元学习(Meta-Learning) 综述及五篇顶会论文推荐
【导读】Meta Learning 元学习或者叫做 Learning to Learn 学会学习是当下研究热点。专知整理了近期关于元学习的综述及2019年五篇顶会论文, 欢迎查看!

【元学习综述及推送论文便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“元学习”就可以获取《元学习(Meta-Learning) 综述及五篇顶会论文推荐》的论文下载链接~
元学习综述

元学习,或学习学习,是一门系统地观察不同机器学习方法如何在广泛的学习任务中执行的科学,然后从这种经验或元数据中学习,以比其他方法更快的速度学习新任务。这不仅极大地加快和改进了机器学习管道或神经体系结构的设计,还允许我们用以数据驱动方式学习的新方法取代手工设计的算法。在本文中,我们将概述这一迷人且不断发展的领域的最新进展。
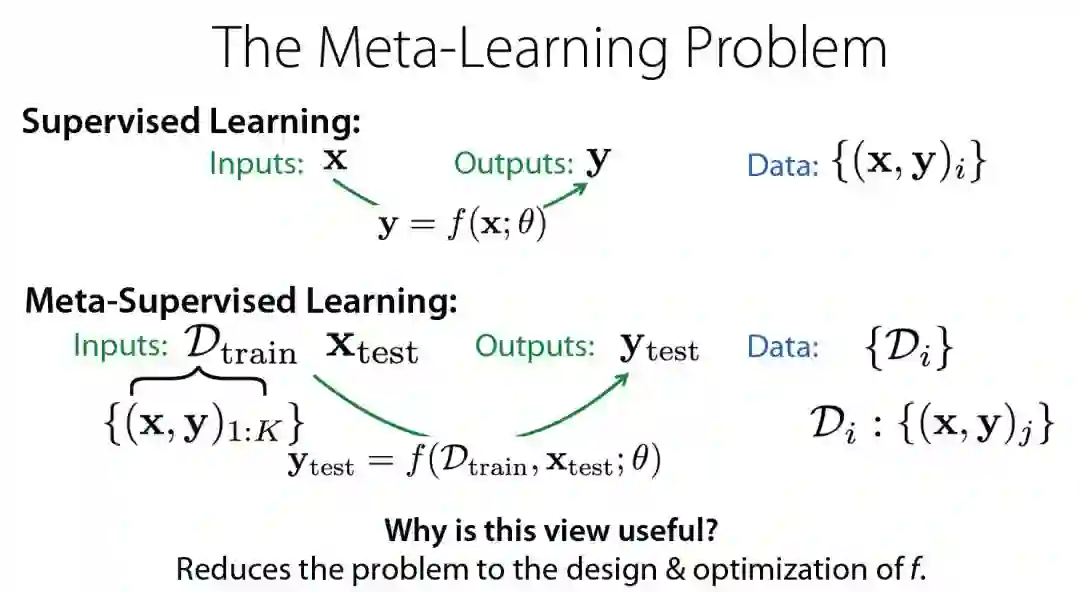
Meta-Learning: A Survey. Joaquin Vanschoren.
Chapter 2: Meta Learning [bibtex]. By Joaquin Vanschoren
论文地址:
http://www.zhuanzhi.ai/paper/dd60eaffea966331e199fa531bae7044
元学习究竟是什么?这《基于梯度的元学习》199页伯克利博士论文带你回顾元学习最新发展脉络
五篇元学习论文推荐
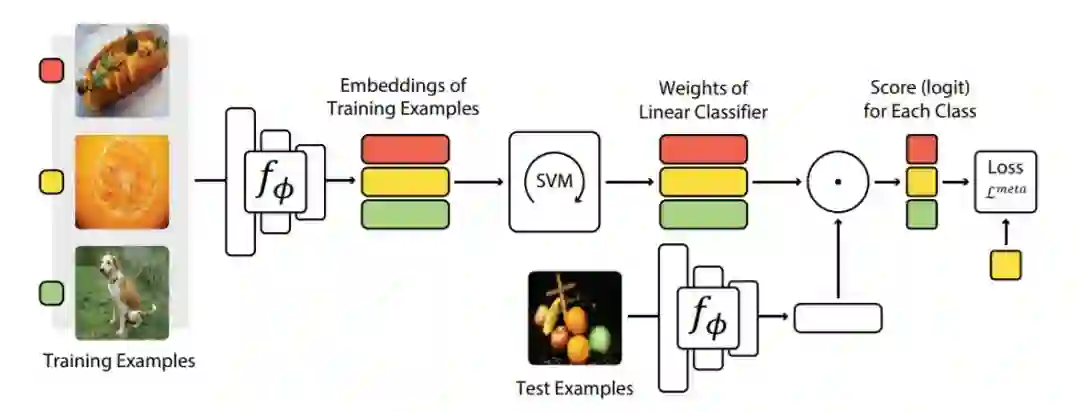
微分凸优化元学习 ,CVPR 2019 Oral

许多元学习方法对于小样本学习依赖于简单基础学习器,如最近邻分类器。然而,即使在小样本的情况下,经过判别式训练的线性预测器也能提供更好的泛化效果。我们建议使用这些预测器作为基础学习器来学习用于小样本学习的表示,并表明它们在一系列小样本识别基准测试中提供了更好的特征大小和性能之间的权衡。我们的目标是学习新的类别在线性分类规则下很好概括的特征嵌入。为了有效地解决这一问题,我们利用线性分类器的两个性质:凸问题最优性条件的隐微分和优化问题的对偶公式。这使我们能够使用高维嵌入,并在适当增加计算开销的情况下改进泛化。我们的方法名为MetaOptNet,在miniImageNet、tieredImageNet、CIFAR-FS和FC100小样本学习基准数据集上取得了最先进的性能
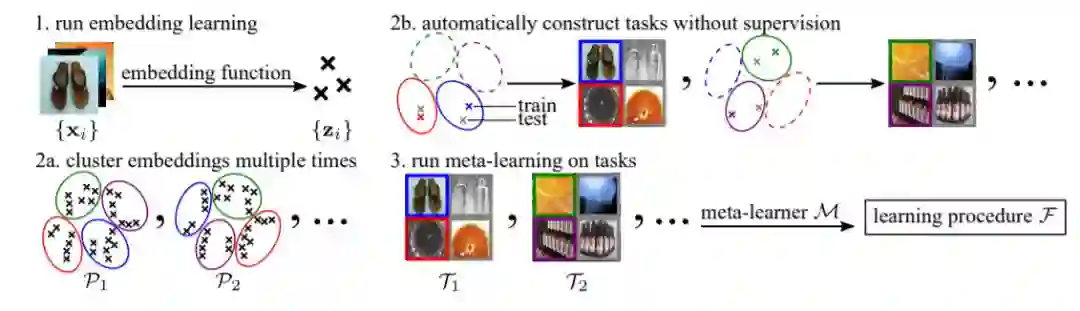
2. 无监督元学习,ICLR 2019

无监督学习的一个核心目标是从无标记数据或经验中获取表示,这些数据或经验可用于从少量标记数据中更有效地学习下游任务。以前的许多无监督学习工作都是通过开发基于重构、解缠、预测和其他度量的代理目标来实现的。相反,我们开发了一种无监督元学习方法,它显式地优化了从少量数据学习各种任务的能力。为此,我们以自动的方式从未标记的数据构造任务,并在构造的任务上运行元学习。令人惊讶的是,我们发现,当与元学习集成时,相对简单的任务构建机制,例如集群嵌入,可以在各种下游的、由人类指定的任务上获得良好的性能。我们对四个图像数据集的实验表明,我们的无监督元学习方法获得了一种没有任何标记数据的学习算法,适用于广泛的下游分类任务,改进了之前四种无监督学习方法学习的嵌入。
3. 在线元学习

智能系统的一个核心能力是能够不断地建立在以前的经验之上,以加快和加强对新任务的学习。两种不同的研究范式研究了这个问题。元学习将此问题视为在模型参数之上学习优先级,模型参数能够快速适应新任务,但通常假设一组任务作为批处理一起可用。相比之下,在线学习考虑的是一个连续的环境,在这个环境中,问题一个接一个地暴露出来,但传统上只训练一个模型,没有任何特定于任务的适应性。这项工作引入了一个在线元学习设置,它融合了上述两种范式的思想,以更好地捕捉持续终生学习的精神和实践。我们提出了遵循元领导算法,将MAML算法扩展到该设置。理论上,这项工作提供了一个O(logT)遗憾保证,与标准的在线设置相比,只有一个额外的高阶平滑度假设。我们对三种不同大规模任务的实验评估表明,该算法的性能显著优于传统在线学习方法。
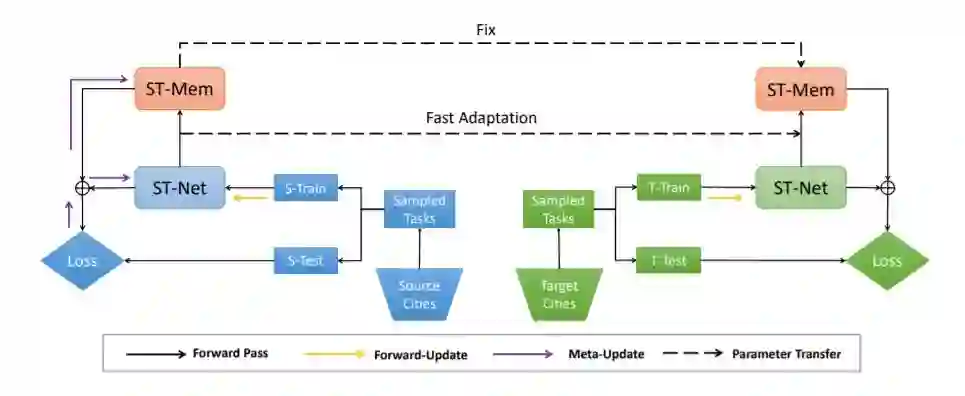
4. 多城市学习:时空预测的元学习方法,WWW2019

时空预测是构建智能城市的基础问题,对于交通控制、出租车调度、环境政策制定等任务具有重要意义。由于数据采集机制的原因,经常会出现空间分布不平衡的数据采集。例如,一些城市可能会发布多年的出租车数据,而另一些城市只发布几天的数据;有些区域可能有由传感器监测的恒定水质数据,而有些区域只有少量的水样。在本文中,我们解决了数据采集周期较短的城市时空预测问题。我们的目标是通过迁移学习利用其他城市的长期数据。不同于以往将知识从单一来源城市转移到目标城市的研究,我们是第一个利用多个城市的信息来增加转移的稳定性。具体地说,我们提出的模型被设计成一个具有元学习范式的时空网络。元学习范式学习时空网络的广义初始化,能够有效地适应目标城市。此外,还设计了一种基于模式的时空记忆,用于提取长期的时间信息。,周期性)。我们对两项任务进行了广泛的实验:交通(出租车和自行车)预测和水质预测。实验结果表明,该模型在多个竞争基准模型上的有效性。
5. 通过元学习进行图神经网络对抗攻击,ICLR 2019

图深度学习模型已经在许多任务上提高了性能。尽管它们最近取得了成功,但人们对它们的健壮性知之甚少。我们研究了基于图神经网络的节点分类训练时间攻击对离散图结构的影响。我们的核心原则是使用元梯度来解决底层训练时间攻击的二层问题,本质上是将图作为要优化的超参数。我们的实验表明,图的小扰动始终导致图卷积网络性能的大幅下降,甚至转移到无监督嵌入。值得注意的是,我们的算法产生的扰动会误导图神经网络,使它们的性能比忽略所有关系信息的简单基线差。我们的攻击不假定对目标分类器有任何知识或访问权限。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!530+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程





