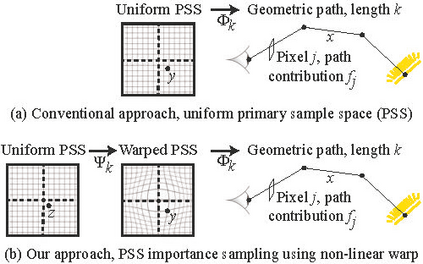
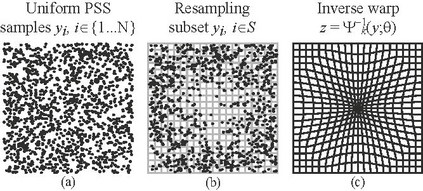
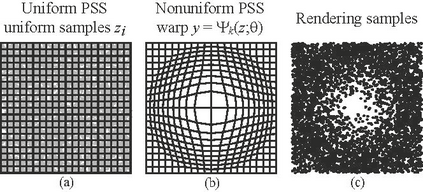
Importance sampling is one of the most widely used variance reduction strategies in Monte Carlo rendering. In this paper, we propose a novel importance sampling technique that uses a neural network to learn how to sample from a desired density represented by a set of samples. Our approach considers an existing Monte Carlo rendering algorithm as a black box. During a scene-dependent training phase, we learn to generate samples with a desired density in the primary sample space of the rendering algorithm using maximum likelihood estimation. We leverage a recent neural network architecture that was designed to represent real-valued non-volume preserving ('Real NVP') transformations in high dimensional spaces. We use Real NVP to non-linearly warp primary sample space and obtain desired densities. In addition, Real NVP efficiently computes the determinant of the Jacobian of the warp, which is required to implement the change of integration variables implied by the warp. A main advantage of our approach is that it is agnostic of underlying light transport effects, and can be combined with many existing rendering techniques by treating them as a black box. We show that our approach leads to effective variance reduction in several practical scenarios.
翻译:重要取样是蒙特卡洛( Monte Carlo) 制作中最广泛使用的减少差异策略之一。 在本文中, 我们提出一种新的重要取样技术, 使用神经网络学习如何从一组样本所代表的理想密度进行取样。 我们的方法将蒙特卡洛(Monte Carlo)的演化算法视为黑盒。 在以场景为依存的培训阶段, 我们学会利用最大可能性估计法的原始样本空间生成理想密度的样本。 我们的方法的主要优点是, 利用最近一个神经网络结构, 目的是代表高维空间中真实价值的非数量保护( “ Real NVP' ” ) 的转换。 我们用真实的 NVP 进行非线性主要取样空间的取样, 并获得理想的密度 。 此外, Real NVP 有效地计算了战争的雅各布( Jacoben) 的决定因素, 这是执行曲法所隐含的整合变量的变化所必需的。 我们的方法的主要优点是, 它能说明基本的轻量的迁移效果, 并且可以通过将它们作为黑盒来与许多现有的演算技术相结合。 我们展示我们的方法可以有效地减少几种实际设想中的差异。