【论文导读】2022年论文导读第四期


论文导读
2022年论文导读第四期(总第四十四期)
目 录
|
1 |
Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding |
|
2 |
I Know Your Keyboard Input: A Robust Keystroke Eavesdropper Based-on Acoustic Signals |
|
3 |
D3Net: Dual-Branch Disturbance Disentangling Network for Facial Expression Recognition |
|
4 |
MageAdd: Real-Time Interaction Simulation for Scene Synthesis |
|
5 |
Dense Semantic Contrast for Self-Supervised Visual Representation Learning |
|
6 |
Co-learning: Learning from noisy labels with self-supervision |
01
Few-shot Unsupervised Domain Adaptation with Image-to-class Sparse Similarity Encoding
作者:黄胜琦1,杨琬琪1*,王雷2,周泸萍3,杨明1
单位:1南京师范大学; 2University of Wollongong; 3University of Sydney
邮箱:
huangshengqi@njnu.edu.cn;
yangwq@njnu.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475232
https://arxiv.org/pdf/2108.02953.pdf
*通讯作者
本文探讨一个新的学习问题,小样本无监督域适应(FS-UDA),即在源域样本受限(小样本)的情况下,学习一个模型将小样本的源域知识迁移到无标签的目标域中。它存在以下挑战:源域样本的稀缺,导致学习过程中存在过拟合问题;目标域无标签,给有效的域适应带来了很大的难度。为了解决以上问题,本文提出了一种适用于源域小样本限制的无监督域适应方法IMSE,即图像到类的稀疏相似编码,从局部特征的相似度编码与跨域对齐两方面解决以上问题。
IMSE方法的整体框架如图1所示。首先,通过残差网络(ResNet12)提取图像特征,考虑到特征层面的域适应,本文使用局部描述子层面的跨域对抗损失以及多尺度特征匹配损失来训练网络。其次,由于存在源域数据的小样本限制,本文提出一种新的相似度表示,即图像到类的相似度模式(SP),该模式由相似度模式编码器产生,能够实现高效的小样本图像分类。同时,在相似度模式层面,本文使用相似度模式的跨域对齐损失来实现更高层面的域适应,以达到更好的域对齐效果。
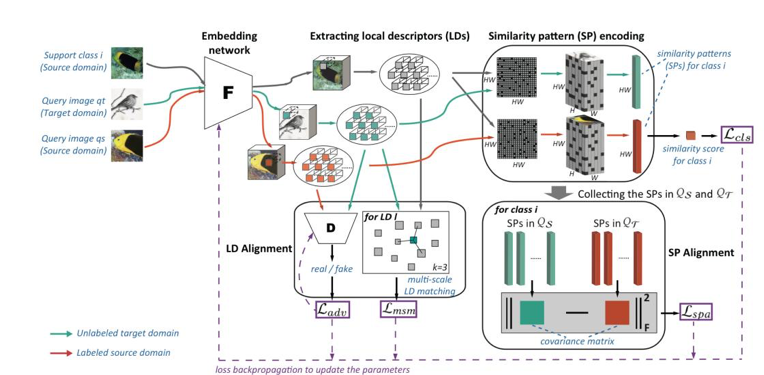
图1 IMSE方法整体框架
图2展示了相似度模式(SP)的编码器结构。首先,要计算图像到类的相似度矩阵。其次,通过每行保留最大K个值的方式稀疏化该矩阵,并将其按照图像的空间位置进行排布。最终,经过高斯滤波和池化,得到了最终的相似度模式向量。该编码过程通过稀疏化的方式提高了判别性,同时考虑到了图像的空间特性,并通过高斯滤波实现了去噪,使得它可以用于高效的小样本图像分类。正是由于相似度模式包含了丰富的高层语义信息,它可以用于跨域对齐,本文通过计算源域和目标域相似度模式的协方差矩阵,并减小二者的差异,以达到相似度模式分布信息的对齐。
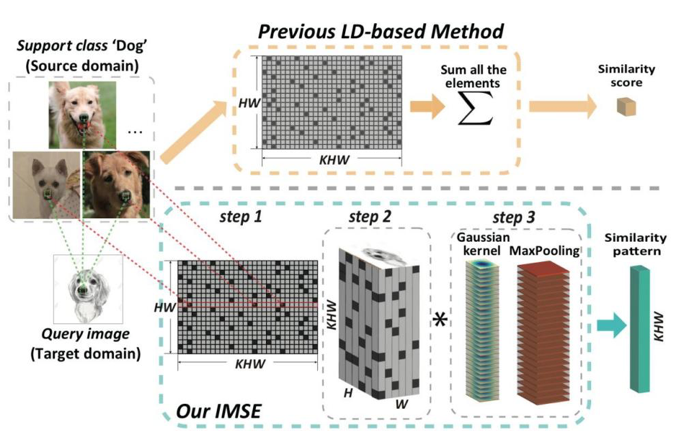
图2 相似度模式的编码器结构
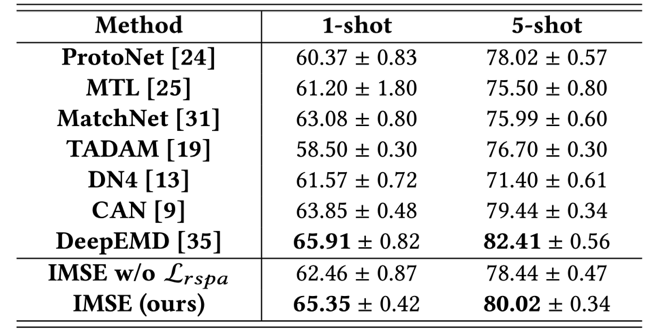
表1展示了一系列方法在DomainNet数据集上的1、5-shot小样本无监督域适应任务性能,而IMSE方法取得了最好的成绩。表2展示了消融实验,实验证明了同时使用特征和相似度模式层面的跨域对齐的有效性,通过相似度层面的跨域对齐,模型的性能被很大的提升。如表3所示,本文在miniImageNet数据集上进行小样本学习(FSL)的对比实验,IMSE方法也表现出了不错的分类性能。总的来说,IMSE方法能够有效地解决小样本无监督域适应问题以及小样本图像分类问题。
表 1 在DomainNet数据集的对比实验结果
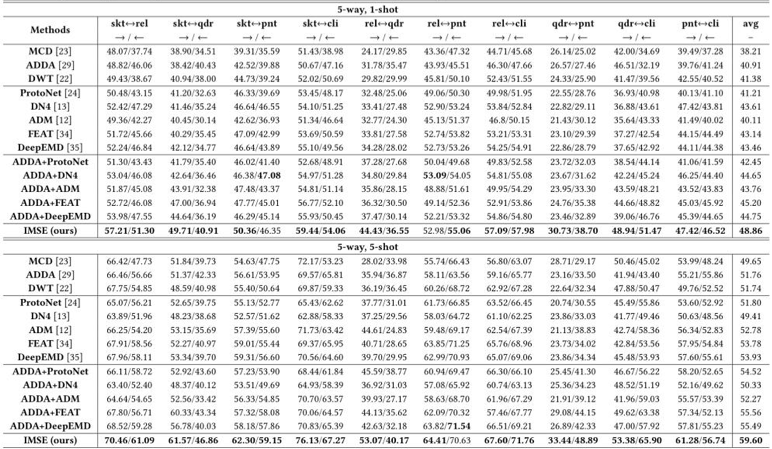
表2 在DomainNet数据集不同跨域对齐模块的消融实验结果
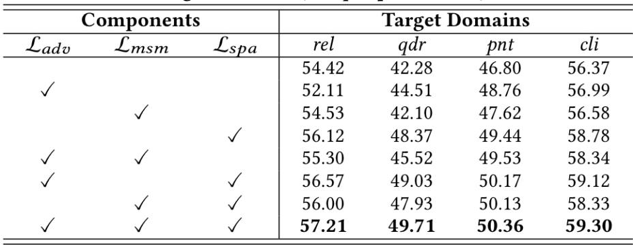
表3 在miniImageNet数据集上进行小样本学习(FSL)的对比实验结果

02
I Know Your Keyboard Input: A Robust Keystroke Eavesdropper Based-on Acoustic Signals
作者:白家璇,刘斌,宋路川
单位:中国科学技术大学 (网络空间安全学院)
邮箱:
bjx@mail.ustc.edu.cn;
flowice@ustc.edu.cn;
slc0826@mail.ustc.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475539
由于高精度麦克风的普及,各种智能设备可能成为隐私泄露和侧信道攻击的突破口。使用商用智能手机对键盘输入进行窃听是一个比较有威胁的隐私泄漏点,对该话题的研究解释了智能设备对隐私的重大威胁。完成鲁棒的击键窃听攻击包括一下几个难点:1. 在实际情景下,攻击者很难掌握来自输入者和输入设备的真实样本,这导致很难训练需要大规模样本的模型用于攻击;2. 击键发出的声音信号受到各种不稳定因素的影响,导致信号的类间距离增大、类内距离减小,给预测任务带来困难;3. 攻击者很难采用大规模的麦克风阵列进行攻击,这使得大部分传统的声学定位算法无法使用。基于这些问题,本文提出了一种新颖的、鲁棒的基于声学的按键窃听攻击方法。我们提出了一种方案,仅使用具有双麦克风的单个智能手机来进行侧信道攻击。面对未知的输入环境,我们提出了一种位置估计方案来获得麦克风和键盘之间的相对位置。我们通过基于到达时间差(TDoA)的参数优化算法在估计麦克风位置。因此,所提出的方案允许我们学习最初未知的输入环境,并在恢复的环境中建立一个小的训练集来预测未知的按键。同时我们提取两个鲁棒且稳定的特征,即 TDoA 和功率谱密度 (PSD),以区分不同位置的击键。为了保证所提方案的鲁棒性,我们选择的特征主要随击键位置而变化,受击键音和声音强度等因素的影响较小。
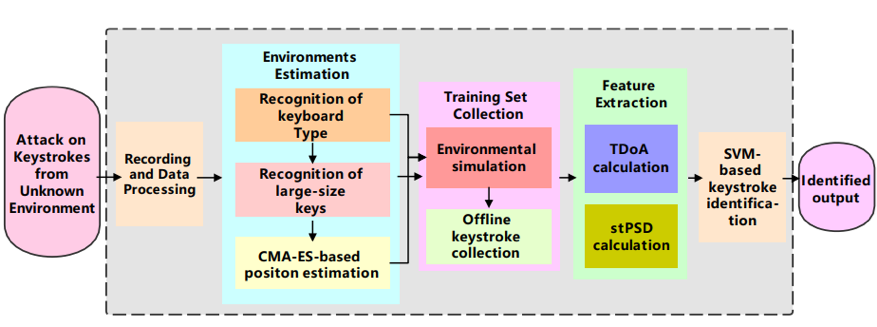
图1 一次完整的对按键的侧信道攻击流程。输入为一系列未知的按键声学信号,经过数据预处理、环境估计算法、模拟训练集收集、数据提取和模型训练,最终输出按键标签。
对于环境估计算法模块,本文主要解决的问题在于在没有先验知识的情况下恢复不熟悉的输入环境。攻击者通过音色判断键盘种类,识别出一些特别的大尺寸按键,最后采用基于协方差矩阵进化策略(CMA-ES)的优化算法估计麦克风坐标。随后基于按键位置提取的特征,包括TDoA和PSD使训练的模型可以对未知的输入者和输入设备鲁棒,摆脱按键的力度、速度、姿势等不稳定因素的影响。我们使用支持向量机(SVM)训练按键分类模型,以适应特征的整体性和训练集较小的情况。最后,我们通过预测的置信度组合进行单词层面的预测,进一步提升准确率。图1展示了本文所提出方案的完整流程。
我们复现或遵循官方开源代码重演了其他按键预测方面的工作,并将这些算法的效果与我们提出的方案进行对比,结果如图2所示。从图2中我们发现,我们的算法在以往工作针对的场景中,即掌握一部分训练样本的情况下,能获得更好的准确性。同时,在攻击者面对陌生的攻击场景,未掌握先验知识时,我们的算法取得了更大幅度的准确率提升。这证明了我们的算法更适应细粒度的按键区分任务和侧信道攻击经常需要面对的未知场景,进一步揭示了这种攻击方式对隐私的威胁性。
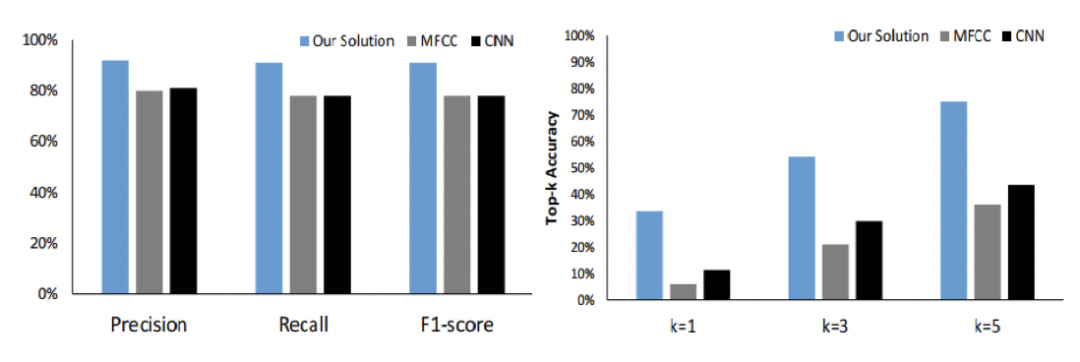
图2 我们的方法和已有工作的算法进行对比。分别在熟悉场景、已拥有训练集和陌生场景、未掌握训练集的前提下进行实验对比。
03
D3Net: Dual-Branch Disturbance Disentangling Network for Facial Expression Recognition
用于人脸表情识别的双分支干扰分离网络
作者:莫榕云1,严严1,*,薛景浩2,陈思3,王菡子1
单位:1厦门大学,2伦敦大学学院,3厦门理工学院
邮箱:
morongyun@stu.xmu.edu.cn
yanyan@xmu.edu.cn
jinghao.xue@ucl.ac.uk
chensi@xmut.edu.cn
hanzi.wang@xmu.edu.cn
论文:
https://dl.acm.org/doi/pdf/10.1145/3474085.3475249
对于人脸表情识别任务而言,人脸表情图像中存在常见干扰因素(如身份、光照、姿态等)和潜在干扰因素(如发型、配饰、遮挡等),会严重影响表情特征的提取。在之前的工作中,一部分基于显式干扰解耦的方法只考虑了有限的常见干扰因素,忽略了潜在干扰因素的影响;另一部分基于隐式干扰解耦的方法,没有利用常见干扰因素的先验信息,导致干扰解耦的性能不够理想。
为了解决上述问题,本文提出了一种用于人脸表情识别的双分支干扰分离网络(D3Net),可以抑制常见干扰因素和潜在干扰因素,提取更有效的表情特征。如图1所示,该网络包括表情分支和干扰分支。表情分支采用交叉熵损失作为分类损失。干扰分支包含LAS和LFS两个子分支。LAS利用其它人脸数据集的干扰标签,以迁移学习的方式来训练,可以提取常见干扰特征。LFS引入了非参数贝叶斯先验——印度自助餐过程(IBP)先验,以无监督的方式学习潜在干扰特征。在LFS中,潜在干扰特征由权重矩阵W和干扰存在矩阵D构成。矩阵的第i行对应第i张输入图像,第k列对应第k种干扰因素。权重矩阵W的先验密度服从高斯分布。干扰存在矩阵D的每个元素为0或1,当第i张图像中存在第k种干扰因素时,对应元素的值为1,否则为0。D的第k列元素的先验密度服从概率为πk的伯努利分布。根据折棍原理,πk由一组服从贝塔分布的随机变量v={v1,v2,…,vk,…}组合相乘而得。然后,分别计算W、D和v的后验密度与先验密度之间的Kullback-Leibler散度再相加,构成LFS的损失函数。此外,为了区分干扰特征和表情特征,本文在LAS和LFS中都引入了对抗训练。最后,通过优化联合损失,促使表情分支更专注于提取高判别力的表情特征。
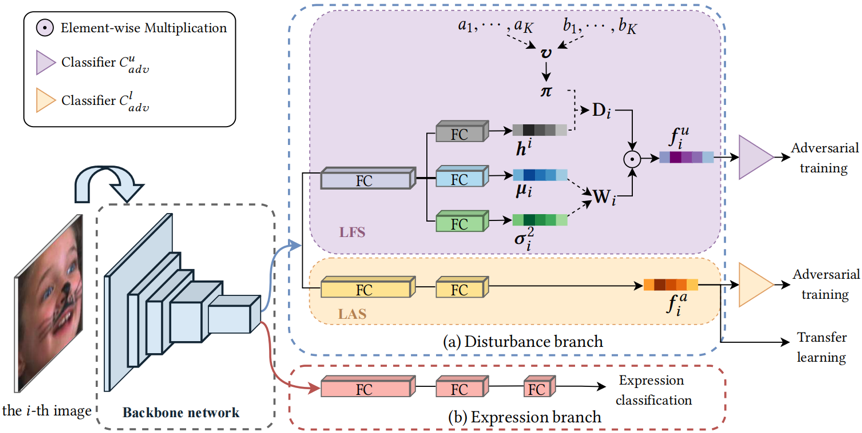
图1 双分支干扰分离网络D3Net的网络结构图
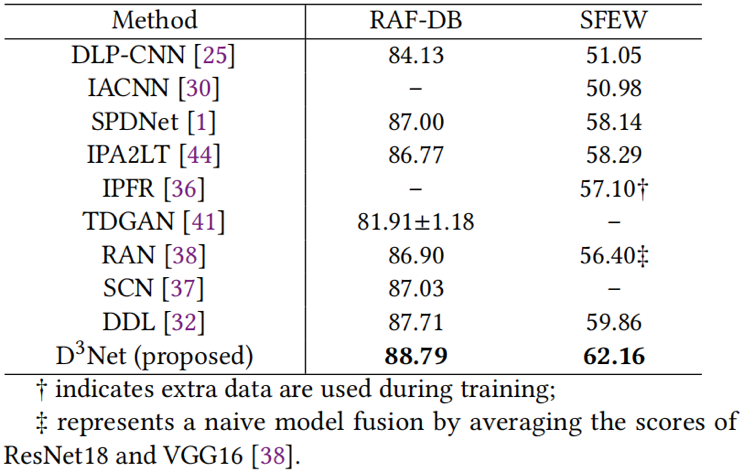
表1展示了所提出方法中各个模块的消融实验结果。可以看出,LAS、LFS和对抗训练都提高了表情识别的性能。图2的可视化结果表明,对比基线方法,本文方法学习的表情特征分布类间距离更大,类内距离更小。表2和表3分别展示了在室内数据集和室外数据集上所提出方法与其他方法的性能对比。实验结果表明,所提出的方法获得更高的表情识别准确率,具有优异的性能表现。
表1 所提出方法在五个数据集上的消融实验结果
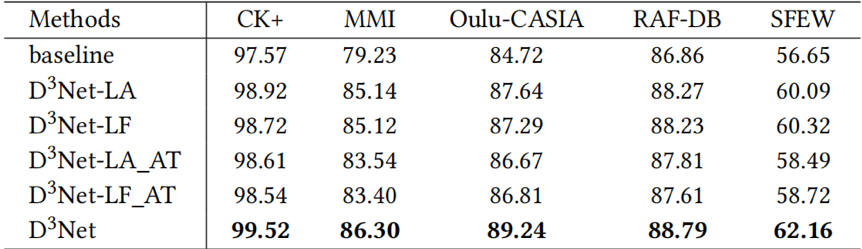

图2 特征分布的可视化结果
表2 在三个室内数据集上与其他方法的识别准确率(%)对比
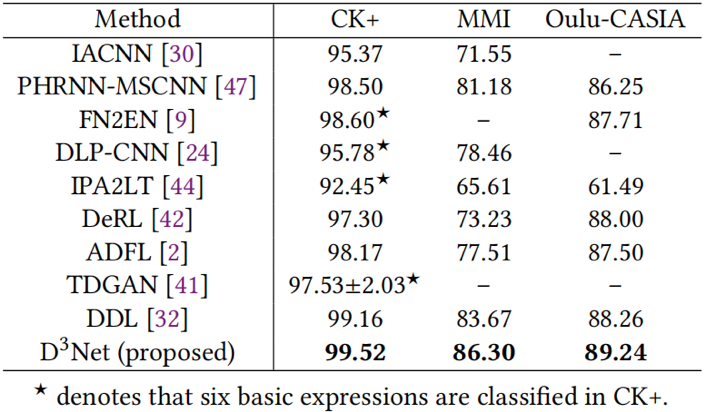
表3 在两个室外数据集上与其他方法的识别准确率(%)对比
04
MageAdd: Real-Time Interaction Simulation for Scene Synthesis
作者:张少魁1、李艺潇1、何煜1、杨永亮2、张松海1
单位:1清华大学,2巴斯大学
邮箱:
zhangsk18@mails.tsinghua.edu.cn
liyixiao20@mails.tsinghua.edu.cn
hooyeeevan@tsinghua.edu.cn
y.yang@cs.bath.ac.uk
shz@tsinghua.edu.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475194
代码:
https://github.com/Shao-Kui/3DScenePlatform#mageadd
1. 引言
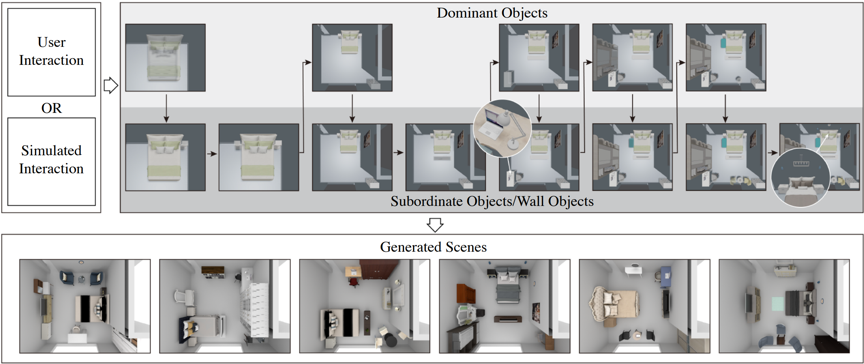
图1 交互式布局生成框架概览
本文提出了一种实时的、交互式的三维场景构建方法,其核心之一在于“让用户可以控制自动生成布局的流程”。当前三维场景自动合成已经取得了令人印象深刻的成果,它侧重于满足人们对布局的共性习惯,但未考虑用户的个人偏好,仍需通过交互来满足用户个性化的需求。针对此问题,本文提出了一个数据驱动的三维场景交互合成方法,可以根据用户已确定的场景对象(用户偏好)和对象关联关系先验,实时推荐用户感兴趣的对象,通过最低限度的鼠标指针输入,智能地将物体推荐到鼠标指针指向的场景中,从而实现场景自动合成与用户偏好输入的无缝融合。
2.系统流程
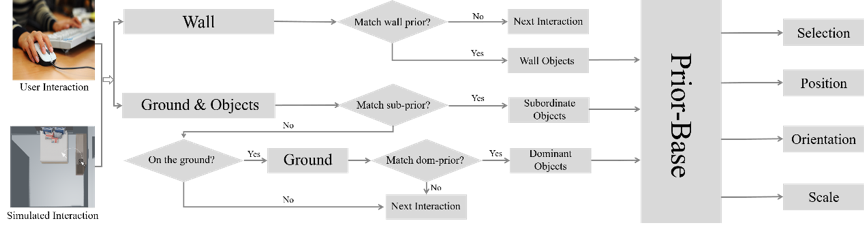
图2 方法的执行流程
文章的核心之一在于一个实时的框架。上图展示了方法的执行流程,该流程表示每一个鼠标挪动的‘瞬间’。交互的流程分为三个‘分支’,每个‘分支’对应一‘类’物体,每类物体的【先验学习】与【推断】方法均不同。三个类别分别是:主物体、从物体与墙体物体。若鼠标指向墙体,框架则首先匹配墙体物体的先验;若鼠标在其他几何上,框架则尝试匹配从物体的先验。若没有从物体的先验被匹配,则匹配主物体的先验。框架基于从数据集中学习的用于放置不同类型对象的先验知识,这些先验会根据每个特定场景的特定时刻进行定制,从而大大减少计算量。我们每次匹配到一个先验,这个先验都会回答系统:要把那个物体放在哪里,包括物体的选择、平移、旋转、缩放。同时,注意到‘Prior-Base’,这个先验库会基于用户的交互不断更新,比如加入了双人床,会进一步引入床头柜的先验。因此,先验库的维护永远仅仅包含和场景相关的最小先验集合,这也是本文实现实时的原因之一。
3. 房间深度模型
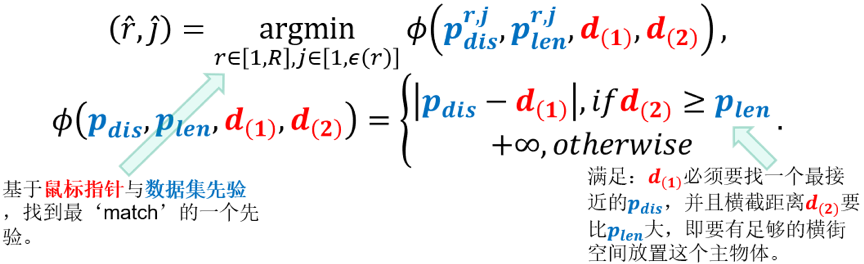
本文的核心之二在于提出了‘房间深度模型’(Room Depth Model),其本质是提取物体和房间之间的先验,即物体与房间的关联关系。传统方法主要关注于物体自身、物体与物体间的关联关系提取,但这并不适用于倾向于独自存在、独自布局的物体。房间深度模型的本质如上图所示:对于数据集中的所有提取好的(pdis,plen),我们尝试将其与当前瞬间的(d(1),d(2))比较,并找出在上下文意义上,最接近的一对(pdis,plen)。比较的方式参考下面的公式,对于当前瞬间鼠标得到的(d(1),d(2)),d(1)必须要找一个最接近的pdis,并且横截距离d(2)要比plen大,即要有足够的横街空间放置这个主物体。文章正文的该部分提供了一个实际的例子用于帮助解释上述两个公式。同时,文章正文包括了从物体与墙体物体的先验提取与使用。
4. 实验
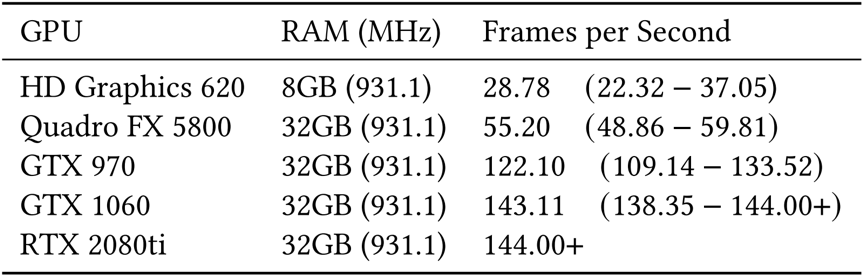
通过实验,我们证明了我们的框架在结果美学方面优于当前已有技术,并且能够实现高效的用户交互。本文的实验分为三个部分,首先通过用户实验比较本文提出的框架与传统的手动场景生成框架,后者即:用户搜索物体、添加物体、微调物体。如表1所示,本文的框架可以大幅度减少场景交互的耗时,并且不会降低交互和结果的质量。如表2所示,我们将方法调整为全自动,并将方法与SOTA的三维场景自动布局方法比较,其结果的美观性与适用性仍然超过已有方法。最后,表三展示了方法的执行效率,方法在效率的‘worst case’时(参考原文),仍能在集成显卡上达到实时。在结尾,展示了文章的演示Demo和渲染后的结果。
表1 系统交互
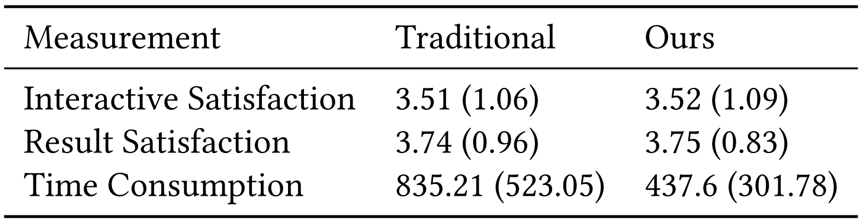
表2 与全自动的布局SOTA方法对比,本方法仍然优于所有方法
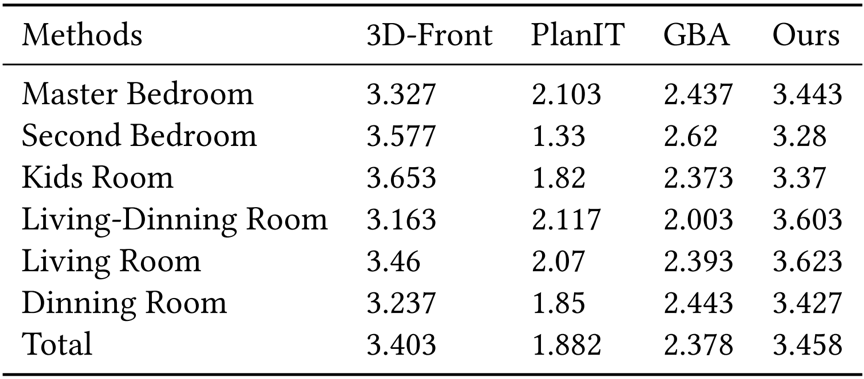
表3 框架在不同环境下的执行效率,本方法可在集成显卡上仍达到实时

05
Dense Semantic Contrast for Self-Supervised Visual Representation Learning
作者:李晓倪1,2,周宇1,2,*,张宜飞1,2,张傲婷1,2,王威1,2,蒋宁3,吴海英3,王伟平1
单位:1中国科学院信息工程研究所,2中国科学院大学网络空间安全学院,3马上消费金融
邮箱:
lixiaoni@iie.ac.cn;
zhouyu@iie.ac.cn;
zhangyifei0115@iie.ac.cn;
aotingzhang@126.com;
wangwei3456@iie.ac.cn;
ning.jiang02@msxf.com;
haiying.wu02@msxf.com;
wangweiping@iie.ac.cn
论文:
https://dl.acm.org/doi/10.1145/3474085.3475551
*通讯作者
用于视觉预训练的自监督表示学习在样本(实例或像素)判别和实例语义挖掘等方向取得了显著的成功,但预训练模型与下游密集预测任务之间仍存在不可忽视的差距。具体来说,这些下游任务需要更精确的表示,也即来自同一目标的像素必须属于同一个语义类别,这是以前的方法所缺乏的。在这项工作中,我们提出了密集语义对比(DSC),用于在密集级别上建模语义类别决策边界,以满足这些任务的要求。此外,我们还提出了一个用于多粒度表示学习的密集跨图像语义对比学习框架,通过从不同角度挖掘像素之间的关系来显示地探索数据集的语义结构。
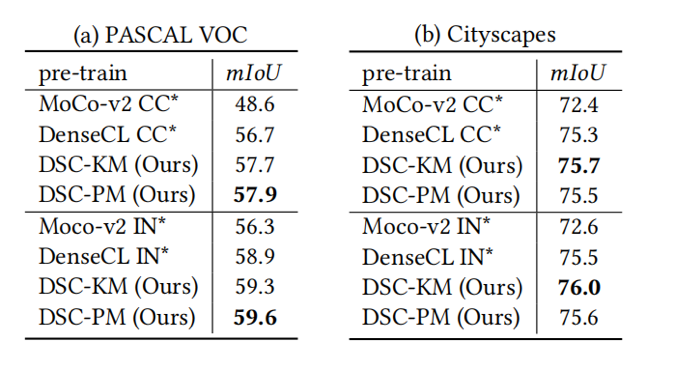
图1是所提出DSC模型的整体框架,包含实例判别、像素判别和语义挖掘三个部分。对于实例和像素的判别,我们进行标准的对比学习。在这两个判别工作之后,有两个问题需要应对。第一个问题,在每个实例中所有像素都被推远(即每张图像),忽略了其固有的像素级别的语义结构。为此我们建议从多个视图中搜索邻居,如图2所示,我们挖掘每个像素的相关样本,理论上,无论是不同视图的增强版本,还是同一视图下的邻居,都应该和当前像素属于同一个语义类别。第二个问题,在经过像素判别之后,不同图像的像素之间仍然没有联系。为此我们尝试使用一些聚类方法在图像之间重新分配每个像素的标签,如图3所示,△代表聚类过程,为简单起见,这里的聚类方法考虑K-means(DSC-KM)和原型映射(DSC-PM)。DSC-KM和DSC-PM对SSL模型施加不同的约束,以探索像素之间的语义决策边界,两者都明确地证实了其有效性。具体来说,DSC-KM要求两个视图下的像素聚类中心是一致的,而DSC-PM强制每个像素的聚类分配是一致的。
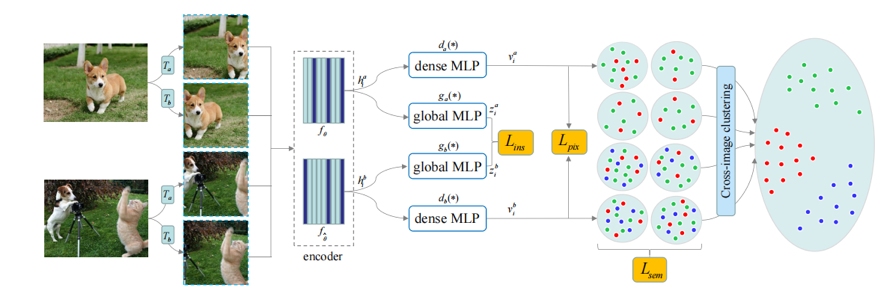
图1 用于多粒度表示学习的DSC框架。
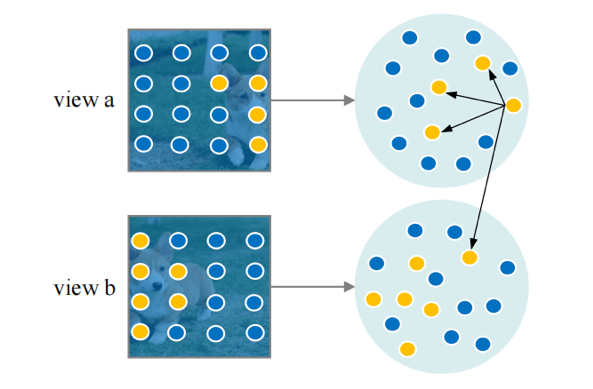
图2 邻居挖掘。黄色的实心圆圈是来自不同视图中目标“狗”的像素。
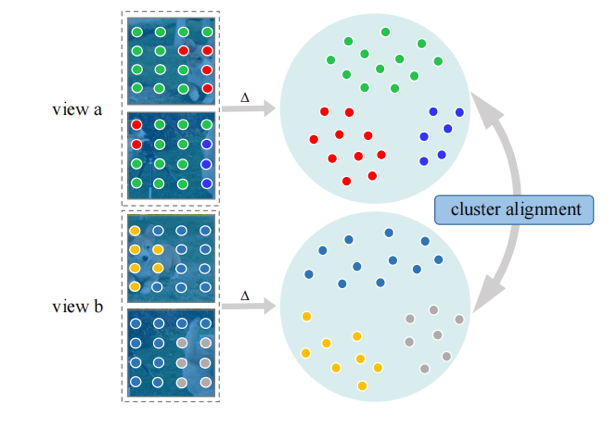
图3 聚类对齐。
DSC分别在ImageNet和MS COCO上进行了预训练,在不同数据集上的目标检测和分割任务上进行了评估(表1、表2、表3)。CC and IN分别表示在MS COCO和ImageNet上预训练的模型,*表示复现结果。可以看出,所提方法在各种下游密集预测任务上的性能,均超过了SOTA(DenseCL)和baseline(MoCo-v2),显示出DSC的有效性。如图4所示,我们在PASCAL VOC语义分割任务上,可视化了在MS COCO微调任务上不同模型的可迁移性。DSC模型使得分割任务的性能变得更好,再次证明了我们的语义挖掘方法对于下游密集预测任务的有效性。
表1 在PASCAL VOC数据集上目标检测的性能。
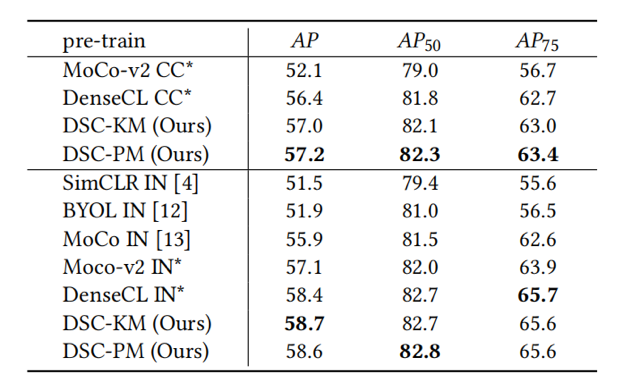
表2 在PASCAL VOC和Cityscapes数据集上语义分割的性能。
06
Co-learning: Learning from noisy labels with self-supervision
作者:谭铖,夏俊,吴立荣,李子青
单位:西湖大学,浙江大学
邮箱:
tancheng@westlake.edu.cn
xiajun@westlake.edu.cn
wulirong@westlake.edu.cn
Stan.ZQ.Li@westlake.edu.cn
论文:
https://dl.acm.org/doi/abs/10.1145/3474085.3475622
代码:
https://github.com/chengtan9907/Co-training-based_noisy-label-learning
带噪学习问题
近年来,深度学习在众多领域取得了重要进展,其成功依赖于大规模精心标注的数据。准确的标注是昂贵且耗时的,人们常常使用廉价的替代方法,如通过人工众包平台或Web爬虫完成标注,但这些替代方法通常会带有错误的标签,我们一般称这些有错误的标签为“噪声标签”。研究表明,深度神经网络容易对噪声标签过拟合,这大大降低了模型的泛化性能。
人工标注可能产生一些错误的标签。如下图1所示,是Animal-10N数据集的图例。这个数据集包含了十种动物的图像,可以分为五组容易混淆的动物:猫和猞猁、仓鼠和豚鼠、狼和豺、猎豹和美洲虎、黑猩猩和红猩猩。人工标注时容易给这些动物打上错误的标签,从而导致模型在错误的知识上学习。

图1 Animal-10N 数据集的图例
网络爬虫收集的数据往往包含错误的标签。如下图2所示,是Food-101N数据集的图例,这些数据都是在网络上搜索“华夫饼”得到的结果,红色框线标记的是错误的标签。可以看出,从网络中直接搜集的数据并不完全是我们想要的。

图2 Food-101 N数据集的图例
带噪学习的目标是在含有噪声标签的数据集上训练模型,使模型充分利用数据集的正确信息,避免对噪声标签的过拟合问题。最近一些研究工作关注了半监督学习在带噪学习领域的作用,其中多数方法采用无监督学习来获取标签无关特征的信息,然后以有监督学习的方式使用噪声标签进一步训练。这些方法通常通过两种视角来利用标签:有监督学习利用标签的监督信号,无监督学习利用数据的内在特征来对抗标签噪声。其中的核心挑战是如何有效地结合这两种视角。联合训练和模型集成是带噪学习中一类重要的方法,这类方法基于两个网络模型能够提供数据的不同视角的假设,但它们所带来的额外信息增益非常有限,因为相同架构的两个网络之间的差异主要来自于随机初始化。
Co-learning方法
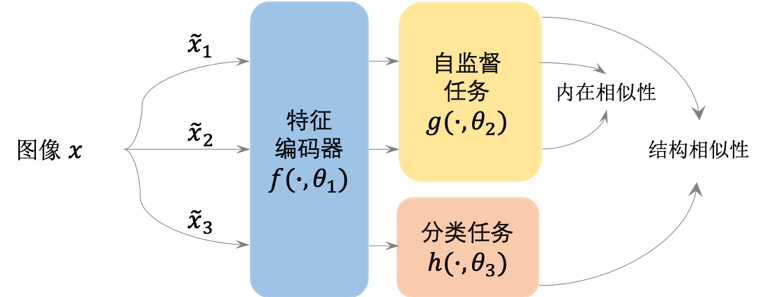
图3 Co-learning通用算法框架,由自监督和分类两个任务协同完成,在保持各环节数据自身内在特征相似性的同时,保持两个任务变换后特征的整体分布结构相似性。
受到半监督学习和联合训练方法的启发,这篇论文提出了一种通过同时进行有监督学习和自监督学习来对抗标签噪声的方法Co-learning,如图3所示。这是一种全新的带噪学习训练范式,利用学习任务中的内在相似性和结构相似性约束模型,通过有监督学习和自监督学习的协同训练,有效地缓解了模型对带噪标签的过拟合问题,其中有监督信号提供了标签相关的信息,自监督提供了特征相关的信息。
内在相似性指的是,数据经过不同的变换后,保持自身的相似性,由自监督中正样本对和负样本对的对比学习来实现——对比学习典型流程如图4。
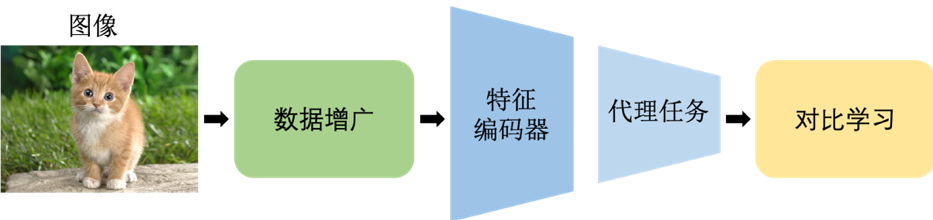
图4 对比学习的典型流程
结构相似性指的是,数据经过不同的任务后,保持输入数据的分布结构,由数据整体分布的KL散度来控制,如图5所示。
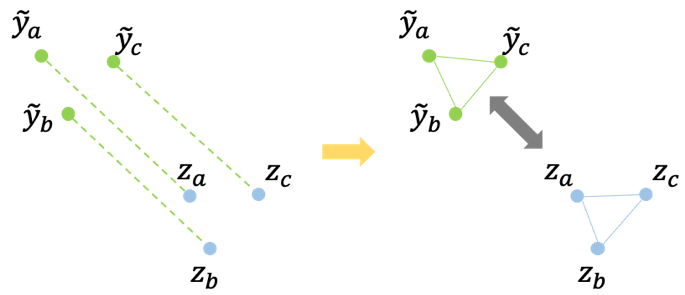
图5 结构相似性示意图。左:变换\hat{y}—>z;右:变换后样本间关系保持相似。
现有的带噪学习常常采用联合训练两个特征编码器的解决方案,而Co-learning采用一个共享的特征编码器,且由两个合作的分支网络来执行不同的任务,一个分支网络利用特征相关的信息,通过内在相似性执行自监督学习;而另一个分支网络执行有监督学习并利用标签相关的信息。同时,利用结构相似性损失来约束两个分支网络,避免受噪声标签的影响产生偏差。Co-learning不需要诸如噪声率、数据分布和额外的干净样本等先验知识,避免了过多的超参数。
总结
文章指出了带噪学习中常见的联合训练范式存在的问题,尽管此类方法假设多个网络模型能够为数据提供多个不同的视角,但现有的方法能够带来的信息增益极少。Co-Learning方法通过自监督学习来辅助带噪学习,同时利用标签相关信息和特征相关信息来解决带噪标签导致的过拟合问题。此外,经过不同变换和不同任务约束的数据应保持(1)自身的特征相似性和(2)分布结构相似性,利用这两个原则来约束模型的学习,使得模型对标签噪声具有较强的鲁棒性。实验表明,该方法在不同噪声类型和不同噪声比例条件下都取得了较优的效果,提供了一种利用自监督学习实现鲁棒深度学习的新范式。

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜

