://github.com/nie-lang/UnsupervisedDeepImageStitching
论文介绍网页:
https://zhuanlan.zhihu.com/p/386863945
1 引言
传统的基于手工特征点(如SIFT、ORB等)的图像拼接方法严重依赖于特征点的检测质量,往往在低纹理,低光照或重复纹理等场景下失败。而现有的深度学习拼接方案很少研究,其原因是拼接图的ground truth难以获得。
为了解决以上两个问题,本文提出了一种基于重建的无监督图像拼接方案。其重建的核心思想来自于一个观察:像素级的不对齐现象可以在特征级上被一定程度削弱。因此,我们认为:重建拼接特征比重建像素级拼接图更容易,随后拼接特征可以用来重建出拼接图。如下图从左至右依次展示了:1)像素不对齐2)特征不对齐3)重建的特征4)重建的拼接图。

图1 研究动机
2 无监督拼接
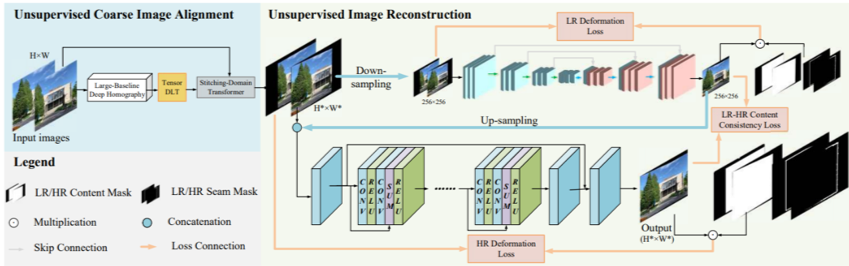
图2 网络框架
如上图,整个无监督拼接方案可以分为两个阶段:无监督粗对齐和无监督重建。第一个阶段估计一个全局homography来粗对齐输入图像,第二阶段重建粗对齐的结果得到拼接图。
在无监督重建阶段中,我设计了一个低分辨率重建分支和一个高分辨率优化分支,分别用来消除伪影和增强图像分辨率。
在重建阶段,我们提出了一个内容约束和一个缝隙约束来引导重建和优化过程的学习。我们可视化了低分辨率分支重建过程的feature maps:网络会优先在encoder阶段重建重叠区域的特征,然后在decoder阶段恢复非重叠区域,最后重建出像素级的拼接图。

图3 低分辨率重建过程可视化
3 数据集UDIS-D
为了训练该网络,我们提出了一个无监督图像拼接数据集(USIS-D)。该数据集包含了不同重叠率,不同的视差和不同的场景。训练集共10,440对图像,测试集包含1,106对图像。
4 实验
本文分别在homography估计任务和图像拼接任务上进行了定量和定性的评估。甚至与现有的有监督的深度学习图像拼接算法相比,我们的方法实现了更好的拼接结果。消融实验结果也证明了本文设计的不同模块的有效性。
下图展示了一个极端的例子,传统方法在低纹理场景下(低分辨率,低光照,部分医学图像)由于特征检测或匹配的失败,无法鲁棒地拼接,而我们的方法却可以鲁棒地提取深度语义特征,从而进行有效地拼接。

图4 低纹理场景下:传统方法 vs. learning 方法
04
Structure-Aware Motion Deblurring Using Multi-Adversarial Optimized CycleGAN
作者:温阳1,陈洁2,盛斌1,*,陈志华3,李平4,谭平5,李同益6
单位:1上海交通大学,2三星中国研究院(南京),3华东理工大学,4香港理工大学,5西蒙菲莎大学,6国立成功大学
邮箱:
wenyang@sjtu.edu.cn;
ada.chen@samsung.com;
shengbin@sjtu.edu.cn;
czh@ecust.edu.cn;
p.li@polyu.edu.hk;
pingtan@sfu.ca;
tonylee@mail.ncku.edu.tw
论文:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9472928
*通讯作者
图像去模糊的主要目的是将一幅质量退化的模糊图像重建为更符合视觉感知的清晰图像,在图像复原中具有重要作用。为解决以往盲图像去运动模糊方法对大量成对训练数据的严格需求及模糊核估计过程中不可避免地产生误差的问题,提出一种基于结构保持的多对抗图像去运动模糊方法实现盲图像去运动模糊。首先提出基于循环一致生成对抗网络来解决盲图像去运动模糊问题。然后,提出一种多对抗网络结构来解决高分辨率图像生成中的伪影问题,通过多对抗约束可以促进网络在不同分辨率上尽可能地生成对应的清晰图像。此外,通过引入结构感知机制来解决原始无监督方法中结构内容丢失的问题,将边缘图作为引导信息并引入多尺度的边缘约束条件,可以增强多对抗网络的结构和细节保持能力,从而提升去运动模糊的复原效果。多个基准数据集上的定量和定性实验结果表明,所提出的无监督去模糊方法优于当前领先的无监督和有监督图像去运动模糊方法。
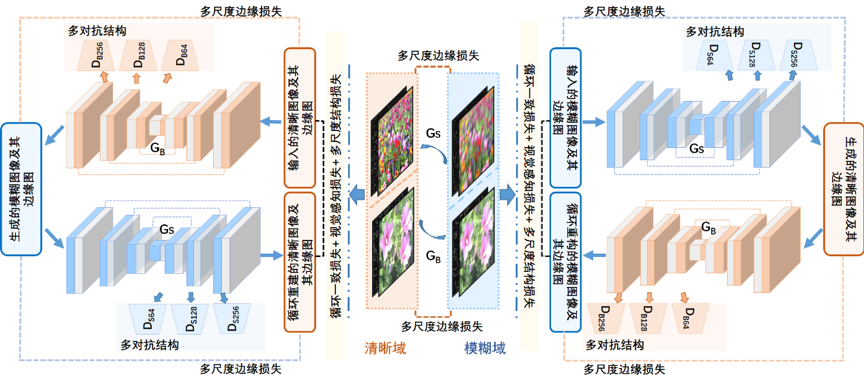
图1 基于结构感知和多对抗优化的 CycleGAN 结构流程图
所提出的无监督图像去运动模糊方法的整体流程图如图1所示。𝐺𝐵和 𝐺𝑆是两个生成器子网络,分别将清晰图像转换为模糊图像和将模糊图像转换为清晰图像。𝐷𝐵和𝐷𝑆是判别器,用于区分真实图像和生成图像并反向为生成器提供反馈信息。与原始CycleGAN不同,本文作者采用不同分辨率约束下的多对抗形式来逐步提高生成图像的质量,并利用跳跃连接将底层信息更好地传递到高层网络结构。同时,本文作者设计了一种结构感知机制,即在多对抗架构中引入多尺度边缘约束,使生成对抗网络在不同分辨率下能生成丰富的结构信息,同时边缘图也作为网络的部分输入促进网络对结构信息的保持。此外,本文作者引入了多种损失函数(多尺度结构损失函数MS-SSIM和基于VGG16网络的感知损失函数)来进一步加强约束以减少生成的虚假信息。与其他方法相比,本文方法不仅可以克服对成对训练数据的需求问题,而且可以保留更多的结构信息,获得更好的盲图像去运动模糊效果。
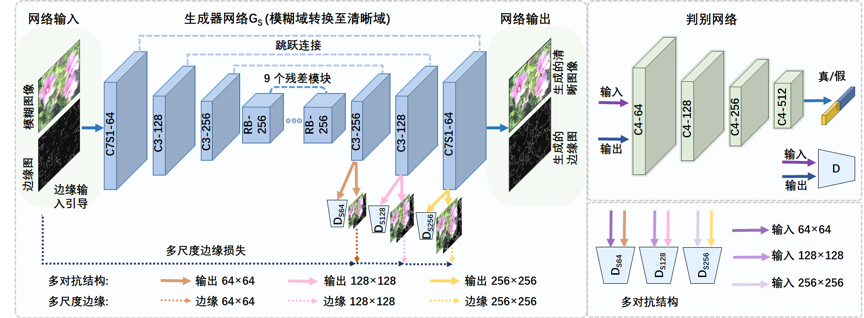
图2 提出的多对抗生成器网络结构
所提出的多对抗生成器网络结构如图2所示。𝐺𝑆是生成器子网络,用于将模糊图像转换为清晰图像。𝐺𝑆的输入是模糊图像和由Sobel算子提取的对应边缘图。通过多对抗方式,𝐺𝑆可以生成三种不同分辨率的输出。判别器𝐷𝑆64、𝐷𝑆128、𝐷𝑆256分别针对三种不同分辨率。
表1~表3展示了所提出方法和当前领先的去模糊方法的定量结果对比。结果显示所提出方法在文本图像、人脸图像、GoPro运动图像及真实图像多个数据集上的去模糊性能明显优于其他最先进的有监督和无监督去模糊方法。
表 1 BMVC_TEXT 和 Face 数据集上的平均 PSNR 和 SSIM

表 2 GoPro 数据集上的平均 PSNR 和 SSIM
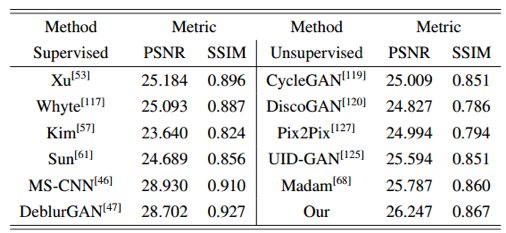
表 3 真实数据集上的去模糊性能的平均主观评价分数

05
Reasoning Graph Networks for Kinship Verification: From Star-Shaped to Hierarchical
基于推理图网络的亲属关系验证:从星状到层次化结构
作者:李万华1,鲁继文1,吾尔开希·阿布都克力木1,冯建江1,周杰1*
单位:1清华大学自动化系
邮箱:
li-wh17@mails.tsinghua.edu.cn
lujiwen@tsinghua.edu.cn
wekxabdk17@mails.tsinghua.edu.cn
jfeng@tsinghua.edu.cn
jzhou@tsinghua.edu.cn
论文:
https://ieeexplore.ieee.org/document/9426411
*通讯作者
亲属关系验证致力于对于给定的两张图片判别两者之间是否存在血缘关系。通常来说,亲属关系验证有两个主要的阶段:人脸表示和人脸匹配。人脸表示旨在对每张人脸图片提取有判别力的特征,人脸匹配则致力于设计一个模型来融合两个提取的图片特征并预测它们两者之间的基因关系。传统的方法大多聚焦于如何为每一张人脸图片提取有判别力的特征。然而这些方法都忽视了如何对于获得的两个人脸图片特征进行融合并推理它们之间的关系。
本文聚焦于人脸匹配阶段并研究如何对比并融合两个人脸图片特征来推断它们之间的基因关系。人类可以首先对个体的一些生物特征比如眼睛颜色,鼻子大小等进行对比,然后根据这些对比结果进行综合分析来判断亲属关系。受此启发,我们可以首先逐维度地进行特征对比,然后将这些对比结果融合起来做出最终的判断。论文首先提出了星状结构推理图网络,其对两个提取的人脸图片特征构建一个星状图,然后在这个图上进行关系推理。由于星状结构的推理图使用了一个中间节点作为信息沟通的桥梁,这会限制模型的推理能力和灵活性。因此我们进一步提出了层次化推理图网络,其引入了一系列隐节点来构建一个层次化的推理图。我们使用逐层地信息传播机制来抽象和分析两个特征的对比信息。图1为本方法的框架图。
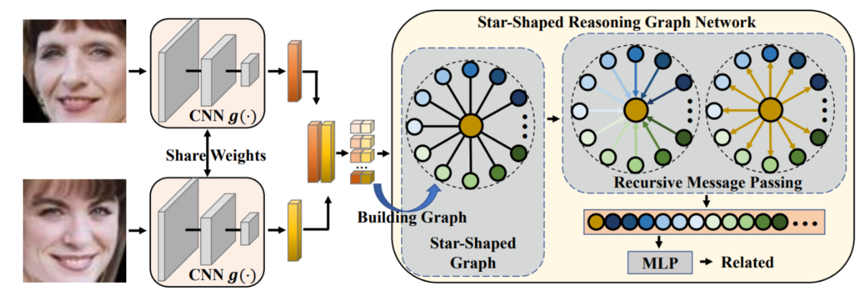
图 1 基于星状结构推理图网络的亲属关系验证框架图
融合之后的特征通过MLP映射为预测结果。我们使用二元交叉熵函数来训练我们的网络。我们首先在KinFaceW-I和KinFaceW-II数据集上进行了实验。实验结果如图2所示。我们的方法相比基线方法有显著的性能提升,而且也取得了目前最优的性能。此外,我们的方法还适用于三元亲属关系识别任务,图3展示了我们的方法在三元亲属关系数据集TSKinFace上的结果,结果展示我们的方法取得了优异的性能。
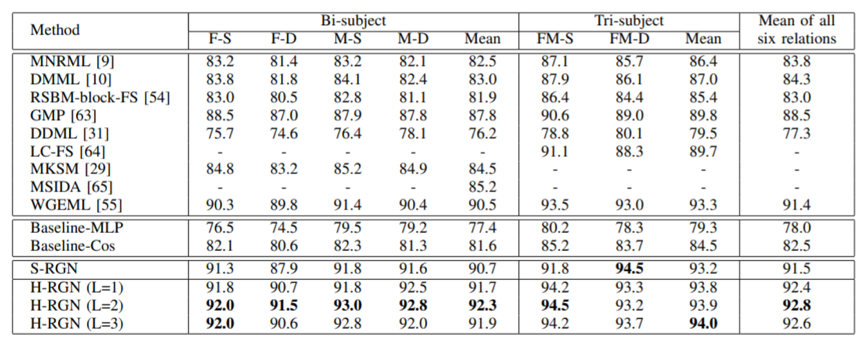
表2 在KinFaceW-I和KinFaceW-II数据集上与其他方法的性能对比
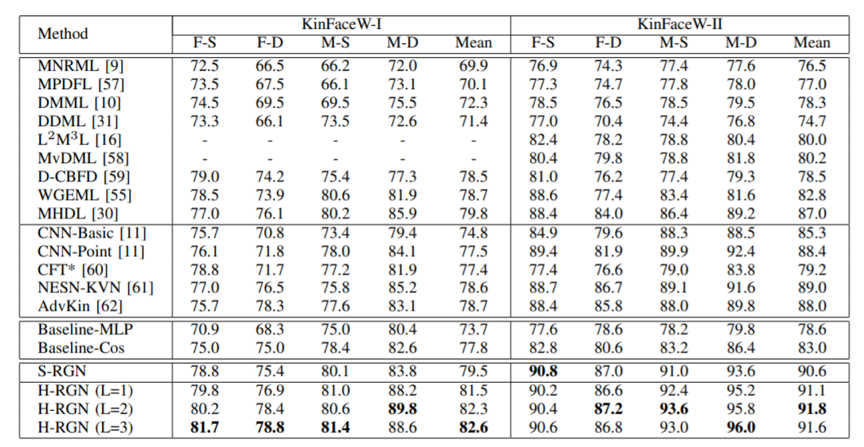
表3 在TSKinFace数据集上与其他方法的性能对比
06
COAST: COntrollable Arbitrary-Sampling NeTwork for Compressive Sensing
作者:由迪,张健,谢静芬,陈斌,马思伟
单位:北京大学
邮箱:
diyou@pku.edu.cn
zhangjian.sz@pku.edu.cn
xiejf@stu.pku.edu.cn
chenbin@stu.pku.edu.cn
swma@pku.edu.cn
论文:
https://ieeexplore.ieee.org/abstract/document/9467810
https://arxiv.org/abs/2107.07225
代码:
https://villa.jianzhang.tech/
https://github.com/jianzhangcs/COAST
作为一个典型的逆问题,压缩感知(Compressive Sensing, CS)旨在从线性随机投影获得的少量测量值中恢复未知的自然信号。最近基于深度网络的CS方法已经取得了巨大的成功。然而,它们大多数将不同的采样矩阵视为不同的任务,需要为每个采样矩阵训练一个特定的模型。这种做法会导致计算效率低下,泛化能力差。
针对以上问题,本文提出了可控制的任意采样网络(COntrollable Arbitrary-Sampling neTwork, COAST)。主要贡献点包括:
1、我们提出的用于CS任务的COAST,能够用一个单一的模型处理任意采样。
2、我们开发了随机投影增强(Random Projection Augmentation, RPA)策略,以促进网络的泛化能力和性能,它也可以直接融入到现有的基于深度网络的CS方法中。
3、我们进一步提出了一个可控的近端映射模块(Controllable Proximal Mapping Module, CPMM)和一个即插即用的去块效应(Plug-and-Play Deblocking, PnP-D)策略,以进一步改善鲁棒性、提高重建质量。
4、我们提出的COAST通过一个单一的模型实现了对任意采样矩阵的最先进的性能,促进了在现实世界CS系统中的应用。
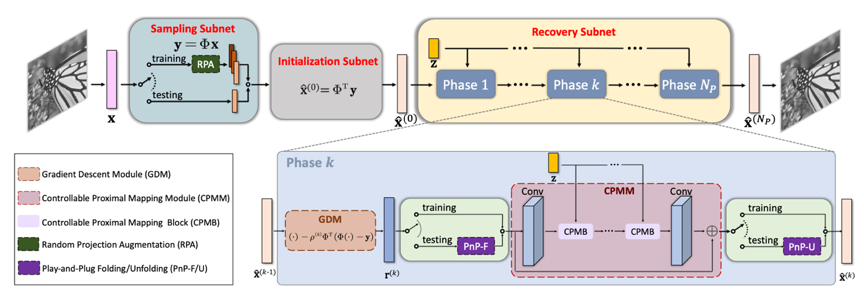
图1 COAST模型结构框架
方法简介:图1为COAST的结构框架。具体来说,该模型由三部分组成:采样子网络、初始化子网络和重建子网络。采样子网络模拟数据获取过程,并通过在对采样矩阵的增广,即RPA策略,提升训练数据在采样空间的多样性。初始化子网络是用于处理原始图像和测量值之间的维度不匹配问题。而重建子网络,是将传统的基于优化的迭代收缩阈值算法(Iterative Shrinkage-Thresholding Algorithm, ISTA)映射到深度网络中。该子网络由阶段组成,每个阶段由GDM和CPMM组成,它们对应于传统ISTA的两步更新。此外,在CPMM的前端和后端,我们在网络测试阶段加入了即插即用的PnP-D策略。
实验结果:我们在BSD68、Set11等数据集上做了定量和定性对比实验,结果表明COAST用一个模型在多个采样矩阵上取得了最优性能。
表1 在Set11、BSD68数据集上一些先进CS方法与COAST的平均PSNR性能比较
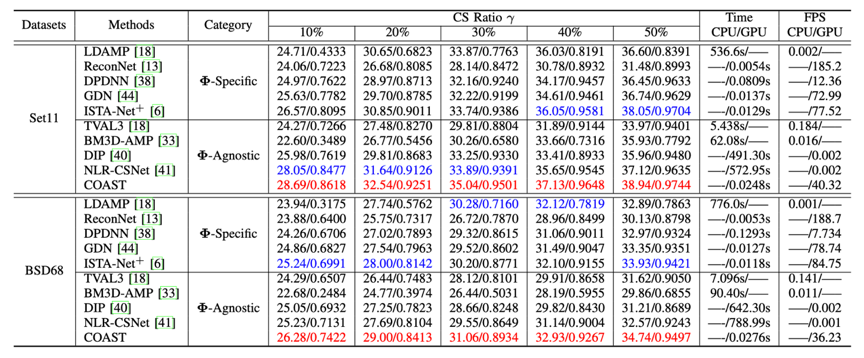

图2 一些先进CS方法与COAST在Set11上的视觉比较

图3 一些先进CS方法与COAST在BSD68上的视觉比较
07
Multi-view Face Synthesis via Progressive Face Flow
作者:徐洋洋1,徐雪妙1,焦建波2,李可可1,徐成1,何盛烽1
单位:1华南理工大学,2剑桥大学
邮箱:
cnnlstm@gmail.com
xuemx@scut.edu.cn
cslikeke@mail.scut.edu.cn
cschengxu@gmail.com
hesfe@scut.edu.cn
论文:
https://ieeexplore.ieee.org/document/9466401
人脸识别是计算视觉领域的重要研究课题,近些年来,随着大规模数据集的出现和深度神经网络的发展,这个领域取得了长足的进步。但是真实场景下,尤其是出现大的人脸角度变化的人脸识别仍然是一个非常有挑战性的任务。目前一种思路是先将侧脸转成正脸之后再做人脸识别。目前来讲,生成对抗网络是合成多角度人脸最好的方法,尽管取得了一定程度的成功,但是,GAN是从全局分布的角度来生成人脸的,忽略了特定的局部人脸细节。当对于小角度的人脸合成时,这个问题不算突出,但当角度变化大的时候就非常关键了。在大角度的情况下,大部分的人脸都是遮挡的,这样基于GAN的方法是“想象”出目标脸,而不能正确地根据侧脸特有的细节进行合成。另一方面,基于光流的方法是根据图像之间的密集对应(Dense Correspondence)来实现面部重构的,但是,当两张人脸图像的角度差异比较大的时候很难计算精确的光流,由于遮挡的存在,一张图像上大部分的像素点很难找到在另外一张上的对应位置。
我们认为,基于GAN的方法和基于光流的方法是互补的,它们一个从全局的角度出发、一个从局部的角度出发和成人脸。但问题是二者不能合力解决大角度的人脸合成问题。因此,我们将大角度的人脸合成进行分解,转换成一个个的小角度人脸合成。这样,我们可以充分利用两种方法的优势。具体来讲,我们提出了一种脸部光流指引的生成对抗网络(Face Flow-guided Generative Adversarial Network,FFlowGAN)来解决多角度人脸合成问题。如图1所示,在FFlowGAN中,我们首先预测输入视角脸和目标视角脸对应的光流信息。因为转变的角度很小,这样预测出来的光流可以精确地捕捉面部的纹理信息。在获取光流之后,可以用于指导GAN的生成过程。这样,给定任意一个视角下的人脸,我们的FFlowGAN可以将其转换至下一个角度。迭代使用上述方法,我们就可以合成 0- 90度之间的任意人脸。更重要的是,不同角度人脸合成的模型是共享的,而且是通过端对端的方法训练的。
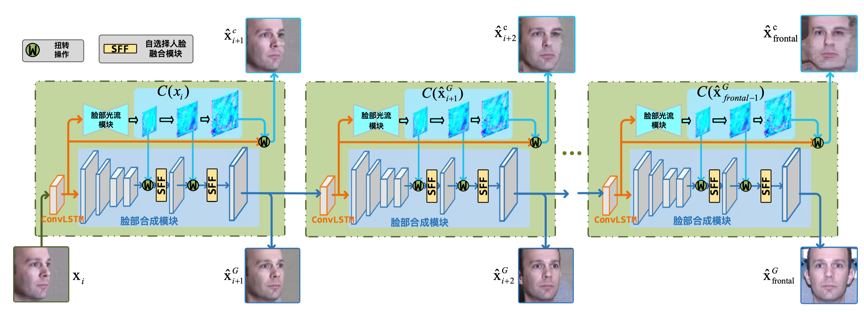
图 1 多角度人脸合成的示意图,其中包括脸部光流模块和面部合成模块。其中,脸部光流模块产生多尺度的面部光流,脸部合成模块根据多尺度的面部光流扭转生成过程中的特征。扭转后的特征不经过自筛选的面部融合模块以消除伪影同时保留面部细节。值得注意的是在不同的旋转步骤中,模型的参数是共享的(图中的绿块)。为了方便展示,我们省略掉了判别器。其中,x_{i}是输入的人脸, $x_{\cdot}^{c}$,$x_{\cdot}^{G}$ 分别代表由脸部光流模块和脸部合成模块产生的人脸。
我们在四个数据集上进行试验,分别是Multi-PIE,IJB-A,CelebA和LFW。下图展示了部分结果,完整结果可参考原文。
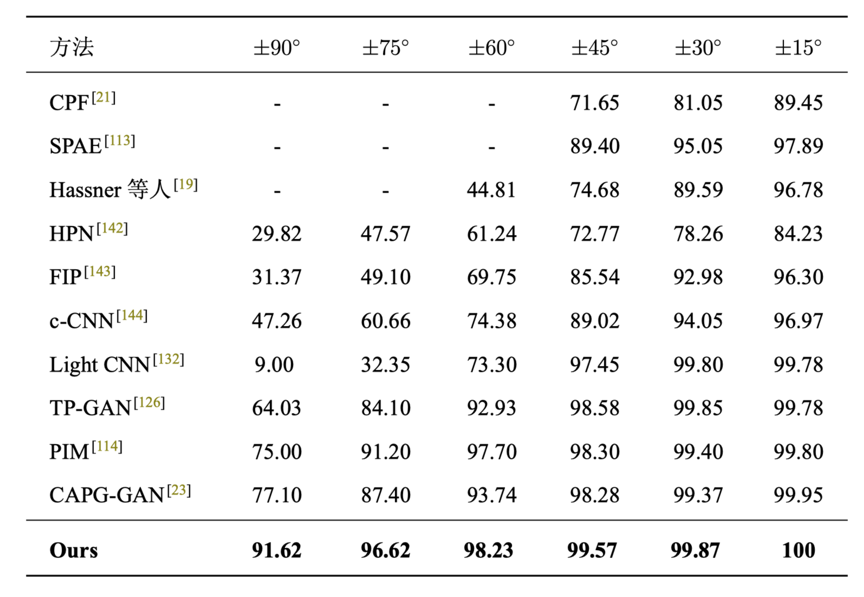
08
SADRNet: Self-Aligned Dual Face Regression Networks for Robust 3D Dense Face Alignment and Reconstruction
作者:阮泽宇1,邹常青2,吴龙海3,武港山1,王利民1
单位:1南京大学,2中山大学,3三星研发中心
邮箱:
lmwang@nju.edu.cn
论文:
https://arxiv.org/abs/2106.03021
代码:
https://github.com/MCG-NJU/SADRNet
无约束场景下的三维人脸重建是一个具有挑战性的工作,其挑战主要来自于两方面:(1)部分人脸区域的信息常因被其他物体交互遮挡或大的面部偏转带来的自遮挡而缺失;
(2)较大的人脸姿态变化会使得重建的解空间相比只有正脸姿态时大得多,使得神经网络的学习难度增加。

图 1 遮挡和大姿态情况下人脸对齐和人脸三维重建的结果
本文工作的核心思路是对遮挡进行建模,同时将姿态变化和人脸形状变化解耦,从而将三维人脸重建分解为若干更简单的子问题。以此为出发点,本文提出了一个端到端的基于自对齐的双重回归网络的三维人脸重建方法,同时回归一个姿态相关人脸和一个姿态无关人脸,并通过遮挡感知的自对齐方式结合从而生成最终的三维人脸模型。
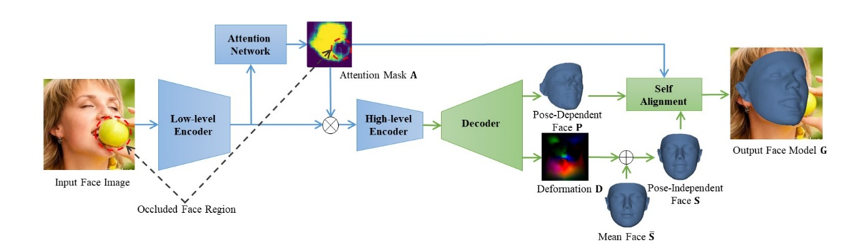
图 2 自对齐双重人脸回归网络框架
如图2所示,编码器网络首先由若干连续的残差单元提取出图像的低层特征,低层特征随后被输入到注意力分支网络。注意力分支由若干卷积层构成,输出注意力掩膜,掩膜中的高亮部分代表图像中未被遮挡的人脸区域,低亮部分代表背景和被遮挡区域。根据注意力掩膜的结果增强低层特征,将增强后的特征输入到编码器的剩余部分,进而提取出高层特征。
解码器由若干连续的反卷积层组成,在靠近尾端的几层分为两个分支,分别解码出用UV Map表示的姿态相关人脸(用于刻画人脸姿态),和人脸形变(用于刻画形状细节)。人脸形变与平均人脸模板相加得到姿态无关的正脸模型。在自对齐模块中,将正脸模型与直接回归的姿态相关人脸模型进行刚体变换估计得出人脸的姿态参数;在这个估计过程中,我们利用注意力掩膜对匹配点进行加权,进一步提高对于遮挡的鲁棒性。最后,将姿态参数应用到上述正脸模型上,得到最终的人脸模型结果。
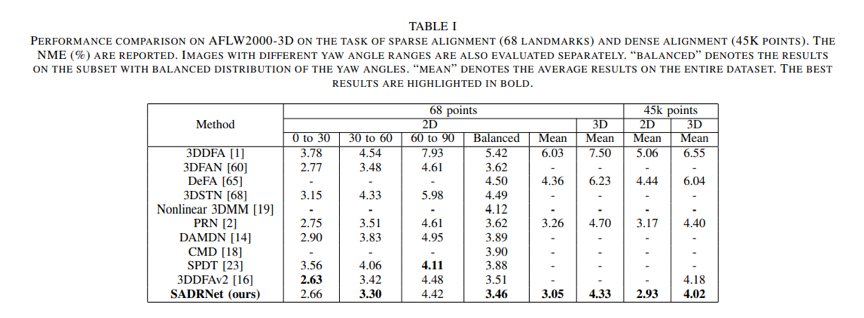
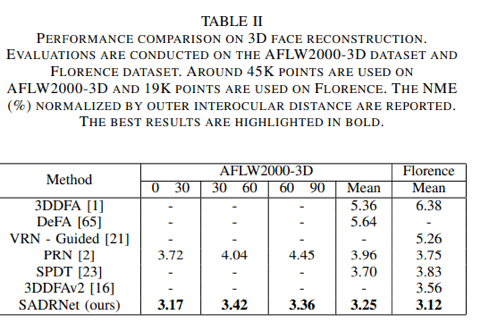
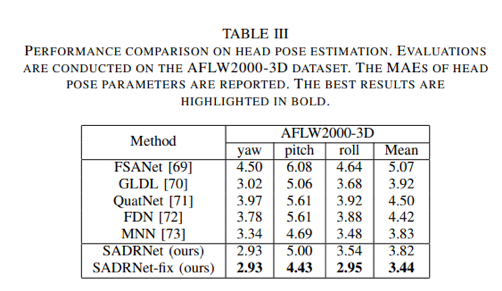
本文方法在AFLW2000-3D和Florence数据集上进行了验证,在人脸关键点估计、人脸稠密对齐、三维人脸重建和面部姿态估计等任务的定量评估上取得了超过当时的SOTA的结果。

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜