谷歌和CMU论文解读:使用元学习生成伪标签
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者: bingo 来源: https://zhuanlan.zhihu.com/p/125478086 本文已由作者授权转载,未经允许,不得二次转载。
元学习是最近几年比较热门的研究问题,大家关注比较多的元学习应用主要是少样本学习(few-shot learning)和强化学习(RL)。今天我们介绍的论文,将元学习的框架直接用于标准的监督和半监督学习任务(CIFAR、ImageNet分类)。
预备知识
对于分类问题,我们通常要最小化模型预测分布(model distribution, )和目标分布(target distribution, )的交叉熵损失:
有监督训练以及半监督训练的一个核心问题,就是如何设计和使用合适的目标分布,现有的方法主要包括下面几种:
-
完全监督训练(fully supervised training)
也就是我们最常用的one-hot编码:
-
知识蒸馏(Knowledge distillation)
我们用一个更大的模型来引导小模型的学习:
-
半监督学习(semi-supervised learning)
典型的方式是先使用有限的标签数据学习一个模型 ,然后对无标签数据预测一个硬标签: 或者软标签
-
标签平滑(Label smoothing)
这是在大规模训练的时候防止过拟合的策略:
-
温度调节(Temperature Tuning)
在知识蒸馏和半监督学习以及很多其他应用(例如少样本学习)中,通过调节温度参数 来控制目标分布的平滑程度是一个常用策略:
算法思想
作者指出,所有上面的方法的关键是如何设计构造目标分布。但是不管怎么设计,目标分布策略通常都是事先固定的,不能够灵活自适应,所以本文提出了基于元学习自适应生成目标分布的方法,Meta Pseudo Labels(MPL) 。
MPL的主要思想如图1,按照正常的模型训练,那么梯度更新之后,会到到达蓝色的点(训练损失较小)。但是我们发现,在蓝色的点,验证集损失很大,所以这是一个比较坏的局部极小值。MPL的策略是通过验证集的损失来防止训练模型陷入这种比较坏的局部极小值。也就是说训练过程中,要考虑模型在验证集合上面的性能,防止过拟合训练集。
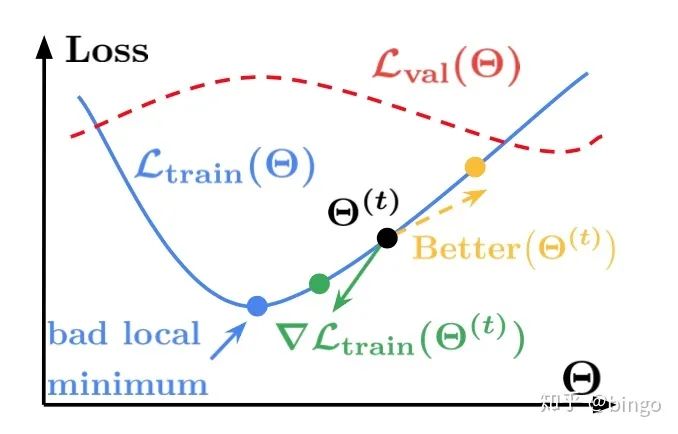
元伪标签算法

MPL方法采用了meta-learning的思想,所以和我们之前看到的少样本学习的经典算法,例如MAML非常像。如果对meta或者few-shot比较熟悉,那么理解本文会非常简单。MPL的具体更新过程如图2,包括两个部分:
-
Student 更新
模型通过Teacher得到伪标签数据,更新自己的权重参数(标准SGD更新):
-
Teacher 更新
利用验证数据 以及上一步更新之后的Student模型 ,产生梯度的梯度(前向计算, ),损失函数可以写成:
在更新Teacher模型的过程中, 会产生梯度的梯度,这个过程和meta-learning非常相似,也就是文章名字的来源。更具体的,优化过程可以写成下面的形式:
值得注意的是,这里的inner和outer和标准的meta的过程是一样的,区别的地方在于inner和outer更新的分别是不同的参数,而在few-shot的算法中(比如MAML),inner和outer会更新相同的参数。
设计细节
为了提升模型性能,作者在具体实现的过程中,在Teacher网络加入了直接的分类损失如图3.
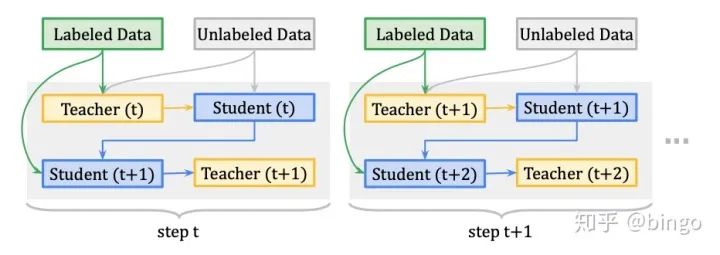
生的分类损失和元学习产生的损失两部分。
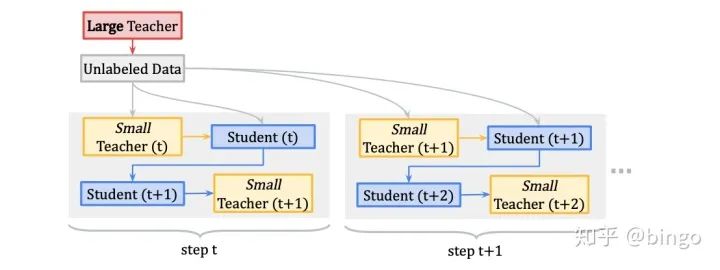
同时,因为元学习算法涉及到梯度的梯度,计算量通常会很大,不适合大规模网络和模型的学习,作者提出了一个简化版本的MPL算法,如图4. 首先学习一个大规模的Teacher网络用做基本网络,outer的meta更新的时候只更新一个小规模的Teacher网络,这样既保证了一定的性能,又大大的减少了计算量。
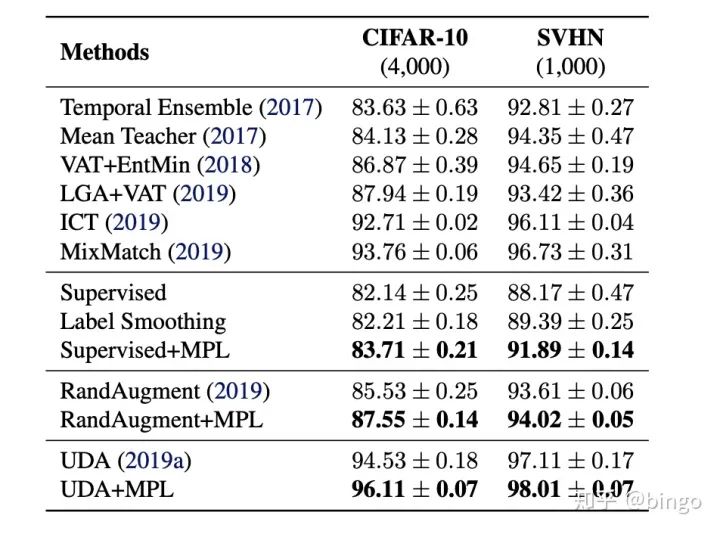
实验结果
数据集:CIFAR10,SVHN和ImageNet-10%。
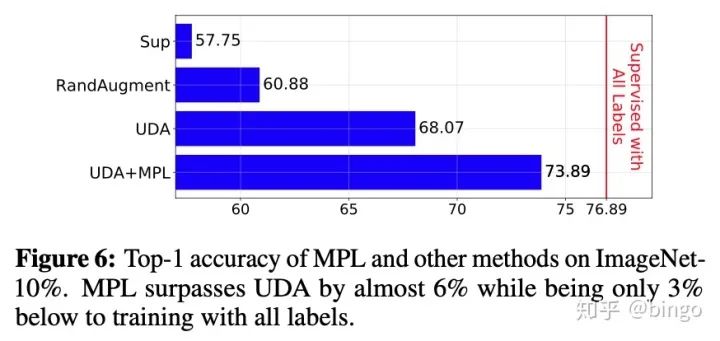
结果如图5和图6,具体细节请参考原始论文。
总结
对于分类问题,如何产生合适的目标分布,对于深度学习的过程以及泛化能力都至关重要。之前的方法大多采用固定的策略通过不同网络、平滑或者温度参数产生目标分布。本文作者提出通过考虑验证集合性能和元学习来自适应的生成目标分布。
相关论文:
Pham, Hieu, et al. "Meta Pseudo Labels."arXiv preprint arXiv:2003.10580(2020)

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



