干货 | 北航博士生黄雷:标准化技术在训练深度神经网络中的应用

AI 科技评论按:标准化技术目前已被广泛应用于各种深度神经网络的训练,如著名的批量标准化技术 (Batch Normalization, BN) 基本上是训练深度卷积网络的标准配置。装配有 BN 模块的神经网络模型通常比原始模型更容易训练,且通常表现出更好的泛化能力。
近期,在 GAIR 大讲堂上,来自北京航空航天大学的博士生黄雷同学将阐述标准化技术应用于训练深度神经网络中的主要动机以及介绍一些主流的标准化技术,除此之外报告人也将讲解其沿着这个方向发表在 AAAI 2018 的论文《Orthogonal Weight Normalization: Solution to Optimization over Multiple Dependent Stiefel Manifolds in Deep Neural Networks》。
黄雷,北京航空航天大学计算机学院博士,曾于 2015 年 10 月至 2016 年 10 月在密歇根大学安娜堡分校 Vision & Learning 实验室做关于深度学习模型优化方面的研究。主要的研究领域为深度神经网络中标准化技术,半监督学习,非参主动学习及相关方法在计算机视觉和多媒体领域中的应用。目前已发表学术论文十余篇,包括 CVPR,ICCV 和 AAAI 等。
分享主题:
标准化技术在训练深度神经网络中的应用
分享提纲:
1. 标准化技术应用于深度神经网络训练的主要动机及相关方法介绍。
a) 标准化技术加速神经网络训练的主要动机
b) 主要的标准化方法介绍
2. 正交权重标准化技术:在通用的前向神经网络中学习正交过滤器组。
a) 在深度神经网络中学习正交过滤器组的主要动机
b) 基于重参数化方法求解多个依赖的Stiefel流形优化问题
c) 实验结果介绍
分享内容:
本次分享主要包括两个方面:一是标准化技术的介绍,二是我发表在AAAI上的论文—Orthogonal weight normalization(OWN)。
首先介绍一下为什么要对输入数据进行标准化操作,对输入数据进行标准化操作在传统机器学习或数据挖掘中是很常见的,一是因为标准化操作通常能够提高模型的训练效果,这对非参模型非常重要比如 KNN、Kernel SVM,二是因为标准化可以提高优化的效率,使得模型收敛相对较快,这对参数化模型比较重要。

现在再讲一下为什么在深度神经网络中,对隐藏层的激活值进行标准化非常重要,我们以多层感知器为例进行讲解。

刚才讲完了在深度神经网络中对激活值进行标准化的主要动机,接下来介绍一些标准化技术。第一个方法就是非常著名的 Batch Normalization,我们讲一下它的主要动机。
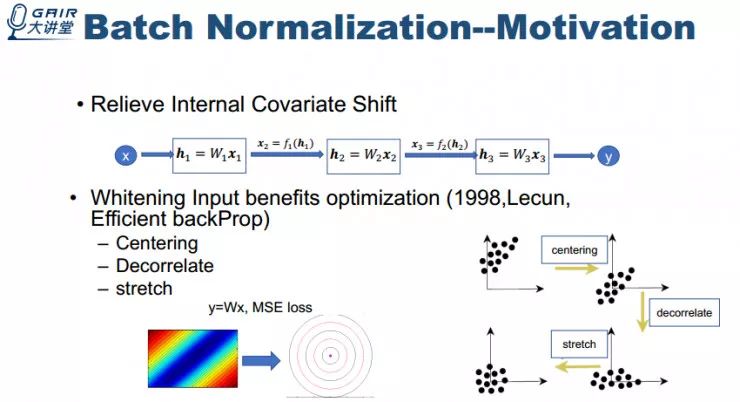
接下来我们来说一下 Batch Normalization 具体如何做标准化,其实对于 BN 来说涉及到好几个方面的选择。第一个方面是标准化操作是基于整个训练数据集还是基于 mini-batch 数据?第二个方面是把标准化操作中的量当做是待估计的参数还是当做数据的函数?第三是要不要进行完全的白化操作?我接下来分别解释一下 Batch Normalization 是怎样选择的,以及为什么这样选择。

基于之前的想法,Batch Normalization 的具体的实现如下所述。我想特别说明一下为什么把 Batch Normalization 放在线性单元的后面而不是放在线性单元的前面,这其实有违于其对数据进行白化操作的动机。当然把 BN 放在线性单元的前面和后面各有优缺点。

接下来介绍一下 Batch Normalization 两个比较好的属性。一是加速训练,二是有泛化能力。

下面我大致整理了一下 Batch Normalization 相关的工作,分为四个方面。
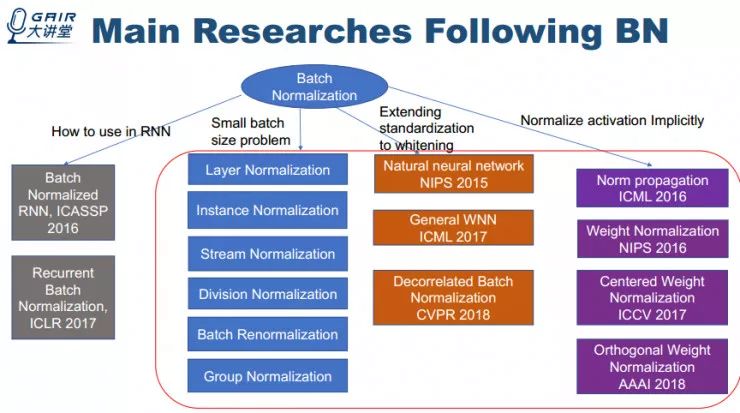
我主要介绍 small batch size problem、Extending standardization to whitening 、Normalize activation Implicitly 这三个方面的工作。首先是 small batch size problem,我按时间顺序把相关工作列出来并简单地比较一下。
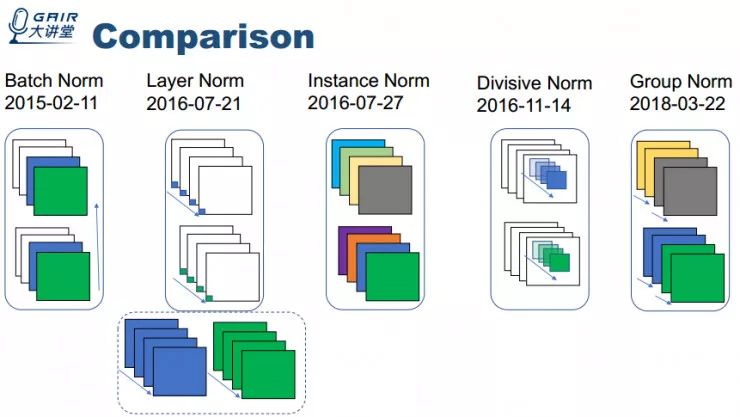
总结一下这个方向的工作抽象来说就是设计一个基于输入数据的变换且要保证该变换是可微的,这样就能够保证每批量数据有稳定的分布,从而能够稳定训练。然而,从优化的观点来看,我认为还是 Batch Normalization 做的最好。

接下来我们讲一下 Extending standardization to whitening 这个方向的工作。一个操作是把白化变换中的相关量当做是待估计的参数,另外一个是把白化操作的相关量看做是输入数据的函数。

第三个方向是 Normalize activation Implicitly。通过对参数、权重矩阵进行相关处理来进行标准化。这里面的最早的一个工作是 Norm Propagation。

接下来我讲一下我发表在 AAAI2018 上的论文—正交权重标准化技术。之所以引入正交过滤器是因为它有两个很好的属性,一是能量保留的属性,二是冗余度低。这两个属性对于稳定神经网络各层的激活值的分布以及规整化神经网络来说有很大的好处。这个方向之前也有一些相关工作,但是只限定于在 RNN 的隐藏层到隐藏层的变换中使用。

但我们期望在前向神经网络中学习更一般的矩形正交矩阵。之前也存在使用约束惩罚的方法。

因为我们期望学习正交矩阵,那么我们可以把该问题当做限制优化问题。我把问题定义为 Optimization over Multiple Dependent Stiefel Manifolds (OMDSM) 。之所以这么定义有两个原因,一是包含多个嵌入的子流,二是每个权重矩阵的损失函数的误差曲面相互依赖。

定义完问题之后我们尝试使用 Riemannian 方法来求解这个问题,但实验结果并不理想。
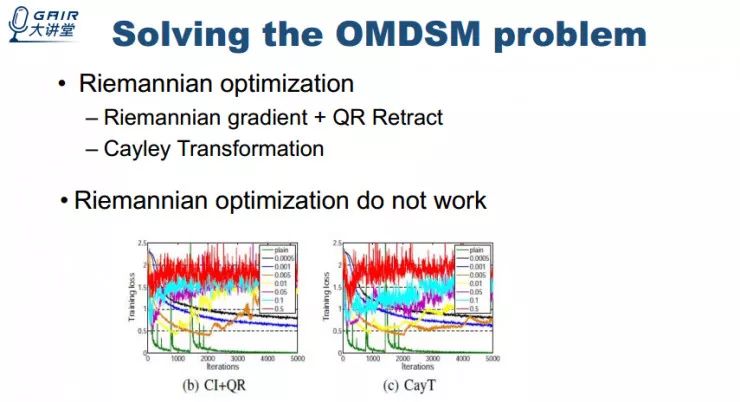
受启发于重参数方法以及正交变换是可微的这个结论,我们的方法是设计一个代理参数矩阵,对其进行正交变换得到正交化的权重矩阵,且优化是基于代理参数矩阵。
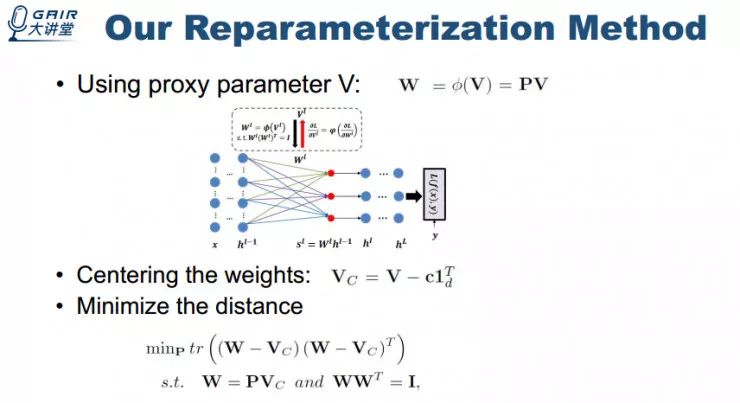
为了保证稳定性,期望使得变换后的矩阵正交权重矩阵和代理参数矩阵差异最小。对上图问题进行求解可以得到下图结果。

有了前向变换以及一些相关的结论,我们也可以进行 backward propagation 使得梯度流通过该正交变换。把这两个过程封装成 module,我把它称为 Orthogonal Linear Module (OLM) 。

最后我也对其进行了相关拓展,如考虑如何在卷积上进行拓展等。

然后我再简单介绍一下我做的相关实验。
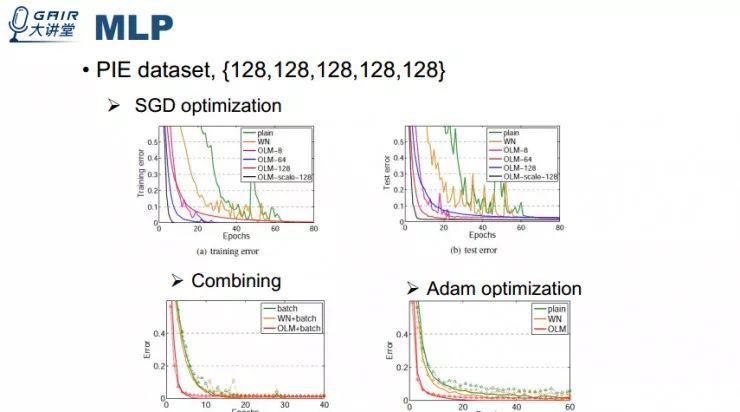
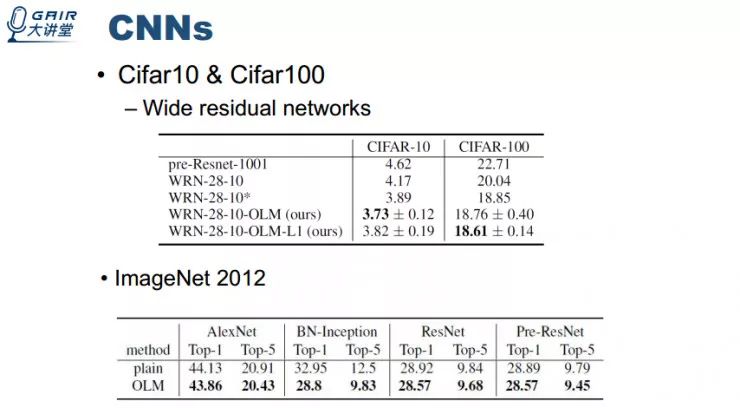
实验结果表明使用我们的的 OLM 替换原有层后训练的效果提升比较显著。我的这篇论文说明了两件事,一是在前向神经网络里面可以确切的学习到正交过滤器,二是这种学习到的正交过滤器可以提升深度神经网络的效果。我觉得将这种方法使用到 GAN 训练等其他方面也可能得到好的效果。

以上就是 AI 科技评论对本次分享的全部整理。大家如果感兴趣可以点击阅读原文观看完整视频回放。
对了,我们招人了,了解一下?

CCF-GAIR 2018
(CCF 全球人工智能与机器人峰会)
将在 6 月底再次席卷鹏城
连续 3 天 11 场 分享盛宴
6.29 - 7.1,我们准时相约!

┏(^0^)┛欢迎分享,明天见!





