5 篇论文详解 Learning with Noisy Label:深度学习廉价落地
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:JackonYang
知乎链接:https://zhuanlan.zhihu.com/p/110959020
本文已由作者授权转载,未经允许,不得二次转载。
阅读背景
有一定量的标注数据。-- 通过搜索引擎、公开数据集等,很容易拿到。
标注数据的质量不高,存在或高或低的标注错误。
初始阶段有一定量的标注质量未知的数据。
一般会有持续的人工投入,不断提升标注质量。人工投入的形式,可能是付费众包,可能是借助用户反馈。
对某些 label、某些错误的关注度,高于其他,需要针对性的优化。
总体观点
直接用概率论模型去识别,比如基于 EM 算法的模型、置信学习模型等。
根据模型预测的 loss 粗选,反复迭代。
隐式的,模型自身对 noise 的容忍度更高。核心思路是改成 weighted sum loss,noisy 的权重低,clean 的权重高。问题转化为如何找 weight。
理论基础类
Paper【1】: Understanding deep learning requires rethinking generalization -- 2017
https://arxiv.org/abs/1611.03530
Chiyuan Zhang, Samy Bengio
2017
阅读价值:高
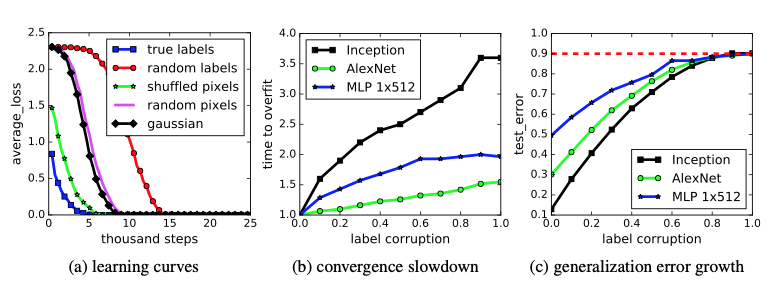
用真实的数据,label 改为随机生成。
model 使用标准模型,不加任何修改。
训练的效果:training error = 0,test error 与随机选的结果相同。
因为 test label 也是完全随机生成的,无法预测。test error 符合预期。
training error = 0,模型参数多,有能力记住所有 dataset 点。
随机数据导致模型的 generalization error 明显增加了。
基于原始真实数据集,label 不变,image pixel 改成全随机,依旧可以 0 training error
用 random + 原始数据混合测试,random 比例提升,generalization 错误率提升。说明,在 random data 混淆的情况下,依旧有能力学到部分真实特征。
regularization 能降低 testing error,但对 generalization error 影响不直接。
dropout
weight decay
Paper【2】: Convexity, Classification, and Risk Bounds
https://www.stat.berkeley.edu/~jordan/638.pdf
Bartlett
2006
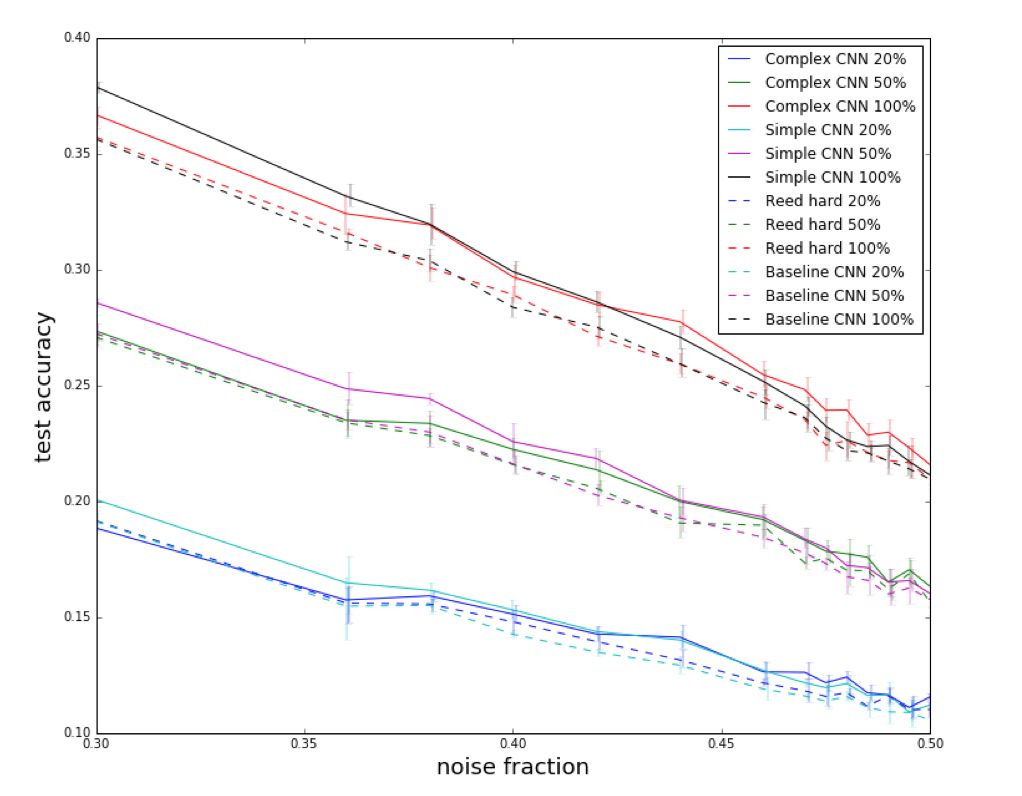
基于概率模型(estimate noisy label)
noise 与 label 有关,狮子容易被分类成猫,但不容易被分类为轮船。
找 noisy label 和 true label 之间联合概率分布矩阵、转移矩阵。
用概率矩阵识别 clean label 或 noise label,修正数据集。
Paper【1】: Training deep neural-networks using a noise adaptation layer -- 2017
https://openreview.net/references/pdf?id=Sk5qglwSl
Jacob Goldberger
2017
阅读价值:高
The correct unknown label can be viewed as a hidden random variable
Model the noise processes by a communication channel with unknown parameters.
E-step, estimate the true label
M-step, retrain the network
改模型可以扩展到 the case where the noise is dependent on both the correct label and the input features.
适用于 noisy distribution 未知的数据集。
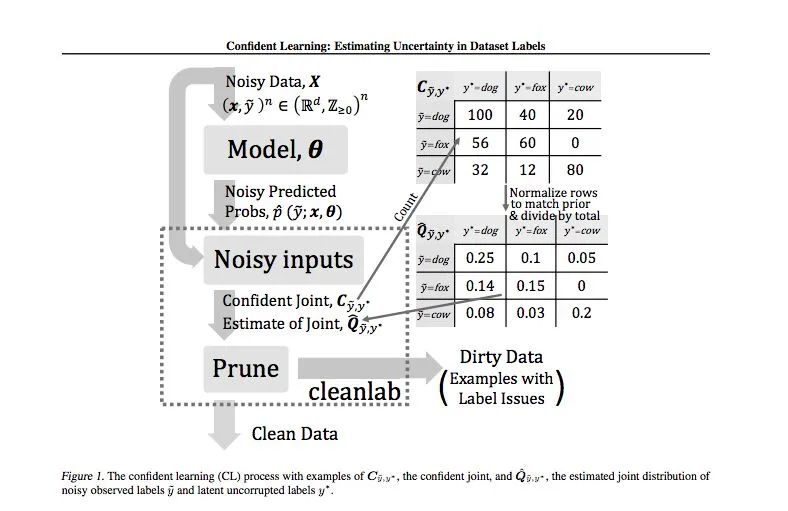
Paper【2】: Confident Learning: Estimating Uncertainty in Dataset Labels -- 2019
https://arxiv.org/abs/1911.00068
Curtis G. Northcutt
2019
阅读价值:高
通过 prune, count, rank 3 步可以高效率算出 joint probabilities(true and predicted labels)
根据 joint probabilities 识别 label error。
迭代的学习
包含curriculum learning, semi-supervised learning, co-training, self-training。这种模型太多了,大同小异。
先用大量/全部数据 training 一个 model。
根据 loss 等参数,选出大概率为 true 的 label。
用 true label 重新或继续 training model。
重复 2-3 步。
curriculum learning 一次把 dataset 分成 N 组,从易到难的训练。其他大方法,大多每次只选出最简单的 1 组。
重复 training 的时候,学习的目标能否更复杂(全面)一点,把上一轮学到的参数也纳入新模型的学习目标里。
Paper【1】: MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels -- 2018
https://arxiv.org/abs/1712.05055
Lu Jiang, Li Fei-Fei
2018
阅读价值:高
code: https://github.com/google/mentornet
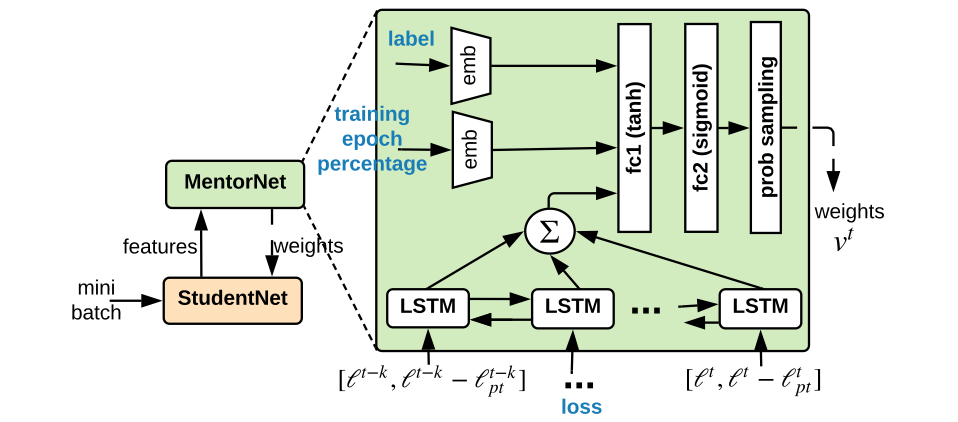
自动学习 data-driven 课程。MentorNet learns a data-driven curriculum to supervise the base deep CNN, naely StudentNet.
根据 StudentNet 的反馈,更新 Curriculum。
w 就是一般 CNN 要学习的权重。
lambda 是超参数,表示学习难度。
v 是 curriculum learning 引入的权重, v_i < lambda, 表示第 i 条数据 "easy",参与本次训练。

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~






