业界 | 腾讯论文入选Interspeech 2017:在单通道语音分离中应用的深度神经网路的训练优化
AI 科技评论按:2017年8月20日,语音通信领域的国际顶级学术会议Interspeech 2017在瑞典斯德哥尔摩召开,腾讯音视频实验室王燕南博士的一篇论文入选,并获邀在大会作了oral报告。
Interspeech是由国际语音通信协会ISCA(International Speech Communication Association)组织的语音研究领域的顶级会议之一,是全球最大的综合性语音信号处理领域的科技盛会,该会议每年举办一次,每次都会吸引全球语音信号领域以及人工智能领域知名学者、企业以及研发人员参加。
今年的Interspeech,除了学术界巨擘之外,苹果、谷歌、微软、亚马逊、腾讯、阿里巴巴、百度、滴滴等在内的国内外知名公司也悉数亮相。腾讯音视频实验室王燕南博士论文《A Maximum Likelihood Approach to Deep Neural Network Based Nonlinear Spectral Mapping for Single-Channel Speech Separation》入选 Interspeech 2017。
下图为历年Interspeech论文收录情况,过去三年收录文章的数量分别为614、746、779。
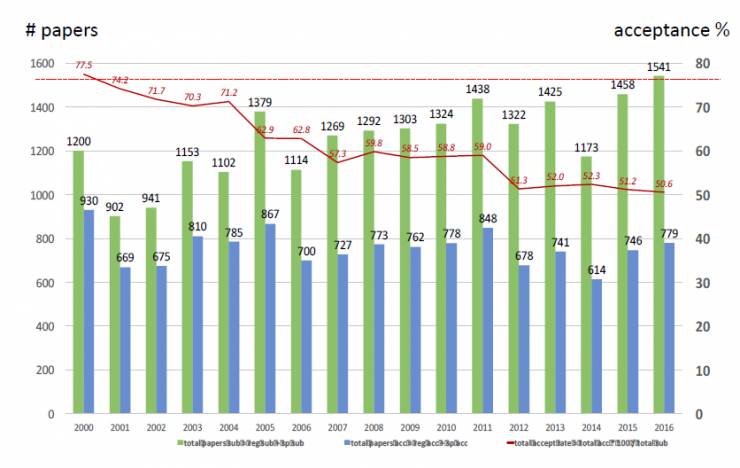
(数据来源:Interspeech 2016大会主办方欢迎报告)
王博士的论文主要内容是研究在单通道语音分离中应用的深度神经网路的训练优化,该技术旨在从混合的多个说话人的语音信号中分离出目标说话人的语音,在语音识别、语音通话以及残疾人助听领域等均具有重要应用。
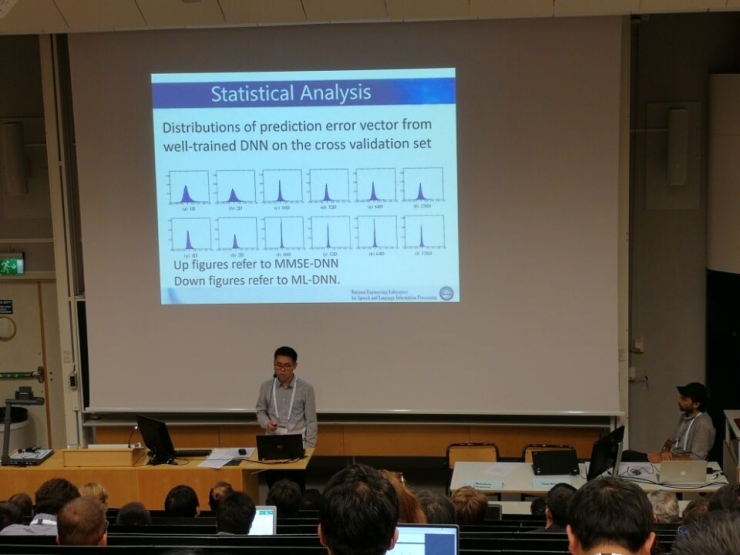
在这篇论文中,王博士的研究着重于改进单通道语音分离汇总基于深度神经网络的频谱映射方法中常用的最小均方误差准则(MMSE, minimum mean squared error)。在基于深度神经网络的单通道语音分离中,通过多类回归方法从混合语音频谱中恢复目标说话人的语音,主要是基于MMSE准则最小化网络输出的语音频谱和目标频谱的差异。对此,王博士等人通过对深度神经网络的输出的预测错误进行统计分析,发现输出的对数功率谱每一维分量都服从一个单峰分布,如下图所示:
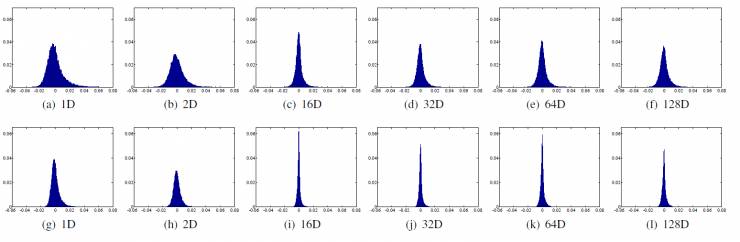
由此引入零均值的高斯分布函数来描述神经网络的预测错误矢量,引入对其进行概率分布的学习,从而使用最大似然估计方法训练深度神经网络的参数,如下图所示。
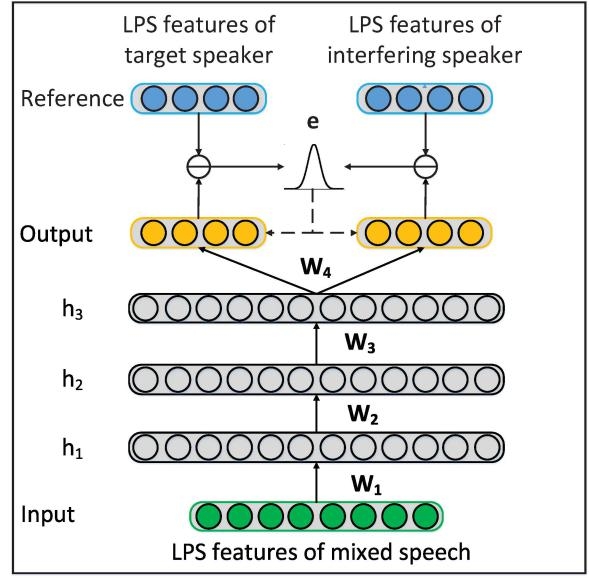
通过实验对比发现,基于该最大似然方法训练的神经网络分离的语音在不同的客观指标上均超过了使用传统的最小均方误差准则训练的神经网络。
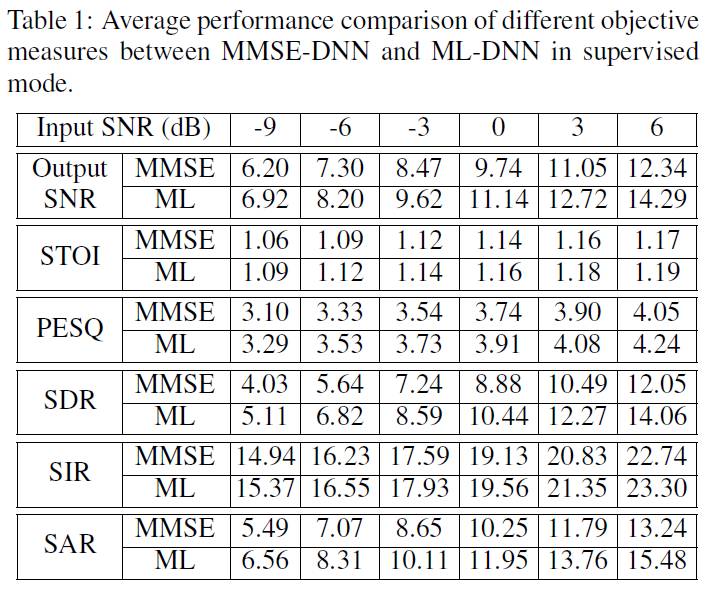
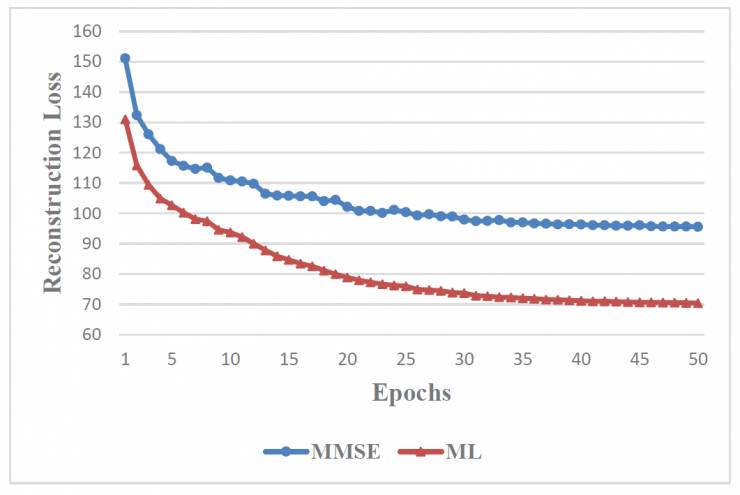
另外,通过在验证集上的reconstruction loss的变化情况对比,王博士等人发现该模型有更强的泛化能力,而在收敛速度上,该方法也具有明显的优势,对比情况如下图所示。
关于王燕南博士
王燕南,毕业于中国科学技术大学语音信号与信息处理国家工程实验室,研究领域包括语音增强和分离、语种识别、手写识别等,在Interspeech等著名语音国际会议以及IEEE Transaction on Audio,Speech and Language Processing期刊发表多篇文章,在无监督语音分离方法上做出了重要贡献。王博士于2017年加入腾讯音视频实验室,专注于语音增强以及分离等前端信号处理领域研究。
关于腾讯音视频实验室
腾讯音视频实验室, 组建于2016年11月,专注于音视频通信技术的前瞻性研究,包括全球实时音视频网络优化,音视频编解码前沿算法研究、计算机视觉图像处理、基于AI 的音频语音增强、声音美化及音视频质量评测等。
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————





